---
title: "Chapter 17: 貝氏統計 (Bayesian Statistics)"
---
```{r}
#| include: false
source(here::here("R/_common.R"))
```
## 學習目標 {.unnumbered}
- 理解貝氏定理的連續版本與積分的關係
- 掌握 Prior × Likelihood ∝ Posterior 的數學原理
- 了解共軛先驗 (conjugate prior) 的微積分基礎
- 視覺化 Prior 到 Posterior 的更新過程
- 連結貝氏統計與微積分概念
## 概念說明 {#sec-bayesian}
### 什麼是貝氏統計?
在傳統的頻率統計 (frequentist statistics) 中,我們把參數視為**固定但未知的常數**。例如:「某藥物的真實療效是 θ,我們用樣本資料估計它」。
但貝氏統計 (Bayesian statistics) 有不同的觀點:參數不是常數,而是**有不確定性的隨機變數**。我們用**機率分布**來描述這種不確定性[@gelman2013bayesian; @mcelreath2020statistical]。
### 醫學情境的例子
假設你是急診醫師,看到一位胸痛病人:
- **Prior(先驗)**:根據年齡、性別、病史,你心中已有初步判斷:「這個人心肌梗塞的機率大概 20%」
- **Likelihood(似然)**:做了心電圖,發現 ST 段上升(強烈證據!)
- **Posterior(後驗)**:結合先驗判斷與新證據,更新為:「現在心肌梗塞的機率上升到 85%」
這就是貝氏推論的核心:**用新資料更新你的信念**。
### 為什麼需要微積分?
當參數是連續的(例如血壓、存活時間、療效),我們需要用**機率密度函數** (PDF) 來描述不確定性。這就需要積分來計算機率。
**貝氏定理的連續版本**:
$$p(\theta \mid \text{data}) = \frac{p(\text{data} \mid \theta) \cdot p(\theta)}{p(\text{data})}$$
其中分母是積分:
$$p(\text{data}) = \int p(\text{data} \mid \theta) \cdot p(\theta) \, d\theta$$
這個積分通常很難算,是貝氏統計的主要挑戰之一!
## 視覺化理解
### 貝氏定理的連續版本
**離散版本**(你可能學過的):
$$P(A \mid B) = \frac{P(B \mid A) \cdot P(A)}{P(B)}$$
**連續版本**(參數 θ 是連續的):
$$p(\theta \mid x) = \frac{p(x \mid \theta) \cdot p(\theta)}{p(x)}$$
用統計學的術語改寫:
$$\underbrace{p(\theta \mid x)}_{\text{Posterior}} = \frac{\overbrace{p(x \mid \theta)}^{\text{Likelihood}} \times \overbrace{p(\theta)}^{\text{Prior}}}{\underbrace{\int p(x \mid \theta) \cdot p(\theta) \, d\theta}_{\text{Normalizing constant}}}$$
**簡化寫法**(忽略分母,因為它只是正規化常數):
$$p(\theta \mid x) \propto p(x \mid \theta) \cdot p(\theta)$$
讀作:「Posterior 正比於 Likelihood 乘以 Prior」
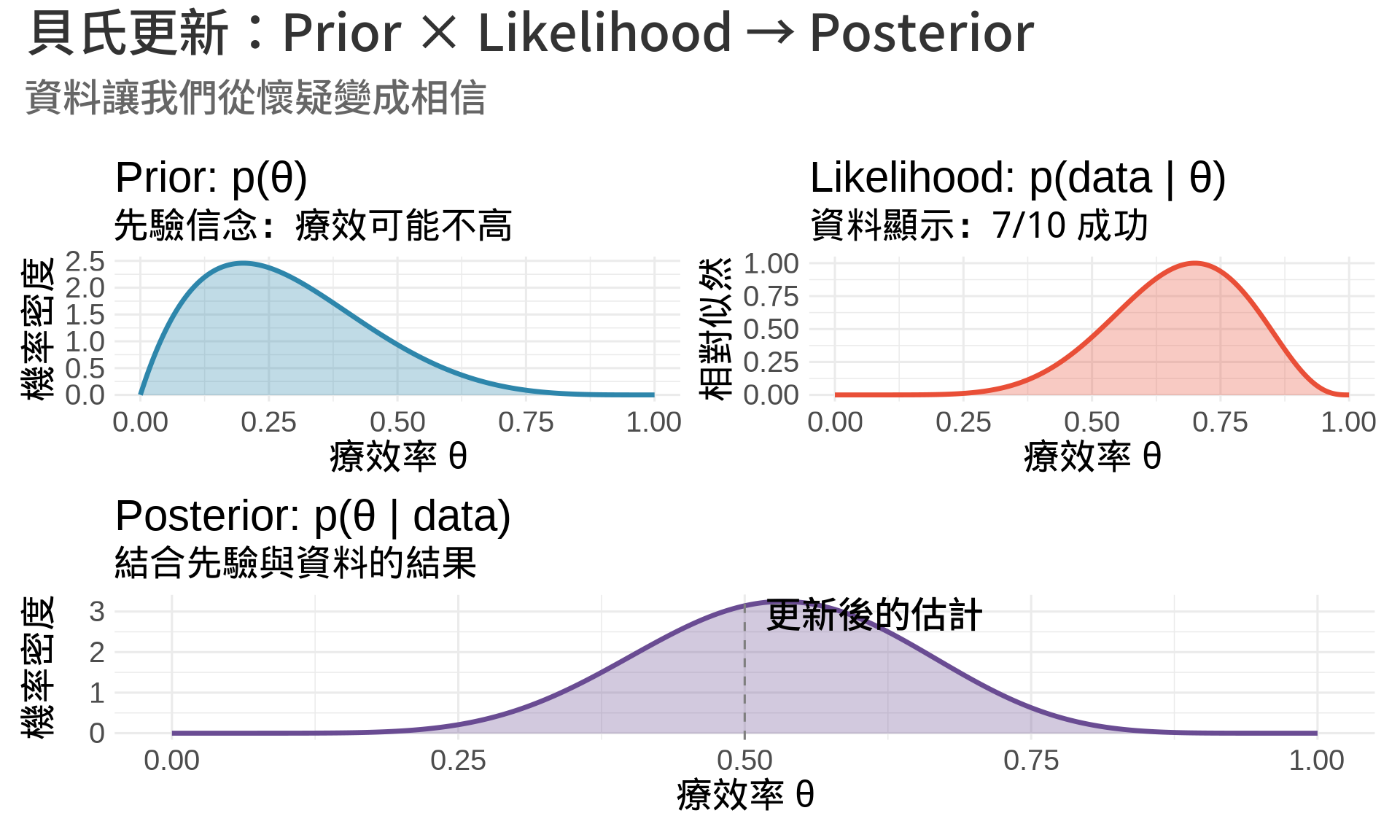
### Prior, Likelihood, Posterior 的視覺化
```{r}
