---
title: "Chapter 13: 機率分布"
---
```{r}
#| include: false
source(here::here("R/_common.R"))
```
## 學習目標 {.unnumbered}
- 理解 PDF 和 CDF 的微積分關係
- 掌握常見機率分布的數學形式
- 用積分計算期望值和變異數
- 視覺化理解機率分布的性質
## 概念說明
### 機率分布是什麼?
想像你在急診室測量病人的體溫。你不會每次都得到完全相同的數字,而是一個**分布**。機率分布就是用數學函數來描述「某個值出現的可能性」[@casella2002statistical]。
對於**連續型隨機變數**(如體溫、血壓、存活時間),我們用兩個關鍵函數:
1. **機率密度函數 (PDF, Probability Density Function)**:$f(x)$
- 描述「在 $x$ 附近的相對可能性」
- **注意**:$f(x)$ 不是機率,而是「密度」
- 機率 = 面積 = 積分
2. **累積分布函數 (CDF, Cumulative Distribution Function)**:$F(x)$
- 描述「小於等於 $x$ 的機率」
- $F(x) = P(X \leq x)$
### PDF 和 CDF 的微積分關係
這是統計學最美麗的關係之一:
$$
\boxed{
\begin{aligned}
F(x) &= \int_{-\infty}^{x} f(t)dt \quad \text{(CDF 是 PDF 的積分)} \\
f(x) &= \frac{d}{dx}F(x) \quad \text{(PDF 是 CDF 的導數)}
\end{aligned}
}
$$
**白話文**:
- CDF 是 PDF 曲線下的**累積面積**
- PDF 是 CDF 的**斜率**
## 視覺化理解
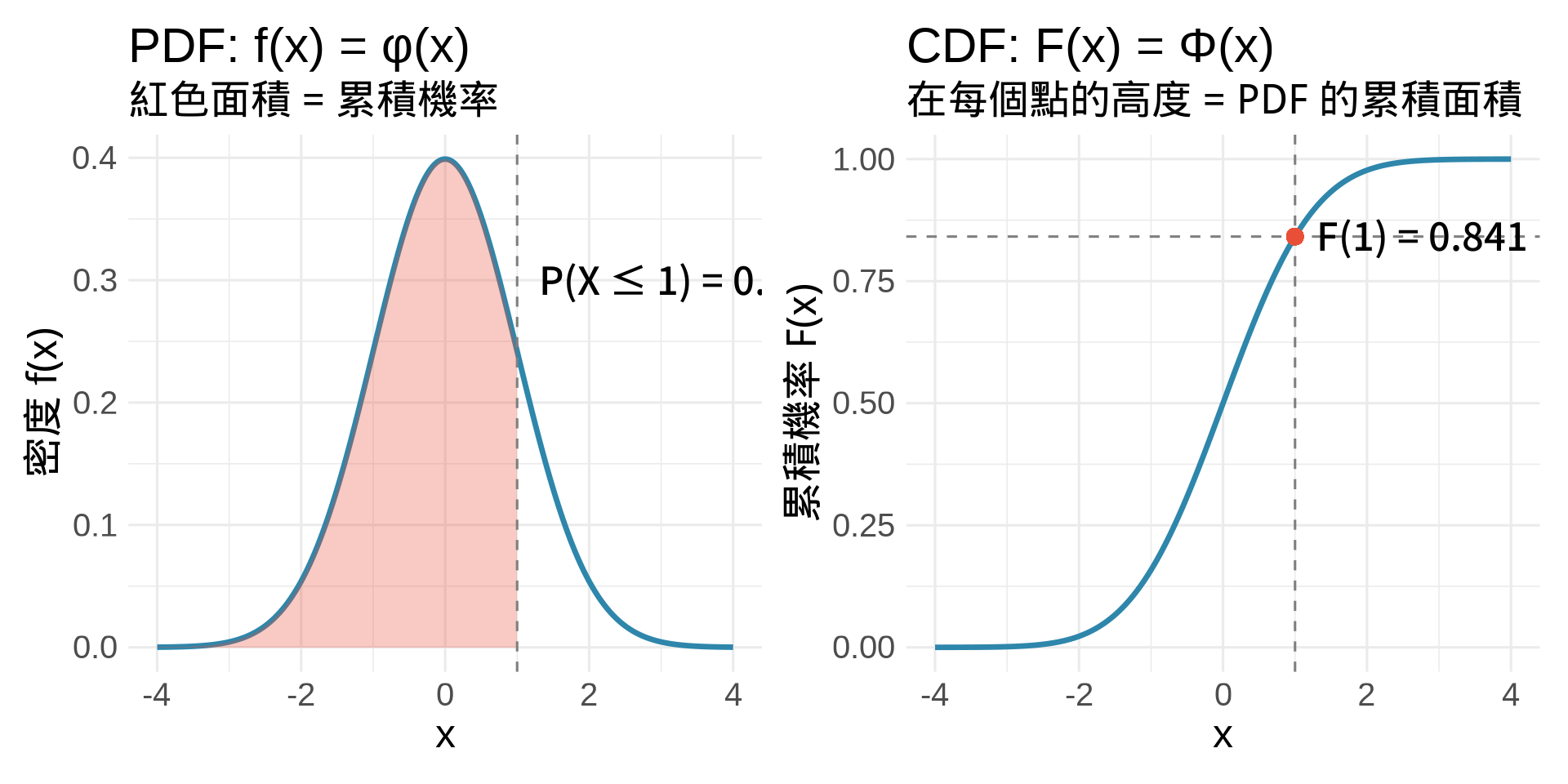
### PDF 和 CDF 的對應關係
```{r}
#| label: fig-pdf-cdf-normal
#| fig-cap: "標準常態分布的 PDF 和 CDF 關係"
#| fig-width: 10
#| fig-height: 5
x <- seq(-4, 4, by = 0.01)
pdf_vals <- dnorm(x)
cdf_vals <- pnorm(x)
# 標記某個點
x0 <- 1
p1 <- ggplot(data.frame(x, y = pdf_vals), aes(x, y)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
# 陰影:從 -∞ 到 x0
geom_area(data = data.frame(x = x[x <= x0], y = pdf_vals[x <= x0]),
aes(x, y), fill = "#E94F37", alpha = 0.3) +
geom_vline(xintercept = x0, linetype = "dashed", color = "gray50") +
annotate("text", x = x0 + 0.3, y = 0.3,
label = paste0("P(X ≤ ", x0, ") = ", round(pnorm(x0), 3)),
hjust = 0, size = 4) +
labs(
title = "PDF: f(x) = φ(x)",
