---
title: "Chapter 8: 積分的概念"
---
```{r}
#| include: false
source(here::here("R/_common.R"))
```
## 學習目標 {.unnumbered}
- 理解積分的幾何意義:曲線下的面積
- 從 Riemann Sum(長方形近似)到精確積分
- 連結統計概念:PDF 下的面積 = 機率
- 理解累積分布函數 (CDF) 的形成過程
## 積分是什麼?
在 Part II 我們學了**微分**:找出函數在某一點的「瞬時變化率」。現在我們要學習微分的反向操作:**積分 (Integration)**。
### 直觀理解
想像你在測量一塊**不規則形狀土地的面積**:
1. 最簡單的方法:用很多小長方形去填滿它
2. 長方形越小、越多,估計越準確
3. 當長方形「無限多、無限小」時,就得到**精確面積**
這就是積分的本質!
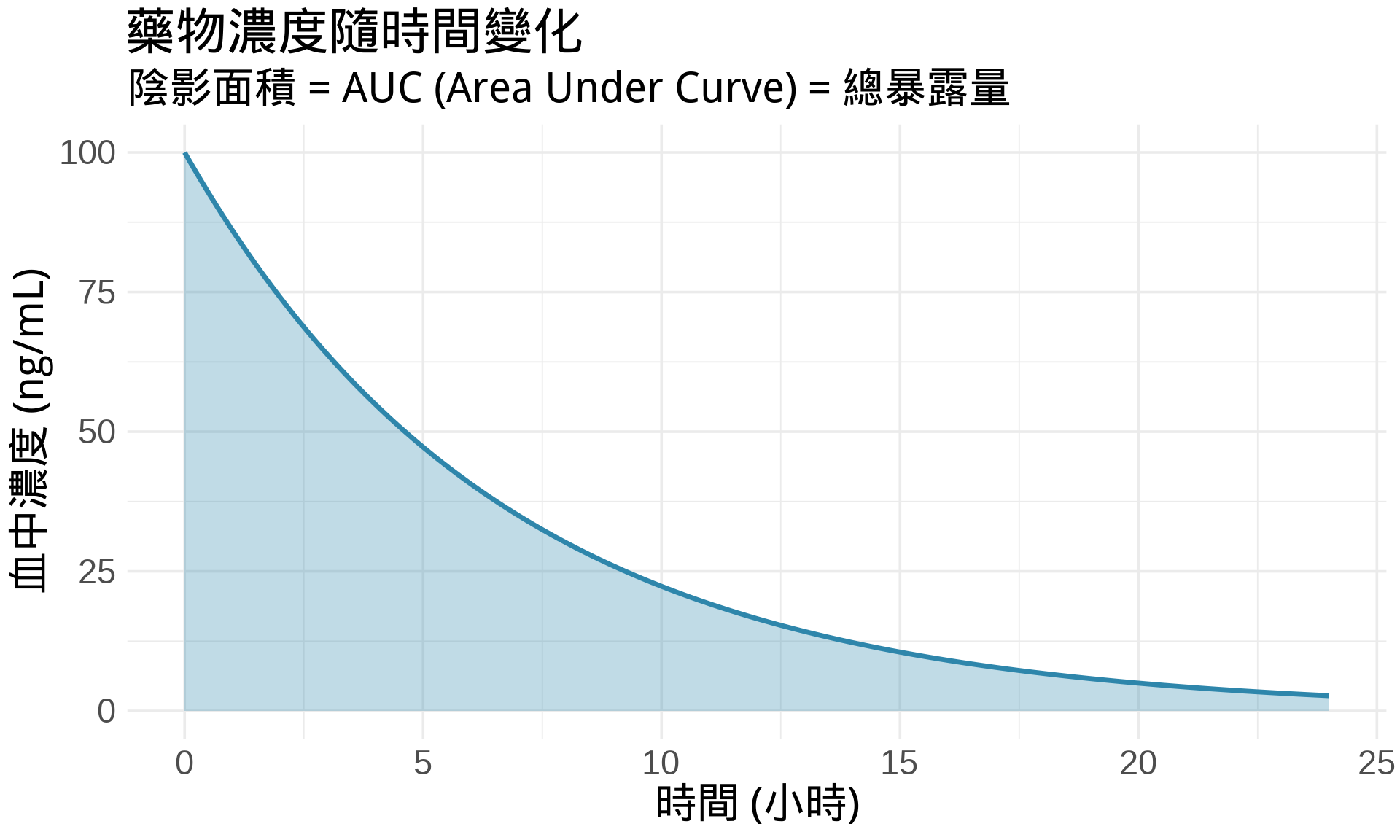
### 醫學例子:藥物濃度曲線下面積 (AUC)
在藥物動力學中,**AUC (Area Under the Curve)** 代表藥物在體內的總暴露量:
```{r}
#| label: fig-auc-example
#| fig-cap: "藥物濃度-時間曲線下面積 (AUC)"
#| warning: false
#| message: false
# 模擬單劑量藥物濃度曲線
time <- seq(0, 24, by = 0.1)
conc <- 100 * exp(-0.15 * time) # 指數衰減
df <- data.frame(time, conc)
ggplot(df, aes(time, conc)) +
geom_area(fill = "#2E86AB", alpha = 0.3) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
labs(
title = "藥物濃度隨時間變化",
subtitle = "陰影面積 = AUC (Area Under Curve) = 總暴露量",