#| label: fig-bayesian-basic
#| fig-cap: "貝氏更新的基本概念"
#| warning: false
#| message: false
# 假設我們要估計成功率 p(例如:新藥的療效率)
# Prior: Beta(2, 5) - 先驗認為療效不高
# Data: 觀察 10 次,成功 7 次
# Posterior: Beta(2+7, 5+3) = Beta(9, 8)
theta <- seq(0, 1, by = 0.001)
# Prior: Beta(2, 5)
prior <- dbeta(theta, 2, 5)
# Likelihood: Binomial(7 successes out of 10)
# p(data | theta) ∝ theta^7 * (1-theta)^3
likelihood <- theta^7 * (1 - theta)^3
likelihood <- likelihood / max(likelihood) # 正規化以便視覺化
# Posterior: Beta(9, 8)
posterior <- dbeta(theta, 9, 8)
df <- data.frame(theta, prior, likelihood, posterior)
# Prior
p1 <- ggplot(df, aes(theta, prior)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
geom_area(fill = "#2E86AB", alpha = 0.3) +
labs(
title = "Prior: p(θ)",
subtitle = "先驗信念:療效可能不高",
x = "療效率 θ",
y = "機率密度"
) +
theme_minimal(base_size = 12)
# Likelihood
p2 <- ggplot(df, aes(theta, likelihood)) +
geom_line(color = "#E94F37", linewidth = 1.2) +
geom_area(fill = "#E94F37", alpha = 0.3) +
labs(
title = "Likelihood: p(data | θ)",
subtitle = "資料顯示:7/10 成功",
x = "療效率 θ",
y = "相對似然"
) +
theme_minimal(base_size = 12)
# Posterior
p3 <- ggplot(df, aes(theta, posterior)) +
geom_line(color = "#6A4C93", linewidth = 1.2) +
geom_area(fill = "#6A4C93", alpha = 0.3) +
geom_vline(xintercept = 0.5, linetype = "dashed", color = "gray50") +
annotate("text", x = 0.5, y = max(posterior) * 0.9,
label = "更新後的估計", hjust = -0.1) +
labs(
title = "Posterior: p(θ | data)",
subtitle = "結合先驗與資料的結果",
x = "療效率 θ",
y = "機率密度"
) +
theme_minimal(base_size = 12)
(p1 | p2) / p3 +
plot_annotation(
title = "貝氏更新:Prior × Likelihood → Posterior",
subtitle = "資料讓我們從懷疑變成相信"
)
```
**關鍵觀察**:
1. **Prior** 集中在低值(我們原本不太相信療效高)
2. **Likelihood** 集中在高值(資料顯示 70% 成功率)