subtitle = "紅色面積 = 累積機率",
x = "x", y = "密度 f(x)"
) +
theme_minimal(base_size = 12)
p2 <- ggplot(data.frame(x, y = cdf_vals), aes(x, y)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
geom_vline(xintercept = x0, linetype = "dashed", color = "gray50") +
geom_hline(yintercept = pnorm(x0), linetype = "dashed", color = "gray50") +
geom_point(aes(x = x0, y = pnorm(x0)), color = "#E94F37", size = 3) +
annotate("text", x = x0 + 0.3, y = pnorm(x0),
label = paste0("F(", x0, ") = ", round(pnorm(x0), 3)),
hjust = 0, size = 4) +
labs(
title = "CDF: F(x) = Φ(x)",
subtitle = "在每個點的高度 = PDF 的累積面積",
x = "x", y = "累積機率 F(x)"
) +
theme_minimal(base_size = 12)
p1 + p2
```
**解讀**:
- 左圖紅色面積 = $\int_{-\infty}^{1} f(x)dx \approx 0.841$
- 右圖在 $x=1$ 的高度 = 0.841
- **關鍵**:左圖的面積 = 右圖的高度
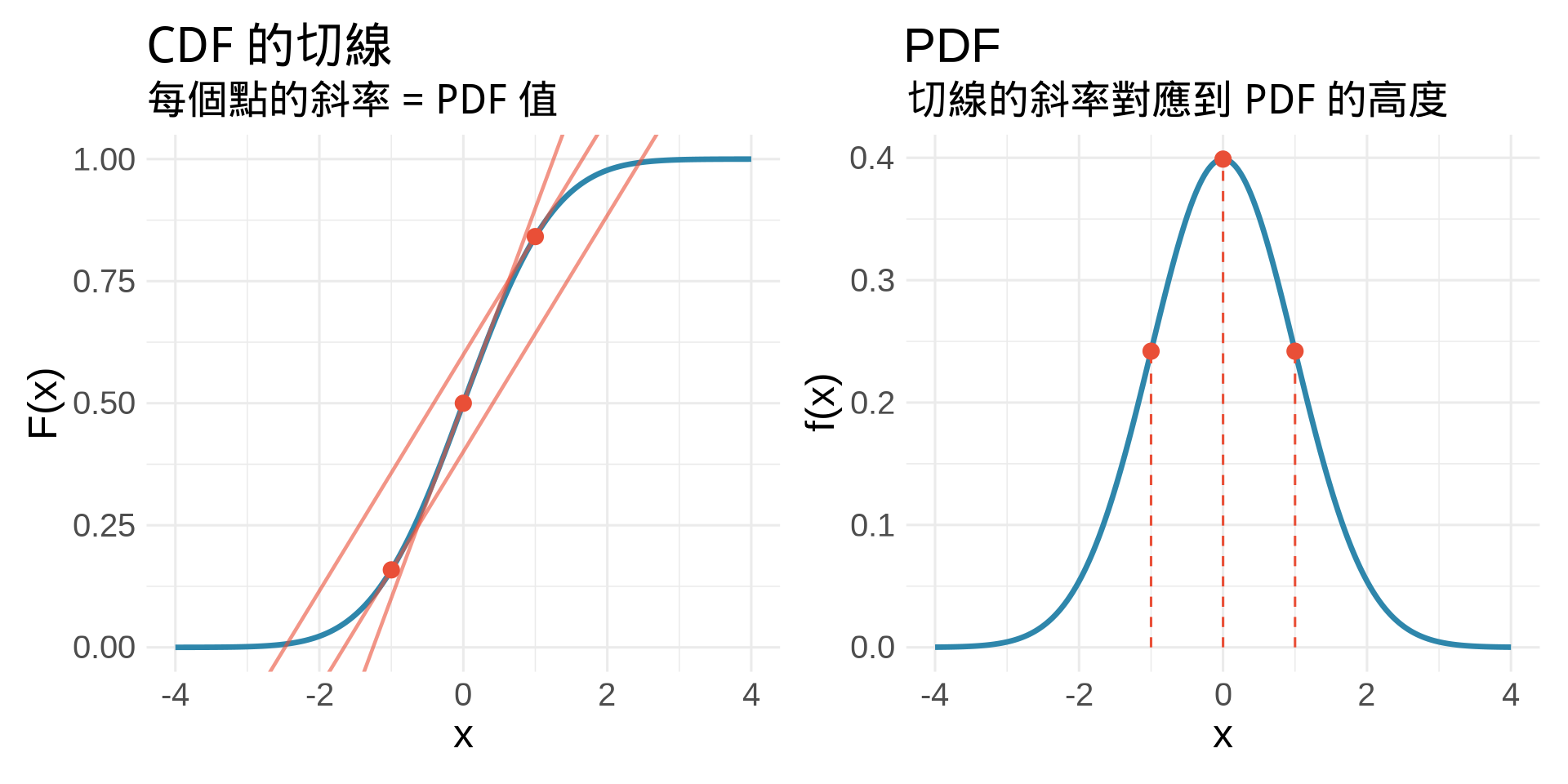
### PDF 是 CDF 的斜率
```{r}
#| label: fig-cdf-slope
#| fig-cap: "CDF 的斜率就是 PDF"
#| fig-width: 10
#| fig-height: 5
x <- seq(-4, 4, by = 0.01)
# 在幾個點畫切線
points_x <- c(-1, 0, 1)
points_df <- data.frame(x = points_x, cdf = pnorm(points_x), pdf = dnorm(points_x))
p1 <- ggplot(data.frame(x, cdf = pnorm(x)), aes(x, cdf)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
# 切線(用數值微分近似)
lapply(points_x, function(x0) {
slope <- dnorm(x0) # 斜率 = PDF 值
intercept <- pnorm(x0) - slope * x0
geom_abline(intercept = intercept, slope = slope,
color = "#E94F37", alpha = 0.6, linewidth = 0.8)
}) +
geom_point(data = points_df, aes(x = x, y = cdf),
color = "#E94F37", size = 3) +
labs(
title = "CDF 的切線",
subtitle = "每個點的斜率 = PDF 值",