x = "時間 (小時)",
y = "血中濃度 (ng/mL)"
) +
theme_minimal(base_size = 14)
```
**AUC 就是一個積分**:
$$\text{AUC} = \int_0^{24} C(t)dt$$
其中 $C(t)$ 是濃度隨時間的函數。
## 從長方形到積分:Riemann Sum
### 概念
假設我們要計算函數 $f(x)$ 在區間 $[a, b]$ 下的面積 [@stewart2015calculus]:
1. 把區間分成 $n$ 個小區間
2. 每個小區間寬度 $\Delta x = \frac{b-a}{n}$
3. 用長方形近似每個小區間的面積
4. 加總所有長方形面積
這叫做 **Riemann Sum**:
$$\text{面積} \approx \sum_{i=1}^n f(x_i) \cdot \Delta x$$
當 $n \to \infty$(長方形無限多),我們得到**定積分 (Definite Integral)**:
$$\text{面積} = \lim_{n \to \infty} \sum_{i=1}^n f(x_i) \cdot \Delta x = \int_a^b f(x)dx$$
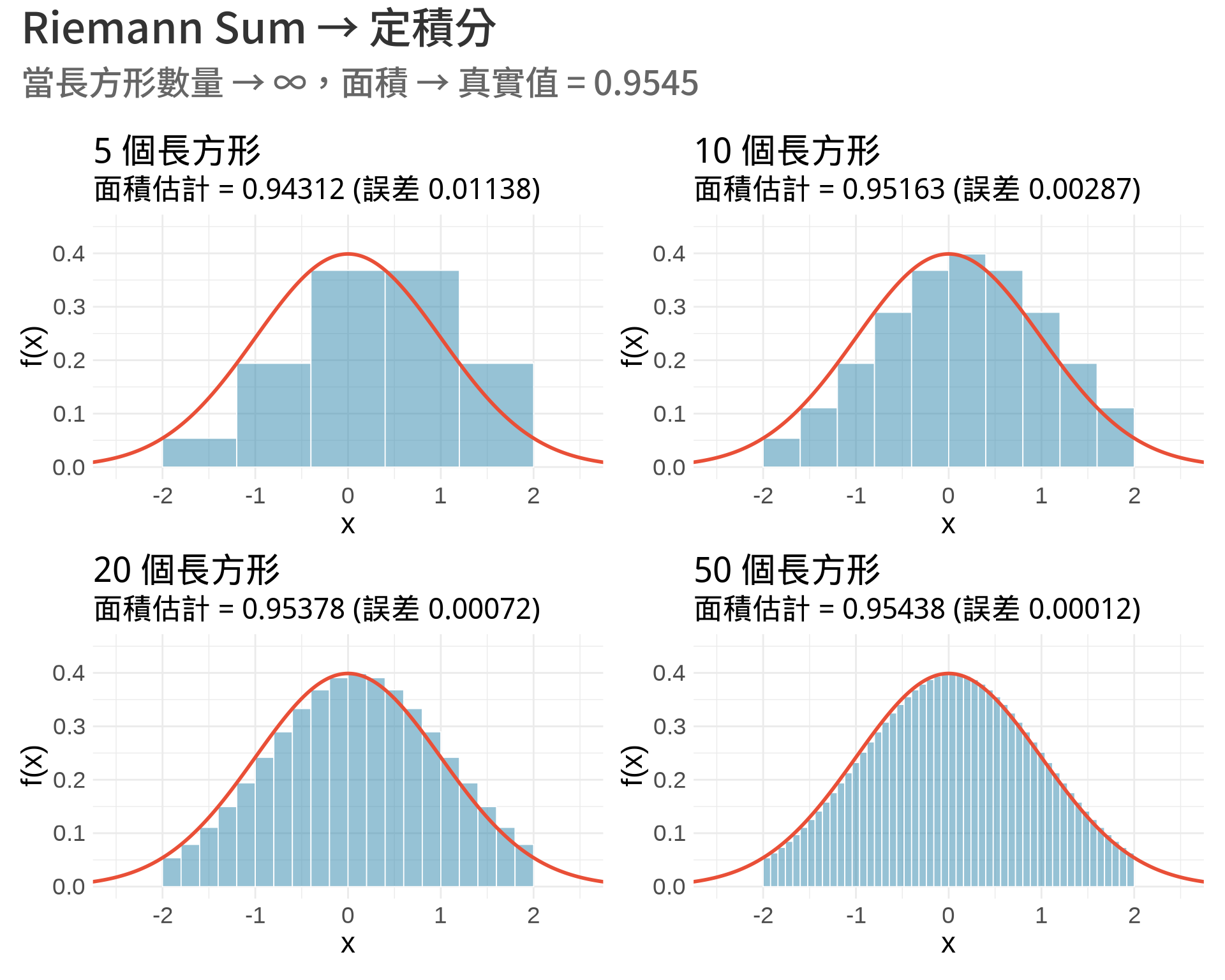
### 視覺化:長方形越多,越接近真實面積
```{r}
#| label: fig-riemann-sum
#| fig-cap: "Riemann Sum:長方形數量增加,面積估計越準確"
#| warning: false
#| message: false
#| fig-width: 10
#| fig-height: 8
# 目標函數:標準常態分布 PDF
f <- function(x) dnorm(x, mean = 0, sd = 1)
# 真實積分值
true_area <- pnorm(2) - pnorm(-2)
create_riemann_plot <- function(n_rect) {