3. **Posterior** 是兩者的折衷(更新後的信念)
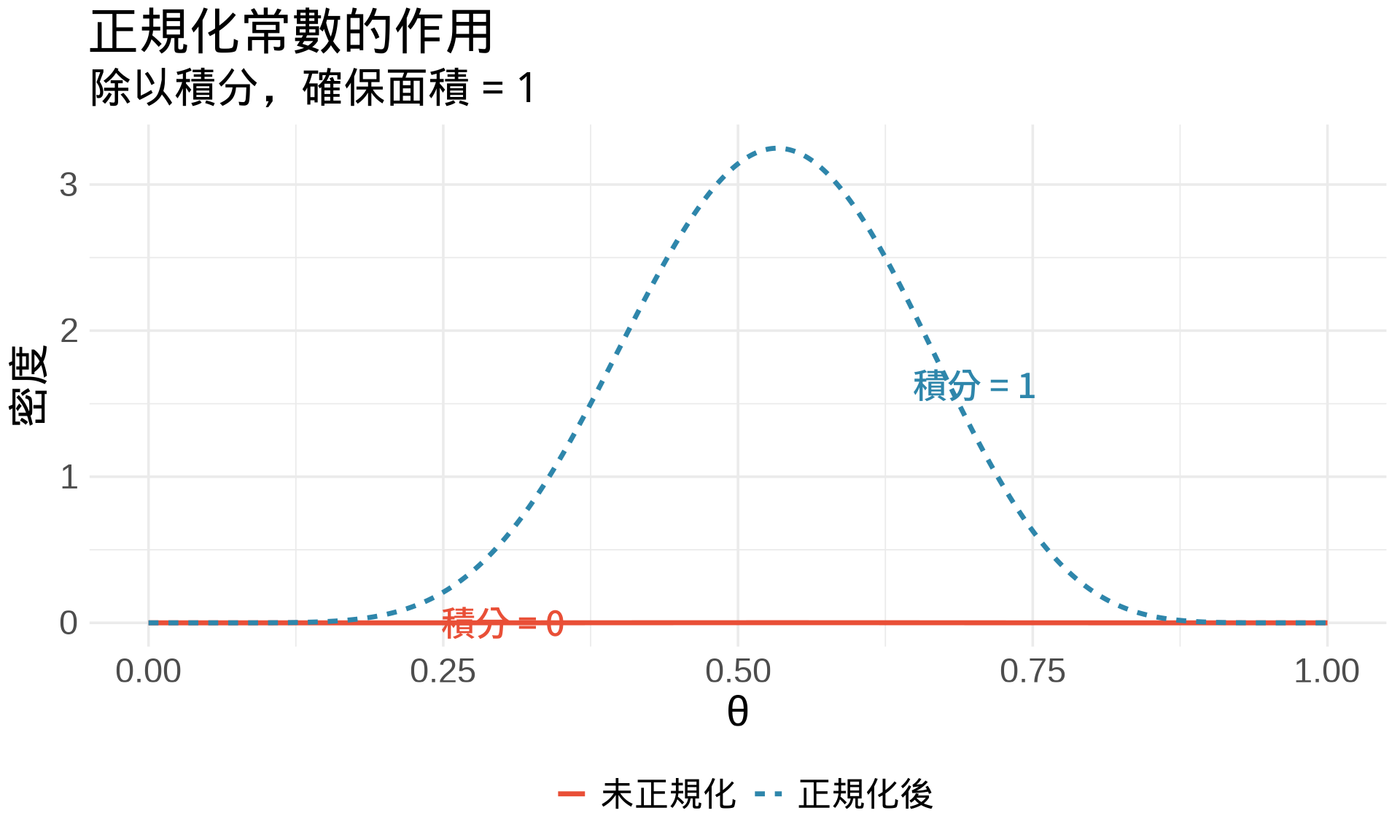
### 積分的角色:正規化常數
Posterior 的分母是積分:
$$p(x) = \int_{\Theta} p(x \mid \theta) \cdot p(\theta) \, d\theta$$
這個積分的作用是**確保 posterior 是合法的機率密度函數**(面積 = 1)。
```{r}
#| label: fig-normalization
#| fig-cap: "正規化常數的作用"
#| warning: false
#| message: false
theta <- seq(0, 1, by = 0.001)
# 未正規化的 posterior(只是 prior × likelihood)
unnormalized <- dbeta(theta, 2, 5) * theta^7 * (1 - theta)^3
# 計算積分(用數值方法)
normalizing_constant <- sum(unnormalized) * 0.001 # Riemann sum
# 正規化後的 posterior
normalized <- unnormalized / normalizing_constant
df <- data.frame(
theta = rep(theta, 2),
density = c(unnormalized, normalized),
type = rep(c("未正規化", "正規化後"), each = length(theta))
)
ggplot(df, aes(theta, density, color = type, linetype = type)) +
geom_line(linewidth = 1.2) +
scale_color_manual(values = c("#E94F37", "#2E86AB")) +
annotate("text", x = 0.3, y = max(unnormalized) * 0.5,
label = paste0("積分 = ", round(normalizing_constant, 2)),
size = 4, color = "#E94F37") +
annotate("text", x = 0.7, y = max(normalized) * 0.5,
label = "積分 = 1",
size = 4, color = "#2E86AB") +
labs(
title = "正規化常數的作用",
subtitle = "除以積分,確保面積 = 1",
x = "θ",
y = "密度",
color = "",
linetype = ""
) +
theme_minimal(base_size = 14) +
theme(legend.position = "bottom")
```
## 數學定義
### 貝氏定理(連續版本)
**定理**:給定觀察資料 $x$ 和參數 $\theta$,參數的後驗分布為:
$$p(\theta \mid x) = \frac{p(x \mid \theta) \cdot p(\theta)}{\int_{\Theta} p(x \mid \theta) \cdot p(\theta) \, d\theta}$$
**符號說明**:
- $p(\theta)$:Prior distribution(先驗分布)
- $p(x \mid \theta)$:Likelihood(似然函數)
- $p(\theta \mid x)$:Posterior distribution(後驗分布)
- $p(x) = \int p(x \mid \theta) \cdot p(\theta) \, d\theta$:Marginal likelihood(邊際似然)