x = "x", y = "F(x)"
) +
theme_minimal(base_size = 12)
p2 <- ggplot(data.frame(x, pdf = dnorm(x)), aes(x, pdf)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
geom_point(data = points_df, aes(x = x, y = pdf),
color = "#E94F37", size = 3) +
geom_segment(data = points_df, aes(x = x, y = 0, xend = x, yend = pdf),
color = "#E94F37", linetype = "dashed") +
labs(
title = "PDF",
subtitle = "切線的斜率對應到 PDF 的高度",
x = "x", y = "f(x)"
) +
theme_minimal(base_size = 12)
p1 + p2
```
**關鍵洞察**:
- CDF 斜率陡的地方 → PDF 高(該區域機率密度大)
- CDF 斜率平緩的地方 → PDF 低(該區域機率密度小)
## 數學定義
### 機率密度函數 (PDF)
對於連續型隨機變數 $X$,其機率密度函數 $f(x)$ 必須滿足:
1. **非負性**:$f(x) \geq 0$ for all $x$
2. **正規化條件**:$\int_{-\infty}^{\infty} f(x)dx = 1$(總面積 = 1)
**機率的計算**:
$$
P(a \leq X \leq b) = \int_a^b f(x)dx
$$
### 累積分布函數 (CDF)
$$
F(x) = P(X \leq x) = \int_{-\infty}^{x} f(t)dt
$$
**性質**:
- $F(-\infty) = 0$
- $F(\infty) = 1$
- $F(x)$ 是單調遞增的
- $F(x)$ 是右連續的
### 微積分關係
$$
\begin{aligned}
f(x) &= \frac{dF}{dx}(x) \\
F(x) &= \int_{-\infty}^{x} f(t)dt
\end{aligned}
$$
## 常見機率分布
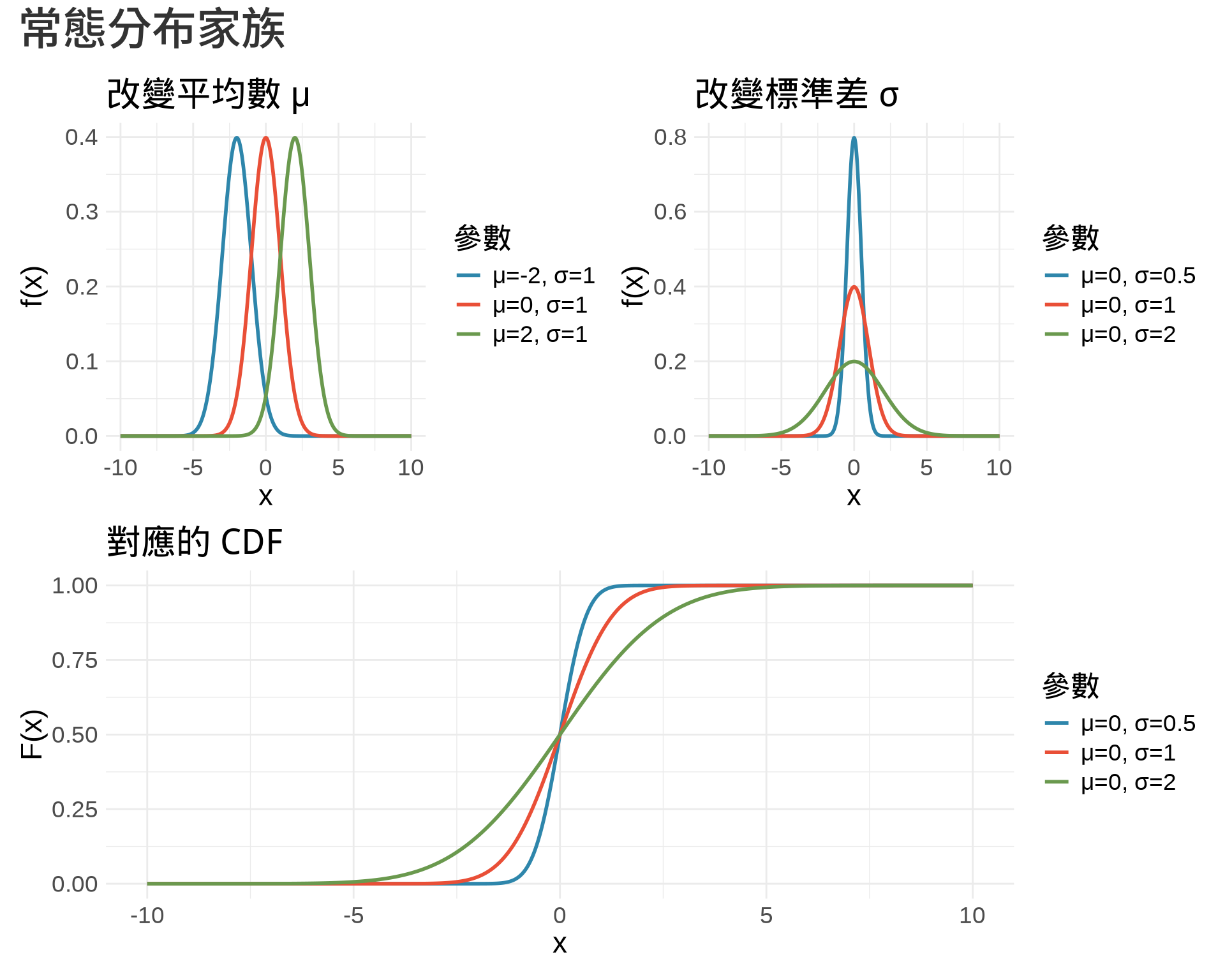
### 1. 常態分布 (Normal Distribution)
常態分布是統計學中最重要的連續型機率分布[@rosner2015fundamentals; @casella2002statistical]:
$$
f(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)
$$
```{r}
#| label: fig-normal-family
#| fig-cap: "不同參數的常態分布"
#| fig-width: 10
#| fig-height: 8
x <- seq(-10, 10, by = 0.01)
# 不同 μ
df1 <- data.frame(
x = rep(x, 3),
y = c(dnorm(x, 0, 1), dnorm(x, 2, 1), dnorm(x, -2, 1)),
param = rep(c("μ=0, σ=1", "μ=2, σ=1", "μ=-2, σ=1"), each = length(x))
)