# 區間 [-2, 2]
x_breaks <- seq(-2, 2, length.out = n_rect + 1)
width <- diff(x_breaks)[1]
# 用左端點高度
x_left <- x_breaks[-(n_rect + 1)]
heights <- f(x_left)
rects <- data.frame(
xmin = x_left,
xmax = x_left + width,
ymin = 0,
ymax = heights
)
area <- sum(heights * width)
error <- abs(area - true_area)
x_smooth <- seq(-3, 3, by = 0.01)
ggplot() +
# 長方形
geom_rect(data = rects,
aes(xmin = xmin, xmax = xmax, ymin = ymin, ymax = ymax),
fill = "#2E86AB", alpha = 0.5, color = "white", linewidth = 0.3) +
# 真實曲線
geom_line(aes(x = x_smooth, y = f(x_smooth)),
color = "#E94F37", linewidth = 1) +
labs(
title = paste0(n_rect, " 個長方形"),
subtitle = paste0("面積估計 = ", round(area, 5),
" (誤差 ", round(error, 5), ")"),
x = "x", y = "f(x)"
) +
coord_cartesian(xlim = c(-2.5, 2.5), ylim = c(0, 0.45)) +
theme_minimal(base_size = 11)
}
p1 <- create_riemann_plot(5)
p2 <- create_riemann_plot(10)
p3 <- create_riemann_plot(20)
p4 <- create_riemann_plot(50)