**比例形式**:
$$p(\theta \mid x) \propto p(x \mid \theta) \cdot p(\theta)$$
這個形式告訴我們:**只要知道 likelihood 和 prior 的函數形式,就能推導出 posterior 的形式**(差一個正規化常數)。
### 共軛先驗 (Conjugate Prior)
**定義**:如果 prior 和 posterior 屬於**同一個分布族**,則稱該 prior 為該 likelihood 的共軛先驗。
**為什麼重要**?
- 數學上優美:prior 和 posterior 有相同形式
- 計算上簡單:積分可以直接算出來(不需數值方法)
- 直觀上清晰:更新規則很直接
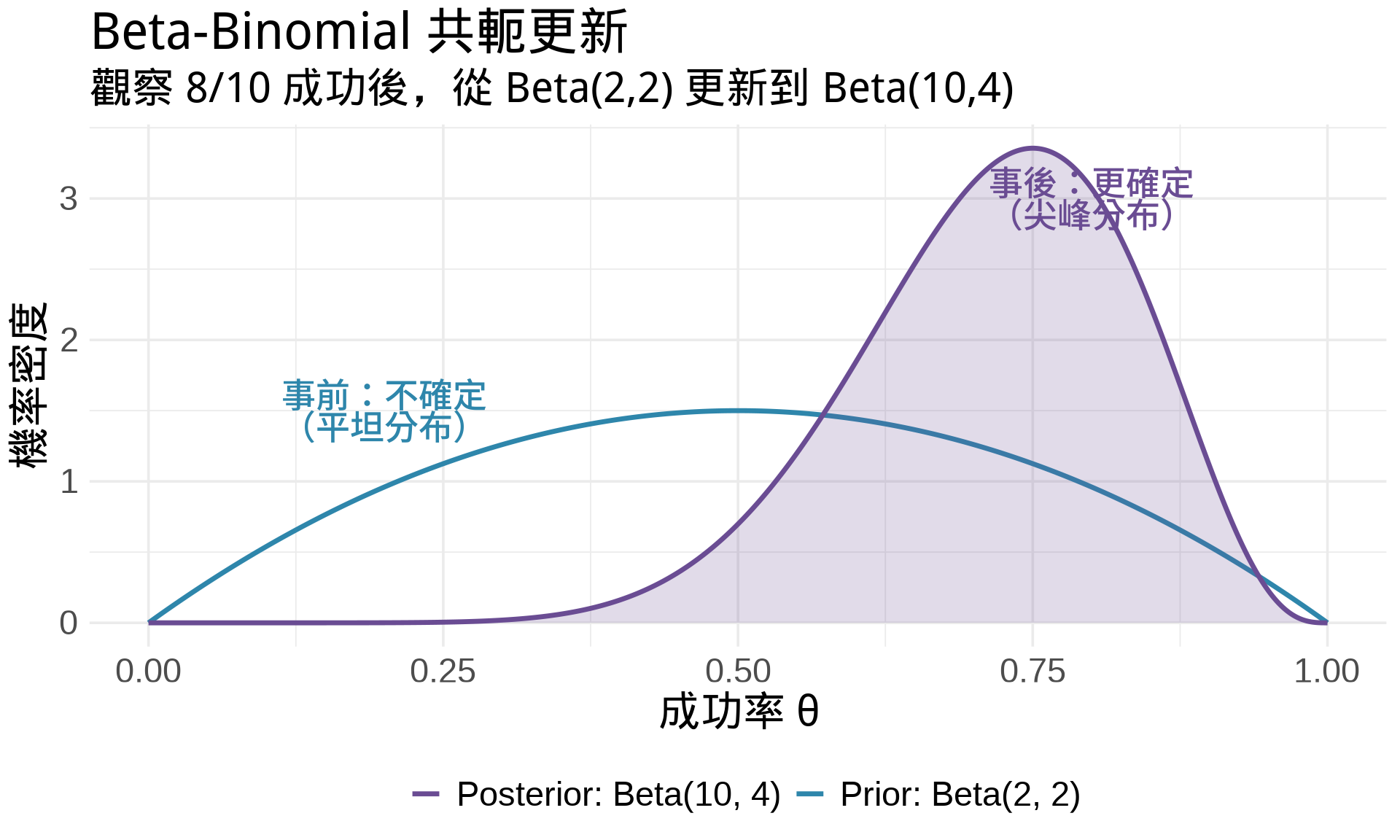
### Beta-Binomial 共軛族
這是最經典的共軛先驗例子。
**設定**:
- 參數:成功率 $\theta \in [0, 1]$
- Prior:$\theta \sim \text{Beta}(\alpha, \beta)$
- Data:$n$ 次試驗中觀察到 $k$ 次成功,$\text{Binomial}(n, \theta)$
**Prior 的 PDF**:
$$p(\theta) = \frac{\Gamma(\alpha + \beta)}{\Gamma(\alpha)\Gamma(\beta)} \theta^{\alpha-1}(1-\theta)^{\beta-1}$$
**Likelihood**:
$$p(k \mid \theta, n) = \binom{n}{k} \theta^k (1-\theta)^{n-k}$$
**Posterior 推導**(這裡是微積分的精華!):
$$\begin{align}
p(\theta \mid k, n) &\propto p(k \mid \theta, n) \cdot p(\theta) \\
&\propto \theta^k (1-\theta)^{n-k} \cdot \theta^{\alpha-1}(1-\theta)^{\beta-1} \\
&= \theta^{k+\alpha-1} (1-\theta)^{n-k+\beta-1}
\end{align}$$
這正好是 $\text{Beta}(k+\alpha, n-k+\beta)$ 的 kernel(核心)!
**結論**:
$$\text{Prior: Beta}(\alpha, \beta) + \text{Data: } k \text{ successes in } n \text{ trials} \Rightarrow \text{Posterior: Beta}(\alpha+k, \beta+n-k)$$
**更新規則的直觀**:
- $\alpha$:可視為「事前的成功次數」
- $\beta$:可視為「事前的失敗次數」
- 新資料只是把成功和失敗**累加**上去!