p1 <- ggplot(df1, aes(x, y, color = param)) +
geom_line(linewidth = 1) +
scale_color_manual(values = c("#2E86AB", "#E94F37", "#6A994E")) +
labs(title = "改變平均數 μ", x = "x", y = "f(x)", color = "參數") +
theme_minimal(base_size = 11)
# 不同 σ
df2 <- data.frame(
x = rep(x, 3),
y = c(dnorm(x, 0, 1), dnorm(x, 0, 2), dnorm(x, 0, 0.5)),
param = rep(c("μ=0, σ=1", "μ=0, σ=2", "μ=0, σ=0.5"), each = length(x))
)
p2 <- ggplot(df2, aes(x, y, color = param)) +
geom_line(linewidth = 1) +
scale_color_manual(values = c("#2E86AB", "#E94F37", "#6A994E")) +
labs(title = "改變標準差 σ", x = "x", y = "f(x)", color = "參數") +
theme_minimal(base_size = 11)
# CDF
df3 <- data.frame(
x = rep(x, 3),
y = c(pnorm(x, 0, 1), pnorm(x, 0, 2), pnorm(x, 0, 0.5)),
param = rep(c("μ=0, σ=1", "μ=0, σ=2", "μ=0, σ=0.5"), each = length(x))
)
p3 <- ggplot(df3, aes(x, y, color = param)) +
geom_line(linewidth = 1) +
scale_color_manual(values = c("#2E86AB", "#E94F37", "#6A994E")) +
labs(title = "對應的 CDF", x = "x", y = "F(x)", color = "參數") +
theme_minimal(base_size = 11)
(p1 + p2) / p3 +
plot_annotation(title = "常態分布家族")
```
**醫學應用**:
- 血壓、身高、體重等生理指標
- 測量誤差
- 許多統計檢定的理論基礎
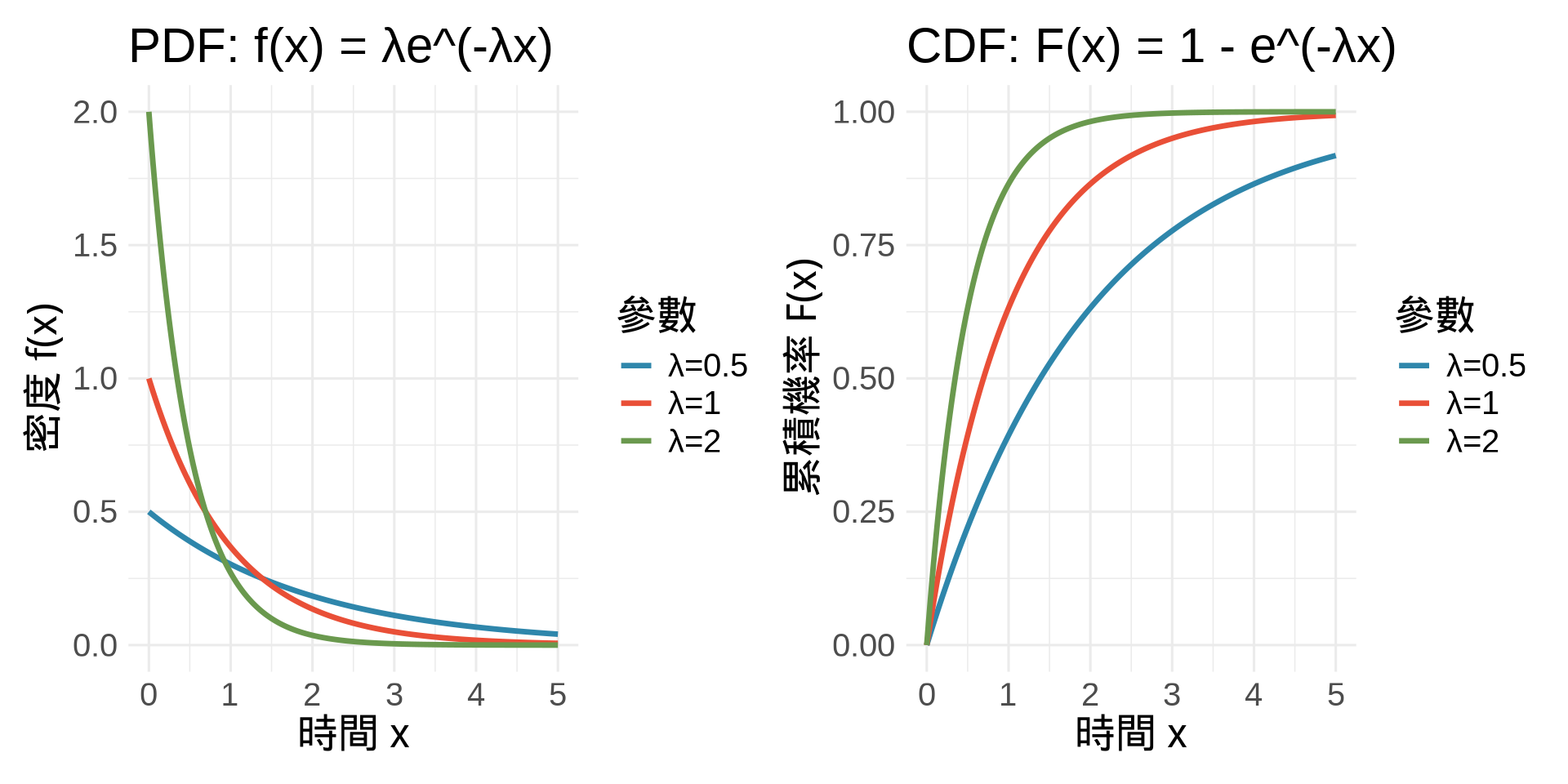
### 2. 指數分布 (Exponential Distribution)
指數分布常用於描述等待時間和存活分析[@collett2015modelling]:
$$
f(x) = \lambda e^{-\lambda x}, \quad x \geq 0
$$
$$
F(x) = 1 - e^{-\lambda x}
$$
```{r}
#| label: fig-exponential
#| fig-cap: "指數分布:存活分析的基石"
#| fig-width: 10
#| fig-height: 5
x <- seq(0, 5, by = 0.01)
df_exp <- data.frame(
x = rep(x, 3),
pdf = c(dexp(x, 0.5), dexp(x, 1), dexp(x, 2)),