(p1 | p2) / (p3 | p4) +
plot_annotation(
title = "Riemann Sum → 定積分",
subtitle = paste0("當長方形數量 → ∞,面積 → 真實值 = ", round(true_area, 5)),
theme = theme(plot.title = element_text(size = 16, face = "bold"))
)
```
**觀察重點**:
- 5 個長方形:誤差較大
- 50 個長方形:已經非常接近真實值
- 當 $n \to \infty$:誤差 → 0
## 定積分的符號與意義
### 符號
$$\int_a^b f(x)dx$$
- $\int$:積分符號(拉長的 S,代表 Sum)
- $a$:下界 (lower limit)
- $b$:上界 (upper limit)
- $f(x)$:被積函數 (integrand)
- $dx$:表示對 $x$ 積分,$\Delta x$ 的極限形式
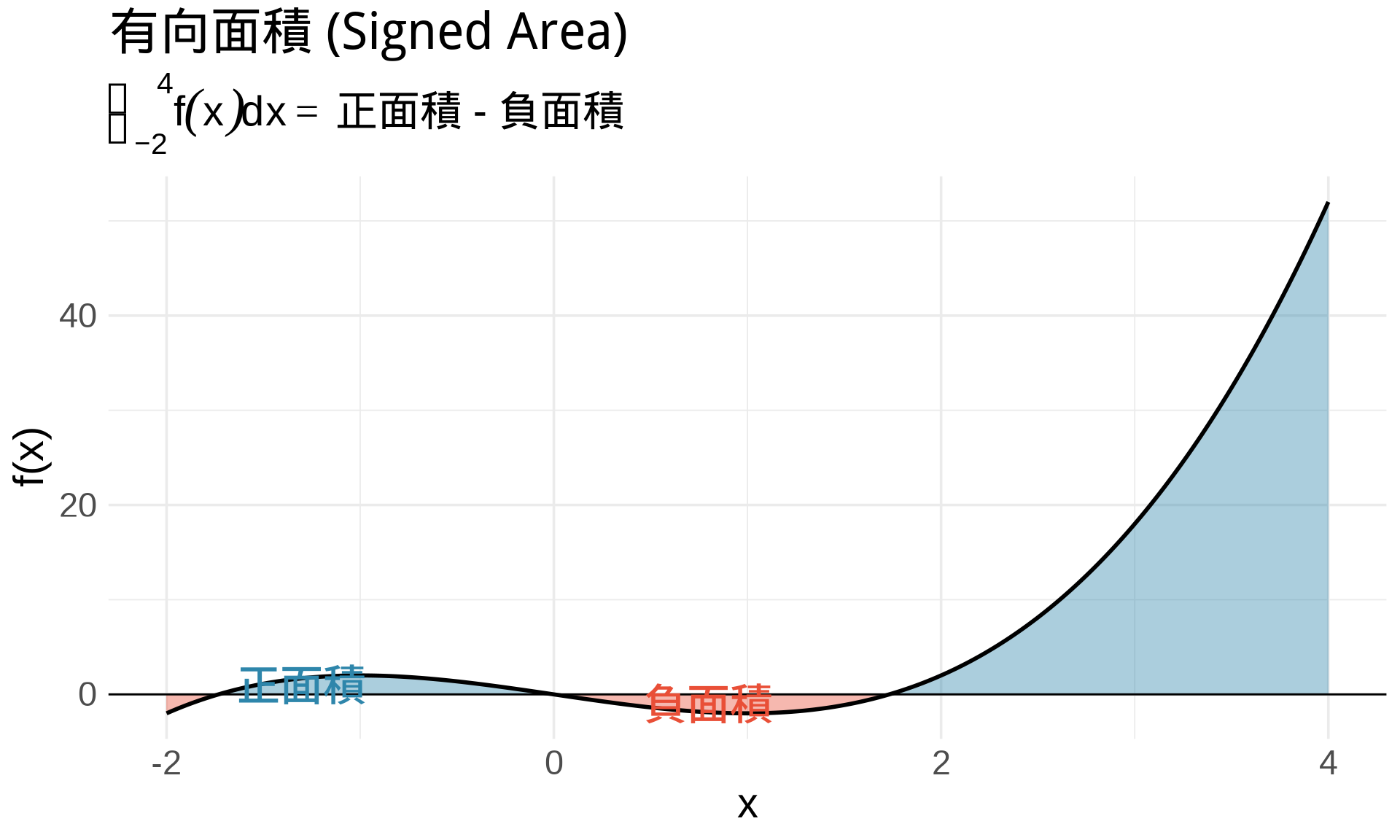
### 幾何意義
$$\int_a^b f(x)dx = \text{函數 } f(x) \text{ 在區間 } [a,b] \text{ 下的**有向面積**}$$
**注意**:
- $f(x) > 0$:面積為正
- $f(x) < 0$:面積為負
- 總積分 = 正面積 - 負面積
```{r}
#| label: fig-signed-area
#| fig-cap: "有向面積:正負面積"
#| warning: false
#| message: false
x <- seq(-2, 4, by = 0.01)
f_x <- x^3 - 3*x
df <- data.frame(x, y = f_x)
# 分離正負區域
df_pos <- df[df$y >= 0, ]
df_neg <- df[df$y < 0, ]
ggplot() +