```{r}
#| label: fig-beta-conjugacy
#| fig-cap: "Beta-Binomial 共軛更新的數學原理"
#| warning: false
#| message: false
theta <- seq(0, 1, by = 0.001)
# 展示更新過程
alpha_prior <- 2
beta_prior <- 2
k <- 8 # 成功次數
n <- 10 # 總試驗次數
prior <- dbeta(theta, alpha_prior, beta_prior)
posterior <- dbeta(theta, alpha_prior + k, beta_prior + (n - k))
df <- data.frame(theta, prior, posterior)
ggplot(df) +
geom_line(aes(theta, prior, color = "Prior: Beta(2, 2)"),
linewidth = 1.2) +
geom_line(aes(theta, posterior, color = "Posterior: Beta(10, 4)"),
linewidth = 1.2) +
geom_area(aes(theta, posterior), fill = "#6A4C93", alpha = 0.2) +
scale_color_manual(
values = c("Prior: Beta(2, 2)" = "#2E86AB",
"Posterior: Beta(10, 4)" = "#6A4C93")
) +
annotate("text", x = 0.2, y = 1.5,
label = "事前:不確定\n(平坦分布)",
color = "#2E86AB", size = 4) +
annotate("text", x = 0.8, y = 3,
label = "事後:更確定\n(尖峰分布)",
color = "#6A4C93", size = 4) +
labs(
title = "Beta-Binomial 共軛更新",
subtitle = "觀察 8/10 成功後,從 Beta(2,2) 更新到 Beta(10,4)",
x = "成功率 θ",
y = "機率密度",
color = ""
) +
theme_minimal(base_size = 14) +
theme(legend.position = "bottom")
```
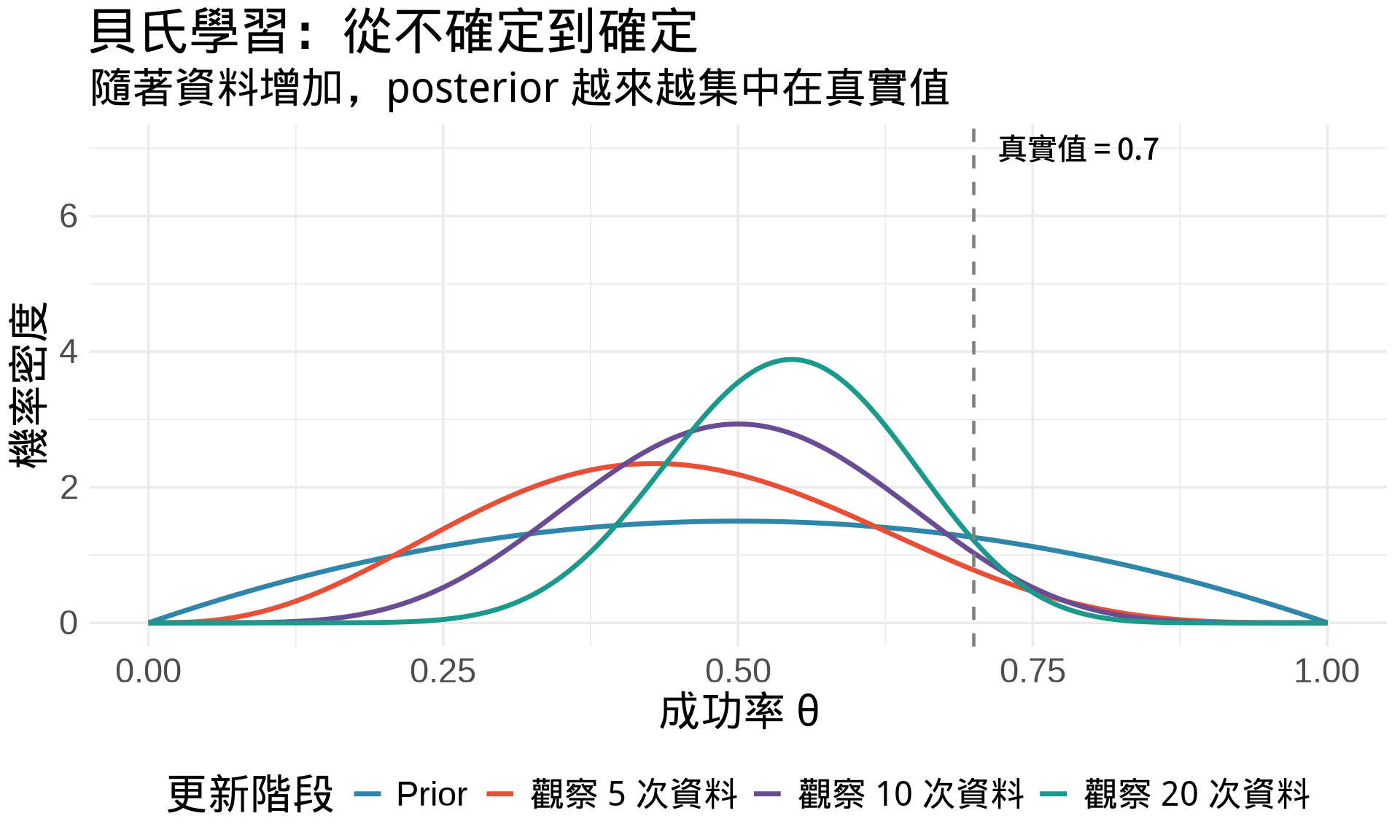
## Prior → Posterior 更新過程的動態視覺化
讓我們用動態方式展示:隨著觀察更多資料,posterior 如何逐步更新。
```{r}
#| label: fig-sequential-update
#| fig-cap: "逐筆資料更新的過程"
#| warning: false
#| message: false
library(dplyr)
theta <- seq(0, 1, by = 0.001)
# 初始 prior
alpha <- 2
beta <- 2
# 模擬逐次觀察資料(1 代表成功,0 代表失敗)
set.seed(42)
observations <- rbinom(20, 1, 0.7) # 真實成功率是 0.7
# 計算每次觀察後的 posterior
update_history <- list()
for (i in 0:20) {
if (i == 0) {
current_alpha <- alpha
current_beta <- beta
label <- "Prior"
} else {
current_alpha <- alpha + sum(observations[1:i])
current_beta <- beta + i - sum(observations[1:i])
label <- paste0("觀察 ", i, " 次資料")
}
update_history[[i+1]] <- data.frame(
theta = theta,
density = dbeta(theta, current_alpha, current_beta),
stage = label,
n_obs = i
)
}
df_updates <- bind_rows(update_history)
# 選擇幾個關鍵時間點展示
key_stages <- c(0, 5, 10, 20)
df_key <- df_updates %>% filter(n_obs %in% key_stages)
df_key$stage <- factor(
df_key$stage,
levels = c("Prior", "觀察 5 次資料", "觀察 10 次資料", "觀察 20 次資料")
)
ggplot(df_key, aes(theta, density, color = stage)) +
geom_line(linewidth = 1.2) +
scale_color_manual(
values = c("#2E86AB", "#E94F37", "#6A4C93", "#1B998B")
) +
geom_vline(xintercept = 0.7, linetype = "dashed",
color = "gray50", linewidth = 0.8) +
annotate("text", x = 0.72, y = 7,
label = "真實值 = 0.7", hjust = 0, size = 3.5) +