cdf = c(pexp(x, 0.5), pexp(x, 1), pexp(x, 2)),
param = rep(c("λ=0.5", "λ=1", "λ=2"), each = length(x))
)
p1 <- ggplot(df_exp, aes(x, pdf, color = param)) +
geom_line(linewidth = 1.2) +
scale_color_manual(values = c("#2E86AB", "#E94F37", "#6A994E")) +
labs(
title = "PDF: f(x) = λe^(-λx)",
x = "時間 x", y = "密度 f(x)", color = "參數"
) +
theme_minimal(base_size = 12)
p2 <- ggplot(df_exp, aes(x, cdf, color = param)) +
geom_line(linewidth = 1.2) +
scale_color_manual(values = c("#2E86AB", "#E94F37", "#6A994E")) +
labs(
title = "CDF: F(x) = 1 - e^(-λx)",
x = "時間 x", y = "累積機率 F(x)", color = "參數"
) +
theme_minimal(base_size = 12)
p1 + p2
```
**醫學應用**:
- 存活時間(當 hazard 為常數)
- 等待時間(如器官移植等待時間)
- 疾病復發的時間間隔
**無記憶性 (Memoryless Property)**:
$$
P(X > s+t | X > s) = P(X > t)
$$
意思是「已經存活 $s$ 時間後,再存活 $t$ 時間的機率」與「一開始就存活 $t$ 時間的機率」相同。
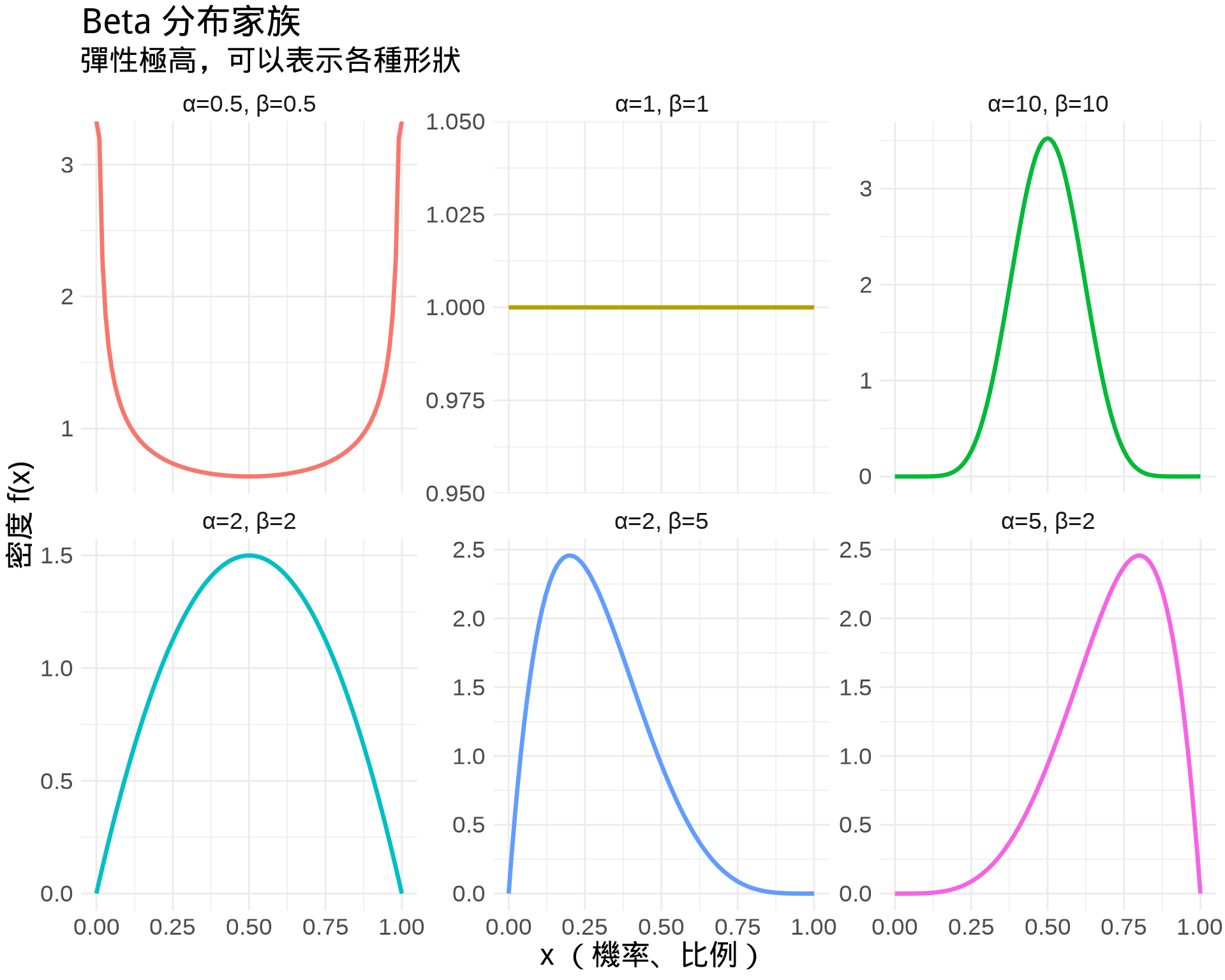
### 3. Beta 分布 (Beta Distribution)
$$
f(x) = \frac{x^{\alpha-1}(1-x)^{\beta-1}}{B(\alpha, \beta)}, \quad 0 \leq x \leq 1
$$
其中 $B(\alpha, \beta) = \int_0^1 t^{\alpha-1}(1-t)^{\beta-1}dt$(Beta 函數,正規化常數)
```{r}
#| label: fig-beta
#| fig-cap: "Beta 分布:貝氏統計的先驗分布"
#| fig-width: 10
#| fig-height: 8
x <- seq(0, 1, by = 0.01)
# 不同的 α, β 組合
params <- list(
c(0.5, 0.5), c(1, 1), c(2, 2),
c(2, 5), c(5, 2), c(10, 10)
)
df_beta <- do.call(rbind, lapply(params, function(p) {
data.frame(
x = x,
y = dbeta(x, p[1], p[2]),
param = paste0("α=", p[1], ", β=", p[2])
)
}))
ggplot(df_beta, aes(x, y, color = param)) +
geom_line(linewidth = 1.2) +
facet_wrap(~param, ncol = 3, scales = "free_y") +
labs(