# 負面積
geom_area(data = df_neg, aes(x, y), fill = "#E94F37", alpha = 0.4) +
# 正面積
geom_area(data = df_pos, aes(x, y), fill = "#2E86AB", alpha = 0.4) +
# 曲線
geom_line(data = df, aes(x, y), linewidth = 1) +
# x 軸
geom_hline(yintercept = 0, color = "black", linewidth = 0.5) +
annotate("text", x = -1.3, y = 1, label = "正面積", size = 5, color = "#2E86AB") +
annotate("text", x = 0.8, y = -1, label = "負面積", size = 5, color = "#E94F37") +
labs(
title = "有向面積 (Signed Area)",
subtitle = expression(integral(f(x)*dx, -2, 4) == "正面積 - 負面積"),
x = "x", y = "f(x)"
) +
theme_minimal(base_size = 14)
```
## 統計應用:機率密度函數 (PDF)
### 核心概念
對於連續型隨機變數 $X$,其機率密度函數 $f(x)$ 滿足 [@casella2002statistical; @degroot2012probability]:
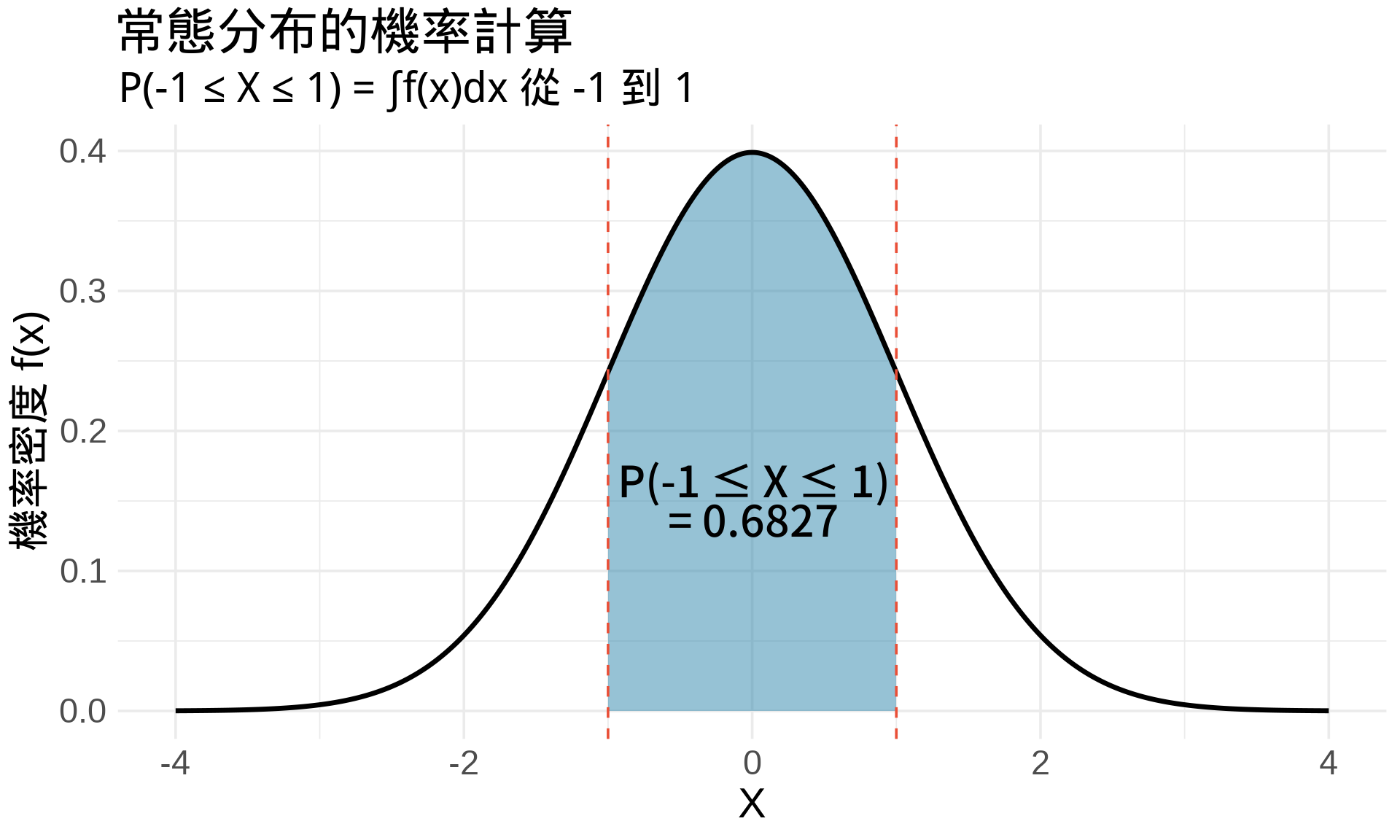
$$P(a \leq X \leq b) = \int_a^b f(x)dx$$
**白話文**:某個區間的機率 = PDF 在該區間下的面積。
### 視覺化:常態分布的機率
```{r}
#| label: fig-normal-probability
#| fig-cap: "常態分布:陰影面積 = 機率"
#| warning: false
#| message: false
x <- seq(-4, 4, by = 0.01)