labs(
title = "貝氏學習:從不確定到確定",
subtitle = "隨著資料增加,posterior 越來越集中在真實值",
x = "成功率 θ",
y = "機率密度",
color = "更新階段"
) +
theme_minimal(base_size = 14) +
theme(legend.position = "bottom")
```
**關鍵洞察**:
1. **Prior(藍色)**:很平坦,不確定性高
2. **5 次觀察(紅色)**:開始有點形狀,但還不確定
3. **10 次觀察(紫色)**:越來越集中
4. **20 次觀察(綠色)**:非常確定,幾乎集中在真實值 0.7
這展示了貝氏統計的核心:**資料越多,我們越確定**。
## 其他常見的共軛先驗
### Normal-Normal 共軛族
**設定**:估計常態分布的平均數 $\mu$(已知變異數 $\sigma^2$)
- Prior:$\mu \sim N(\mu_0, \tau_0^2)$
- Data:$x_1, \ldots, x_n \sim N(\mu, \sigma^2)$
- Posterior:$\mu \mid x \sim N(\mu_n, \tau_n^2)$
**更新公式**(精確度的加權平均):
$$\mu_n = \frac{\frac{1}{\tau_0^2}\mu_0 + \frac{n}{\sigma^2}\bar{x}}{\frac{1}{\tau_0^2} + \frac{n}{\sigma^2}}, \quad \frac{1}{\tau_n^2} = \frac{1}{\tau_0^2} + \frac{n}{\sigma^2}$$
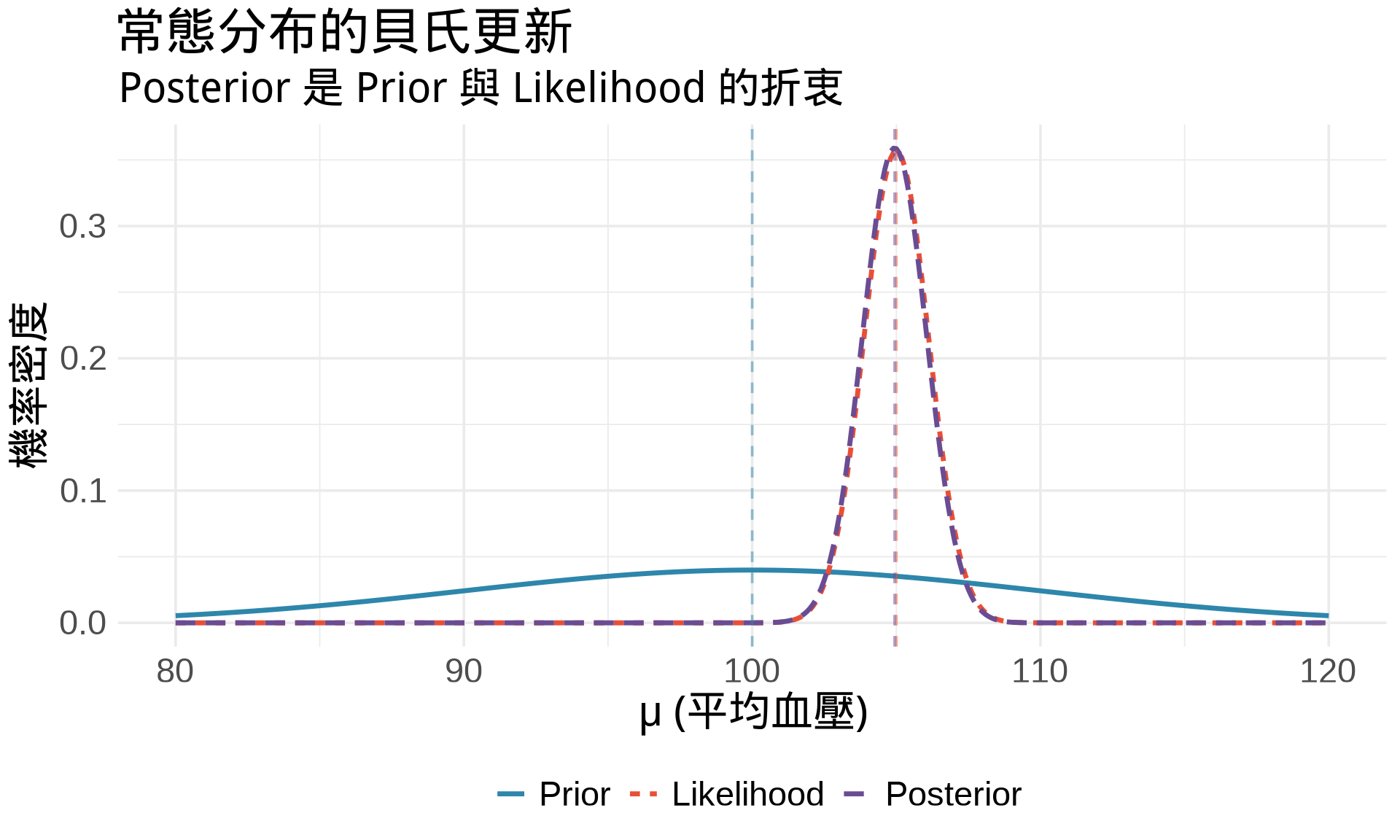
**直觀**:
- Posterior 的平均是 prior 平均與資料平均的**精確度加權平均**
- Posterior 的精確度($1/\tau_n^2$)是兩者精確度的**相加**
- 資料越多($n$ 越大),資料的權重越大
```{r}
#| label: fig-normal-conjugacy
#| fig-cap: "Normal-Normal 共軛更新"
#| warning: false
#| message: false
# 參數設定
mu_0 <- 100 # Prior mean
tau_0 <- 10 # Prior SD
sigma <- 5 # Data SD (已知)
n <- 20 # 樣本數
xbar <- 105 # 觀察到的樣本平均
# Posterior 參數
tau_n_sq <- 1 / (1/tau_0^2 + n/sigma^2)
mu_n <- tau_n_sq * (mu_0/tau_0^2 + n*xbar/sigma^2)
tau_n <- sqrt(tau_n_sq)
# 繪圖
x <- seq(80, 120, by = 0.1)
prior <- dnorm(x, mu_0, tau_0)
likelihood <- dnorm(x, xbar, sigma/sqrt(n)) # Sampling distribution of mean
posterior <- dnorm(x, mu_n, tau_n)
df <- data.frame(
x = rep(x, 3),
density = c(prior, likelihood, posterior),
type = rep(c("Prior", "Likelihood", "Posterior"), each = length(x))
)
df$type <- factor(df$type, levels = c("Prior", "Likelihood", "Posterior"))
ggplot(df, aes(x, density, color = type, linetype = type)) +
geom_line(linewidth = 1.2) +
scale_color_manual(values = c("#2E86AB", "#E94F37", "#6A4C93")) +
geom_vline(xintercept = c(mu_0, xbar, mu_n),
linetype = "dashed", color = c("#2E86AB", "#E94F37", "#6A4C93"),
alpha = 0.5) +
labs(
title = "常態分布的貝氏更新",
subtitle = "Posterior 是 Prior 與 Likelihood 的折衷",
x = "μ (平均血壓)",
y = "機率密度",
color = "",
linetype = ""
) +
theme_minimal(base_size = 14) +
theme(legend.position = "bottom")
```
### Gamma-Poisson 共軛族
**設定**:估計 Poisson 分布的參數 $\lambda$(例如:每小時到急診的病人數)
- Prior:$\lambda \sim \text{Gamma}(\alpha, \beta)$
- Data:$x_1, \ldots, x_n \sim \text{Poisson}(\lambda)$
- Posterior:$\lambda \mid x \sim \text{Gamma}(\alpha + \sum x_i, \beta + n)$