title = "Beta 分布家族",
subtitle = "彈性極高,可以表示各種形狀",
x = "x (機率、比例)", y = "密度 f(x)"
) +
theme_minimal(base_size = 11) +
theme(legend.position = "none")
```
**醫學應用**:
- 貝氏分析中的先驗分布(如疾病盛行率)
- 模擬機率或比例(範圍限制在 0 到 1)
- Meta-analysis 的隨機效應
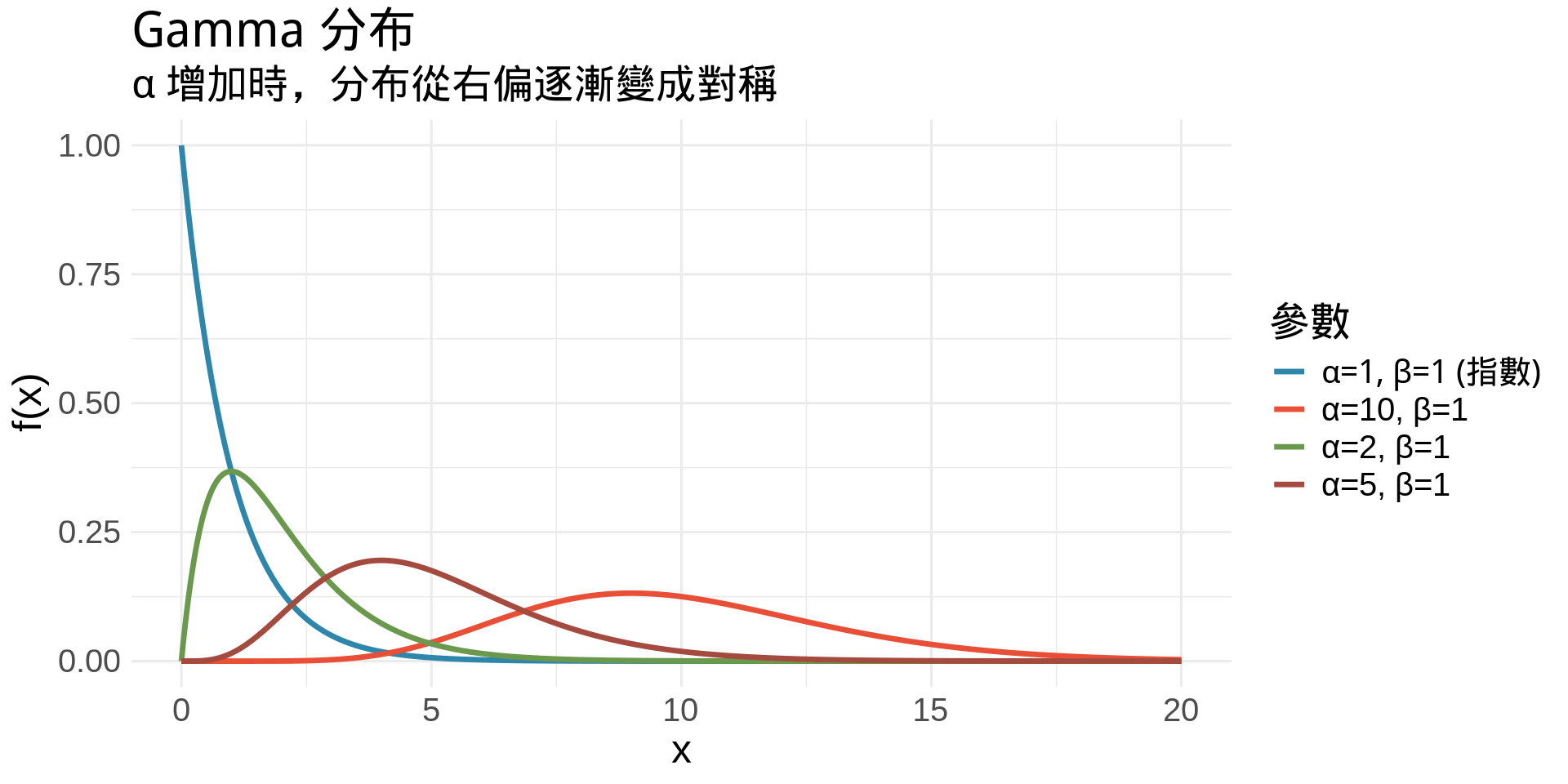
### 4. Gamma 分布 (Gamma Distribution)
$$
f(x) = \frac{\beta^\alpha}{\Gamma(\alpha)} x^{\alpha-1} e^{-\beta x}, \quad x \geq 0
$$
其中 $\Gamma(\alpha) = \int_0^\infty t^{\alpha-1}e^{-t}dt$(Gamma 函數)
```{r}
#| label: fig-gamma
#| fig-cap: "Gamma 分布:等待時間的推廣"
#| fig-width: 10
#| fig-height: 5
x <- seq(0, 20, by = 0.01)
df_gamma <- data.frame(
x = rep(x, 4),
pdf = c(
dgamma(x, shape = 1, rate = 1), # 等於指數分布
dgamma(x, shape = 2, rate = 1),
dgamma(x, shape = 5, rate = 1),
dgamma(x, shape = 10, rate = 1)
),
param = rep(c("α=1, β=1 (指數)", "α=2, β=1", "α=5, β=1", "α=10, β=1"),
each = length(x))
)
ggplot(df_gamma, aes(x, pdf, color = param)) +
geom_line(linewidth = 1.2) +
scale_color_manual(values = c("#2E86AB", "#E94F37", "#6A994E", "#A44A3F")) +
labs(
title = "Gamma 分布",
subtitle = "α 增加時,分布從右偏逐漸變成對稱",
x = "x", y = "f(x)", color = "參數"
) +
theme_minimal(base_size = 12)
```
**醫學應用**:
- 等待多個事件發生的時間(如等待第 k 次復發)
- 存活分析中的 Weibull 分布(Gamma 的變形)
- 貝氏分析中的共軛先驗
## 期望值與變異數
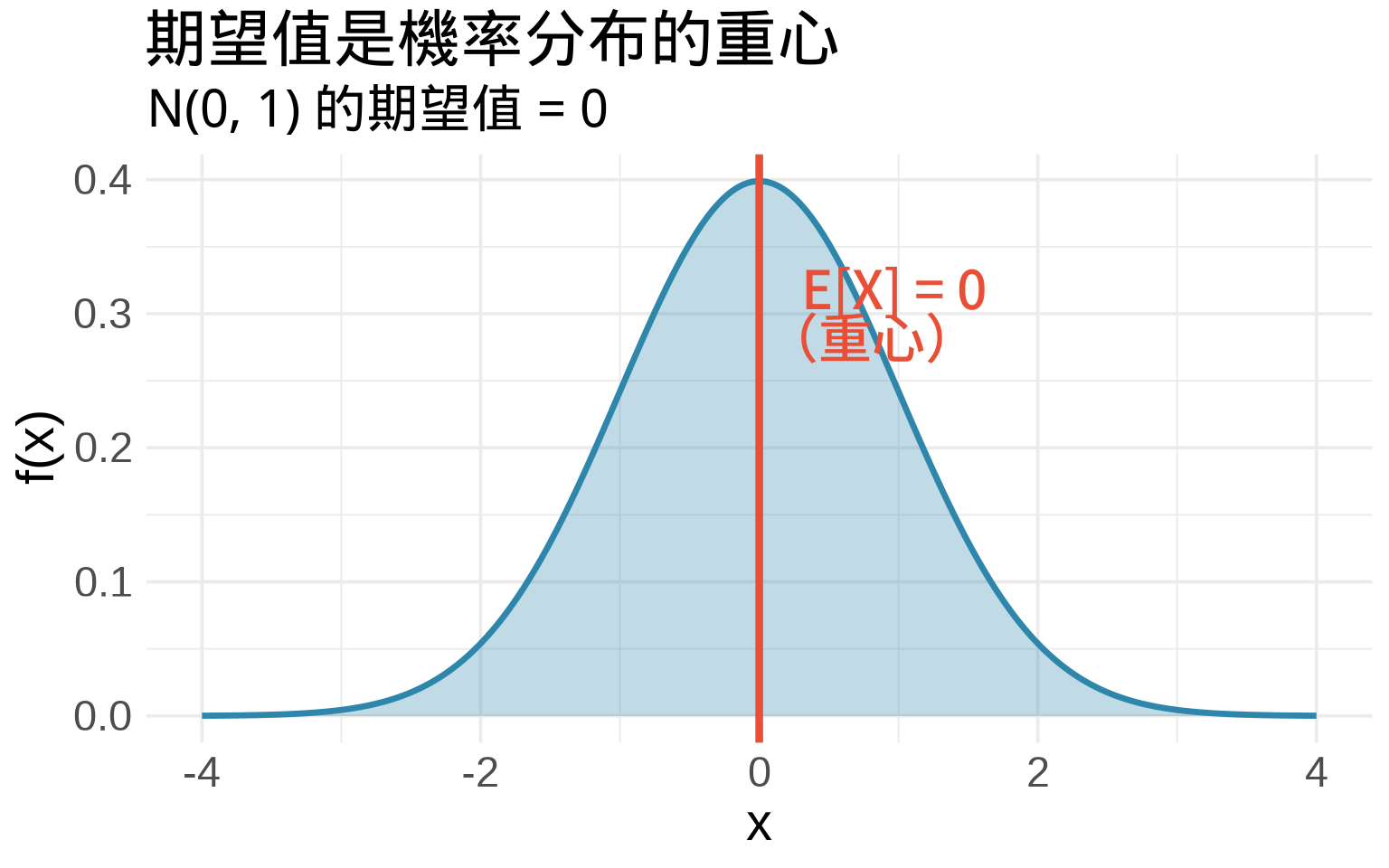
### 期望值 (Expected Value)
期望值是隨機變數的「加權平均」,權重是機率密度:
$$
E[X] = \int_{-\infty}^{\infty} x \cdot f(x)dx
$$
**視覺化理解**:期望值是 PDF 的「重心」。
```{r}
#| label: fig-expected-value
#| fig-cap: "期望值是 PDF 的重心"
#| fig-width: 8
#| fig-height: 5
# 標準常態分布
x <- seq(-4, 4, by = 0.01)
pdf <- dnorm(x)