y <- dnorm(x)
# P(-1 <= X <= 1) 的區域
x_shade <- seq(-1, 1, by = 0.01)
y_shade <- dnorm(x_shade)
prob <- pnorm(1) - pnorm(-1)
ggplot(data.frame(x, y), aes(x, y)) +
# 陰影區域
geom_area(data = data.frame(x = x_shade, y = y_shade),
aes(x, y), fill = "#2E86AB", alpha = 0.5) +
# 完整曲線
geom_line(linewidth = 1.2, color = "black") +
# 標記邊界
geom_vline(xintercept = c(-1, 1), linetype = "dashed", color = "#E94F37") +
annotate("text", x = 0, y = 0.15,
label = paste0("P(-1 ≤ X ≤ 1)\n= ", round(prob, 4)),
size = 5, fontface = "bold") +
labs(
title = "常態分布的機率計算",
subtitle = "P(-1 ≤ X ≤ 1) = ∫f(x)dx 從 -1 到 1",
x = "X",
y = "機率密度 f(x)"
) +
theme_minimal(base_size = 14)
```
**用 R 驗證**:
```{r}
# 方法 1:用 pnorm() 計算 CDF
p1 <- pnorm(1) - pnorm(-1)
print(paste("方法 1 (CDF):", round(p1, 4)))
# 方法 2:數值積分 integrate()
f <- function(x) dnorm(x)
p2 <- integrate(f, lower = -1, upper = 1)$value
print(paste("方法 2 (積分):", round(p2, 4)))