**更新規則**:
- Shape 參數:加上觀察到的總事件數
- Rate 參數:加上觀察次數
## 練習題
### 觀念題
1. **Prior 的選擇**:
- 如果我們對參數完全沒有先驗知識,應該用什麼 prior?
- 「無資訊先驗」(non-informative prior) 真的不包含任何資訊嗎?
::: {.callout-tip collapse="true" title="參考答案"}
常用 uniform distribution 作為無資訊先驗(如 Beta(1,1))。但「無資訊」其實是相對的概念,uniform prior 隱含「所有值等可能」的假設,這本身也是一種資訊。真正完全無資訊的 prior 在數學上不存在。
:::
2. **共軛先驗的優缺點**:
- 為什麼共軛先驗在數學上方便?
- 如果真實的先驗信念不是共軛分布,我們該怎麼辦?
::: {.callout-tip collapse="true" title="參考答案"}
共軛先驗讓 posterior 與 prior 屬於同一分布族,更新規則變成簡單的參數運算,積分可以直接計算。若真實先驗不是共軛分布,可使用數值方法(如 MCMC)計算 posterior,或選擇接近的共軛分布作為近似。
:::
3. **貝氏 vs 頻率學派**:
- 頻率學派的信賴區間:「如果重複實驗,95% 的區間會包含真實值」
- 貝氏的可信區間:「參數有 95% 的機率落在這個區間」
- 哪一個比較符合臨床醫師的思維?
::: {.callout-tip collapse="true" title="參考答案"}
貝氏可信區間更符合臨床思維。醫師面對單一病人時,關心的是「這個病人的參數落在某範圍的機率」,而非「重複實驗的長期表現」。貝氏方法提供對單一案例的機率陳述,更直觀且實用。
:::
4. **積分的角色**:為什麼計算 marginal likelihood $p(x) = \int p(x \mid \theta)p(\theta)d\theta$ 通常很困難?
::: {.callout-tip collapse="true" title="參考答案"}
這個積分需要對所有可能的 θ 值積分,當參數空間複雜或高維度時,解析解通常不存在。除了共軛先驗的特殊情況外,大多需要使用數值積分或 MCMC 等取樣方法來近似,這也是為什麼共軛先驗如此重要。
:::
5. **樣本數的影響**:當樣本數 $n \to \infty$ 時,posterior 會怎樣?prior 還重要嗎?
::: {.callout-tip collapse="true" title="參考答案"}
當樣本數趨近無窮大時,likelihood 主導 posterior,prior 的影響會逐漸消失。Posterior 會收斂到真實參數值附近的窄分布。這顯示貝氏方法在大樣本下與頻率學派趨於一致,prior 只在小樣本時影響較大。
:::
### 計算題
6. **Beta-Binomial 更新**:
- Prior:$\text{Beta}(3, 7)$(先驗認為成功率不高)
- Data:20 次試驗中成功 15 次
- 求 posterior 的參數、期望值、眾數
::: {.callout-tip collapse="true" title="參考答案"}
Posterior 參數:Beta(3+15, 7+5) = Beta(18, 12)。期望值 = 18/(18+12) = 0.6。眾數 = (18-1)/(18+12-2) = 17/28 ≈ 0.607。資料顯示成功率較高(15/20 = 0.75),明顯改變了原本偏低的先驗信念。
:::
7. **Normal-Normal 更新**:
- Prior:$\mu \sim N(170, 10^2)$(先驗認為平均身高 170 cm)
- Data:測量 25 人,樣本平均 175 cm,已知 $\sigma = 8$ cm
- 求 posterior 的參數
- 計算 95% 可信區間
::: {.callout-tip collapse="true" title="參考答案"}
精確度:1/τ²ₙ = 1/10² + 25/8² = 0.01 + 0.391 = 0.401,故 τₙ ≈ 1.58。平均數:μₙ = (170/100 + 25×175/64) / 0.401 ≈ 174.4。Posterior: N(174.4, 1.58²)。95% 可信區間:174.4 ± 1.96×1.58 = [171.3, 177.5]。
:::
8. **從頭推導 posterior**:
- Prior:$\theta \sim \text{Uniform}(0, 1)$(等於 $\text{Beta}(1, 1)$)
- Likelihood:二項式,$n=10$, $k=7$
- 寫出 posterior 的完整 PDF(包括正規化常數)
::: {.callout-tip collapse="true" title="參考答案"}
Posterior ∝ θ⁷(1-θ)³ × 1 = θ⁷(1-θ)³,這是 Beta(8, 4) 的 kernel。完整 PDF:p(θ|data) = [Γ(12)/(Γ(8)Γ(4))]θ⁷(1-θ)³ = 990θ⁷(1-θ)³,其中正規化常數 990 = 11!/(7!×3!),確保積分等於 1。
:::
### R 操作題
9. **視覺化 prior 的影響**:
```r
# 固定資料:10 次試驗中 7 次成功
# 嘗試不同的 prior
library(ggplot2)
theta <- seq(0, 1, by = 0.001)