ggplot(data.frame(x, pdf), aes(x, pdf)) +
geom_area(fill = "#2E86AB", alpha = 0.3) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
geom_vline(xintercept = 0, color = "#E94F37", linewidth = 1.5) +
annotate("text", x = 0.3, y = 0.3, label = "E[X] = 0\n(重心)",
hjust = 0, size = 5, color = "#E94F37") +
labs(
title = "期望值是機率分布的重心",
subtitle = "N(0, 1) 的期望值 = 0",
x = "x", y = "f(x)"
) +
theme_minimal(base_size = 14)
```
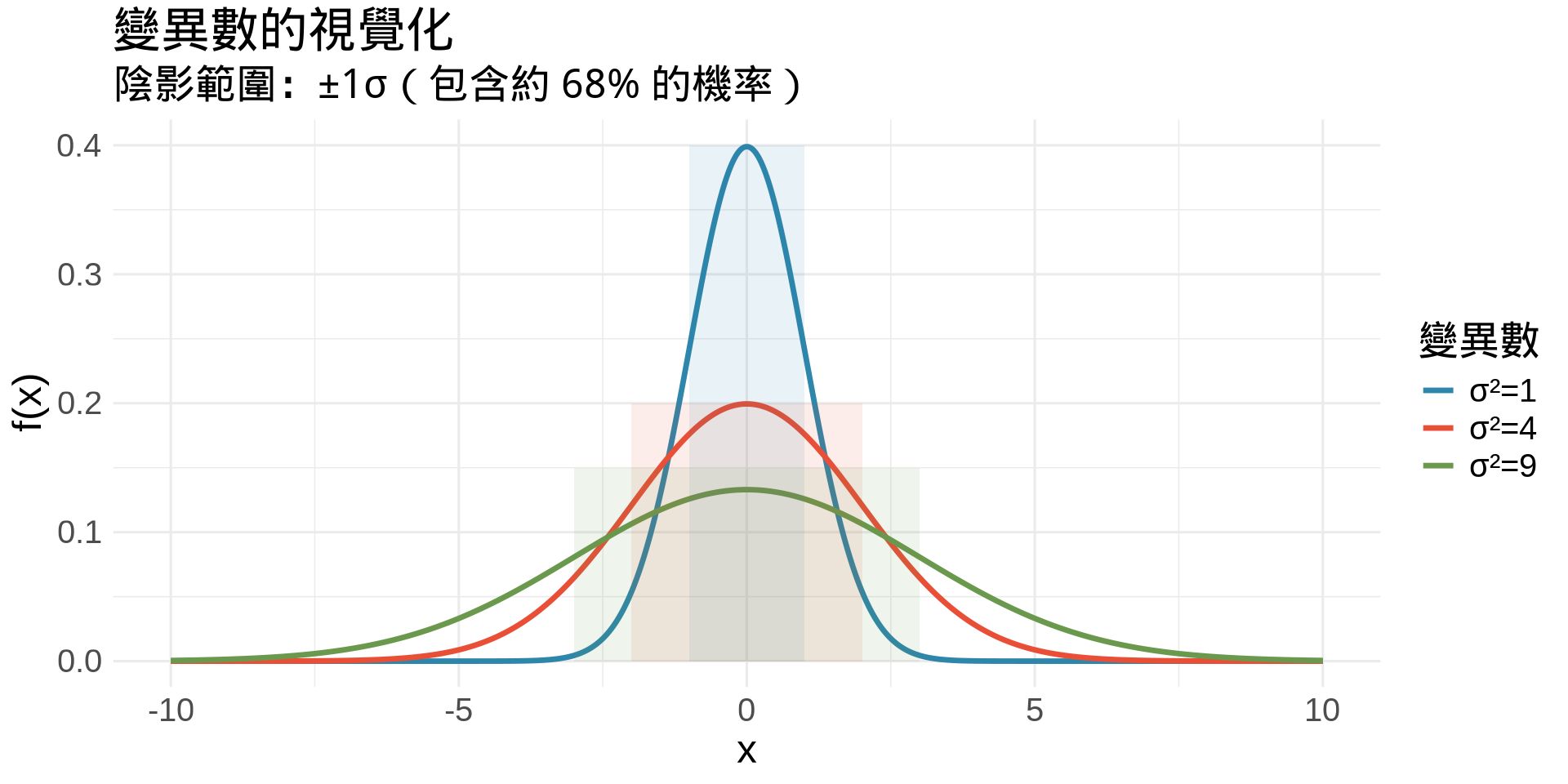
### 變異數 (Variance)
變異數衡量「離散程度」:
$$
\text{Var}(X) = E[(X - \mu)^2] = \int_{-\infty}^{\infty} (x-\mu)^2 f(x)dx
$$
另一個計算公式(用期望值表示):
$$
\text{Var}(X) = E[X^2] - (E[X])^2
$$
```{r}
#| label: fig-variance
#| fig-cap: "變異數越大,分布越分散"
#| fig-width: 10
#| fig-height: 5
x <- seq(-10, 10, by = 0.01)
df_var <- data.frame(
x = rep(x, 3),
y = c(dnorm(x, 0, 1), dnorm(x, 0, 2), dnorm(x, 0, 3)),
variance = rep(c("σ²=1", "σ²=4", "σ²=9"), each = length(x))
)
ggplot(df_var, aes(x, y, color = variance)) +
geom_line(linewidth = 1.2) +
scale_color_manual(values = c("#2E86AB", "#E94F37", "#6A994E")) +
# 標記 ±1σ 的範圍
annotate("rect", xmin = -1, xmax = 1, ymin = 0, ymax = 0.4,
alpha = 0.1, fill = "#2E86AB") +
annotate("rect", xmin = -2, xmax = 2, ymin = 0, ymax = 0.2,
alpha = 0.1, fill = "#E94F37") +
annotate("rect", xmin = -3, xmax = 3, ymin = 0, ymax = 0.15,
alpha = 0.1, fill = "#6A994E") +
labs(
title = "變異數的視覺化",
subtitle = "陰影範圍:±1σ(包含約 68% 的機率)",
x = "x", y = "f(x)", color = "變異數"
) +
theme_minimal(base_size = 12)
```
## 練習題
### 觀念題
1. 為什麼 PDF $f(x)$ 可以大於 1,但 CDF $F(x)$ 不能大於 1?