# 兩者幾乎相同!
```
### 為什麼是「密度」而非「機率」?
在連續型隨機變數中:
- $P(X = x) = 0$(單點機率為零)
- $f(x)$ 不是機率,而是「機率密度」
- $f(x) \cdot dx$ 才是「微小區間的機率」
**比喻**:
- $f(x)$ 像是「人口密度」(人/平方公里)
- $\int_a^b f(x)dx$ 是「某區域的總人口」
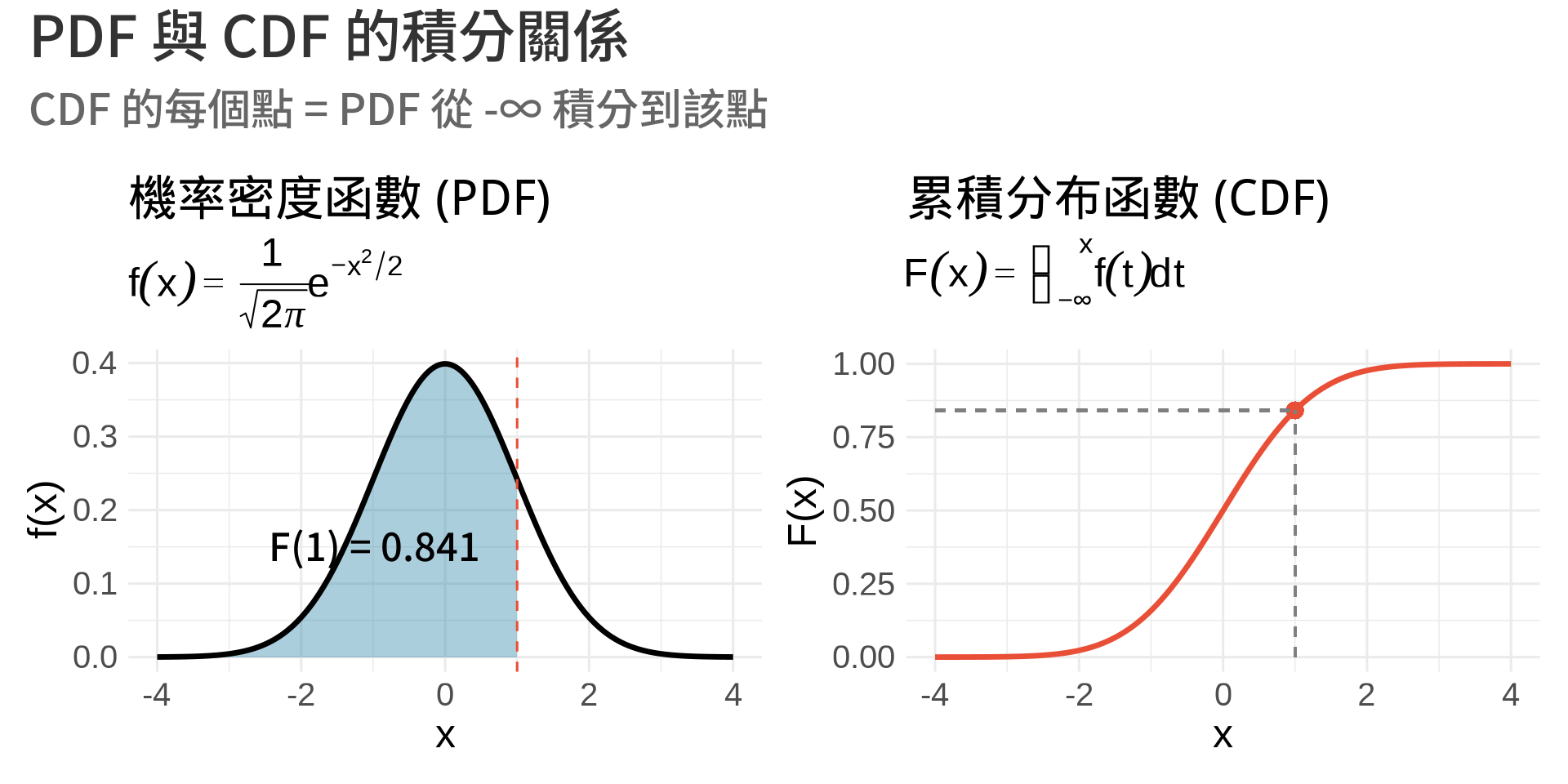
## 累積分布函數 (CDF) 的形成
### 定義
累積分布函數 $F(x)$ 定義為 [@degroot2012probability; @ross2019first]:
$$F(x) = P(X \leq x) = \int_{-\infty}^x f(t)dt$$
這是一個**積分**!