k <- 7
n <- 10
# TODO: 畫出三種 prior 與對應的 posterior
# Prior 1: Beta(1, 1) - uniform (無資訊)
# Prior 2: Beta(10, 10) - 強烈相信 theta = 0.5
# Prior 3: Beta(1, 10) - 強烈相信 theta 很小
# 觀察:當 prior 很強時,少量資料能否改變我們的信念?
```
::: {.callout-tip collapse="true" title="參考答案"}
使用 patchwork 繪製三組 prior-posterior 對比圖。關鍵發現:無資訊 prior (Beta(1,1)) 讓資料主導結果;強 prior (Beta(10,10)) 需要更多資料才能改變信念;與資料衝突的 prior (Beta(1,10)) 仍會被資料逐漸修正,但更新較慢。
:::
10. **模擬貝氏學習過程**:
```r
# 模擬逐次更新
set.seed(123)
true_theta <- 0.6
observations <- rbinom(50, 1, true_theta)
# TODO: 從 Beta(1,1) 開始,每觀察一筆資料就更新
# TODO: 繪製 posterior mean 與 95% 可信區間隨時間變化
# TODO: 觀察何時 posterior 穩定下來
```
::: {.callout-tip collapse="true" title="參考答案"}
建立迴圈逐次更新 alpha 和 beta 參數,計算每次的 posterior mean (α/(α+β)) 和 95% 可信區間 (qbeta(c(0.025, 0.975), α, β))。繪製折線圖顯示估計值收斂過程。約 20-30 次觀察後,posterior 趨於穩定,可信區間明顯縮小。
:::
## 統計應用
### 臨床試驗中的貝氏方法
傳統臨床試驗(頻率學派):
- 固定樣本數(例如:需要 500 人)
- 試驗結束才分析
- p-value < 0.05 就宣稱有效
貝氏臨床試驗:
- 可以**適應性設計** (adaptive design)
- **逐次分析**:每收集一批病人就更新 posterior
- **提早停止**:如果 $P(\theta > 0.5 \mid \text{data}) > 0.95$,就停止試驗
- **納入先驗資訊**:利用過去類似藥物的資料
### Meta-analysis(統合分析)
假設有 5 個臨床試驗研究同一種藥:
- **頻率學派**:用 random-effects model 估計平均效應
- **貝氏方法**:每個試驗提供資料更新 posterior
貝氏 meta-analysis 的優點:
1. 自然地結合不同來源的證據
2. 可以處理小樣本試驗(頻率學派可能失效)
3. 直接給出「效應大於某值的機率」
### 診斷測試的解讀
回到急診醫師的例子:
- **Prior**:根據臨床評估,心肌梗塞機率 20%
- **Likelihood**:心電圖的靈敏度 80%、特異度 95%
- **Posterior**:更新後的機率?
這就是貝氏診斷推理!
**數學**(用離散版本):
$$P(\text{MI} \mid \text{ECG+}) = \frac{P(\text{ECG+} \mid \text{MI}) \cdot P(\text{MI})}{P(\text{ECG+})}$$
$$= \frac{0.8 \times 0.2}{0.8 \times 0.2 + 0.05 \times 0.8} = \frac{0.16}{0.2} = 0.8$$
所以心電圖陽性後,機率從 20% 上升到 80%。
### 個人化醫療
貝氏方法特別適合**個人化預測**:
- **Prior**:根據病人的基因型、病史建立個人化 prior
- **Data**:該病人對治療的初步反應
- **Posterior**:更新後的預後預測
這比傳統方法(用所有病人的平均效應)更精準。
## 本章重點整理 {.unnumbered}
1. **貝氏定理的連續版本**:
$$p(\theta \mid x) = \frac{p(x \mid \theta) \cdot p(\theta)}{\int p(x \mid \theta) \cdot p(\theta) \, d\theta}$$
分母是積分,確保 posterior 是合法的 PDF。
2. **Prior × Likelihood ∝ Posterior**:
- Prior:先驗信念(主觀或基於過去資料)
- Likelihood:當前資料的證據
- Posterior:結合兩者的更新信念
3. **共軛先驗的數學優勢**:
- Prior 和 posterior 同屬一個分布族
- 更新規則簡單(參數的代數運算)
- 積分可以直接算出(不需數值方法)
4. **Beta-Binomial 共軛族**:
$$\text{Beta}(\alpha, \beta) + k/n \Rightarrow \text{Beta}(\alpha+k, \beta+n-k)$$
直觀:把成功和失敗累加到 prior 的「虛擬觀察」上。
5. **貝氏學習的動態過程**:
- 今天的 posterior = 明天的 prior
- 資料越多,posterior 越集中(不確定性降低)
- 最終會收斂到真實值(頻率學派的性質)
6. **微積分的必要性**:
- 連續參數需要用 PDF 和積分
- 正規化常數的計算是貝氏統計的主要挑戰
- MCMC 等現代方法用數值方法近似積分