::: {.callout-tip collapse="true" title="參考答案"}
因為 PDF 代表的是「密度」而非機率,所以可以大於 1(例如 Uniform(0, 0.5) 的密度是 2)。而 CDF 代表的是「累積機率」$P(X \leq x)$,機率必定介於 0 到 1 之間。關鍵差異:PDF 的值本身不是機率,而是需要積分(計算面積)才能得到機率;CDF 的值本身就是機率。
:::
2. 如果 CDF 在某一段是平的(斜率 = 0),代表什麼意思?
::: {.callout-tip collapse="true" title="參考答案"}
因為 PDF 是 CDF 的導數,所以斜率為 0 表示該區間的 PDF = 0,意即該區間的機率密度為零,隨機變數不可能落在這個範圍內。這在離散型隨機變數或混合型分布中很常見。
:::
3. 指數分布的「無記憶性」在醫學上合理嗎?舉一個合理和一個不合理的例子。
::: {.callout-tip collapse="true" title="參考答案"}
**合理例子**:某些急性疾病的發生(如突發性心臟病),過去沒發生不會降低未來的風險。**不合理例子**:癌症復發,因為已經存活越久的病人,通常代表預後較好,未來復發的風險會降低(有記憶性)。大多數醫學事件都有記憶性,指數分布只是簡化假設。
:::
### 計算題
1. 已知 PDF $f(x) = 2x$, $0 \leq x \leq 1$。求:
- CDF $F(x)$
- $P(0.5 \leq X \leq 0.8)$
- $E[X]$
::: {.callout-tip collapse="true" title="參考答案"}
**CDF**: $F(x) = \int_0^x 2t\,dt = [t^2]_0^x = x^2$
**機率**: $P(0.5 \leq X \leq 0.8) = \int_{0.5}^{0.8} 2x\,dx = [x^2]_{0.5}^{0.8} = 0.64 - 0.25 = 0.39$
**期望值**: $E[X] = \int_0^1 x \cdot 2x\,dx = \int_0^1 2x^2\,dx = [\frac{2x^3}{3}]_0^1 = \frac{2}{3}$
:::
2. 已知 CDF $F(x) = 1 - e^{-\lambda x}$, $x \geq 0$。求:
- PDF $f(x)$
- $P(X > 2)$ when $\lambda = 0.5$
::: {.callout-tip collapse="true" title="參考答案"}
**PDF**: $f(x) = \frac{d}{dx}F(x) = \frac{d}{dx}(1 - e^{-\lambda x}) = \lambda e^{-\lambda x}$ (這就是指數分布)
**機率**: $P(X > 2) = 1 - F(2) = 1 - (1 - e^{-0.5 \times 2}) = e^{-1} \approx 0.368$
或用 R 驗證:`1 - pexp(2, rate = 0.5)` 或 `pexp(2, rate = 0.5, lower.tail = FALSE)`
:::
### R 操作題
修改下列程式碼,觀察變化:
```{r}
#| eval: false
# 1. 改變常態分布的 μ 和 σ,觀察 PDF 和 CDF 如何變化
mu <- 0
sigma <- 1
x <- seq(-10, 10, by = 0.01)
ggplot(data.frame(x), aes(x)) +
stat_function(fun = dnorm, args = list(mean = mu, sd = sigma),
color = "#2E86AB") +
labs(title = paste0("N(", mu, ", ", sigma, "²)"))
# 2. 計算「距離平均數 ±2σ」包含多少機率
pnorm(mu + 2*sigma, mu, sigma) - pnorm(mu - 2*sigma, mu, sigma)
# 3. 視覺化指數分布的「無記憶性」
lambda <- 1
curve(dexp(x, lambda), from = 0, to = 5, col = "#2E86AB", lwd = 2)
# 計算 P(X > 3 | X > 1)
(1 - pexp(3, lambda)) / (1 - pexp(1, lambda))
# 比較 P(X > 2)
1 - pexp(2, lambda)
```
::: {.callout-tip collapse="true" title="參考答案"}
**題 1**:試著改變 `mu = 5` 和 `sigma = 2`,你會看到曲線向右平移且變得更扁平。μ 控制位置,σ 控制分散程度。
**題 2**:結果約為 0.954(95.4%)。這是常態分布的重要性質:約 95% 的資料落在平均數 ±2 個標準差內。改成 ±1σ 會得到約 68%,±3σ 會得到約 99.7%。
**題 3**:無記憶性驗證:$P(X > 3 | X > 1) = \frac{P(X > 3)}{P(X > 1)} = \frac{e^{-3}}{e^{-1}} = e^{-2}$,這恰好等於 $P(X > 2) = e^{-2}$,證明了無記憶性。兩個答案應該完全相同(約 0.135)。
:::
## 統計應用
### 為什麼需要理解 PDF 和 CDF 的微積分關係?
1. **假設檢定中的 p-value**:
$$
\text{p-value} = \int_{t_{\text{obs}}}^{\infty} f(t)dt = 1 - F(t_{\text{obs}})
$$
2. **信賴區間的建構**:
找到 $a, b$ 使得 $\int_a^b f(x)dx = 0.95$
3. **最大概似估計**:
需要對 $f(x; \theta)$ 微分
4. **存活分析**:
Survival function $S(t) = 1 - F(t)$
## 本章重點整理 {.unnumbered}
- **PDF 和 CDF 互為微積分關係**:$f(x) = F'(x)$, $F(x) = \int_{-\infty}^x f(t)dt$
- **機率 = 面積 = 積分**:$P(a \leq X \leq b) = \int_a^b f(x)dx$
- **常見分布**:Normal, Exponential, Beta, Gamma
- **期望值**:$E[X] = \int x f(x)dx$(PDF 的重心)
- **變異數**:$\text{Var}(X) = \int (x-\mu)^2 f(x)dx$(離散程度)
**下一章預告**:我們將用微分來找參數的最佳估計值 — Maximum Likelihood Estimation (MLE)。