### 視覺化:從 PDF 到 CDF
```{r}
#| label: fig-pdf-to-cdf
#| fig-cap: "PDF 的積分 = CDF"
#| warning: false
#| message: false
#| fig-width: 10
#| fig-height: 5
x <- seq(-4, 4, by = 0.01)
# PDF
pdf_y <- dnorm(x)
# 在某個點 x0 = 1 的陰影
x0 <- 1
x_shade <- seq(-4, x0, by = 0.01)
y_shade <- dnorm(x_shade)
p1 <- ggplot(data.frame(x, y = pdf_y), aes(x, y)) +
geom_area(data = data.frame(x = x_shade, y = y_shade),
aes(x, y), fill = "#2E86AB", alpha = 0.4) +
geom_line(linewidth = 1.2) +
geom_vline(xintercept = x0, linetype = "dashed", color = "#E94F37") +
annotate("text", x = -1, y = 0.15,
label = paste0("F(1) = ", round(pnorm(1), 3)),
size = 4) +
labs(
title = "機率密度函數 (PDF)",
subtitle = expression(f(x) == frac(1, sqrt(2*pi))*e^{-x^2/2}),
x = "x", y = "f(x)"
) +
theme_minimal(base_size = 12)
# CDF
cdf_y <- pnorm(x)
p2 <- ggplot(data.frame(x, y = cdf_y), aes(x, y)) +
geom_line(color = "#E94F37", linewidth = 1.2) +
geom_point(aes(x = x0, y = pnorm(x0)), size = 3, color = "#E94F37") +
geom_segment(aes(x = x0, xend = x0, y = 0, yend = pnorm(x0)),
linetype = "dashed", color = "gray50") +
geom_segment(aes(x = -4, xend = x0, y = pnorm(x0), yend = pnorm(x0)),
linetype = "dashed", color = "gray50") +
labs(
title = "累積分布函數 (CDF)",
subtitle = expression(F(x) == integral(f(t)*dt, -infinity, x)),
x = "x", y = "F(x)"
) +
theme_minimal(base_size = 12)
p1 + p2 +
plot_annotation(
title = "PDF 與 CDF 的積分關係",
subtitle = "CDF 的每個點 = PDF 從 -∞ 積分到該點"
)
```
**關鍵理解**:
- CDF 的**每一個點** $F(x_0)$,都是 PDF 從 $-\infty$ 積分到 $x_0$ 的結果
- 這就是為什麼 CDF 是**單調遞增**的
- CDF 的斜率 = PDF:$F'(x) = f(x)$
## 練習題
### 觀念題
1. 為什麼說「積分是微分的反向操作」?
::: {.callout-tip collapse="true" title="參考答案"}
積分與微分互為反向操作,因為積分求的是「累積量」,而微分求的是「瞬時變化率」。例如:若 $F(x)$ 是 $f(x)$ 的積分(反導數),則 $F'(x) = f(x)$。在統計中,CDF 是 PDF 的積分,而 PDF 是 CDF 的微分:$F(x) = \int_{-\infty}^x f(t)dt$ 且 $F'(x) = f(x)$。
:::
2. 在連續型隨機變數中,為什麼 $P(X = 5) = 0$,但 $P(4.9 < X < 5.1)$ 可能不為零?
::: {.callout-tip collapse="true" title="參考答案"}
單點的機率 $P(X = 5) = \int_5^5 f(x)dx = 0$,因為積分區間寬度為零。但區間機率 $P(4.9 < X < 5.1) = \int_{4.9}^{5.1} f(x)dx$ 有非零的積分區間,所以面積可能不為零。這就像「線」沒有面積,但「帶狀區域」有面積。在連續型隨機變數中,我們關注的是區間機率,而非單點機率。
:::
3. 為什麼所有機率密度函數都滿足 $\int_{-\infty}^{\infty} f(x)dx = 1$?
::: {.callout-tip collapse="true" title="參考答案"}
因為總機率必須等於 1(某個事件一定會發生)。$\int_{-\infty}^{\infty} f(x)dx$ 代表「所有可能值」的機率加總,這個總和必須是 1。這稱為「正規化條件」(normalization condition),確保 $f(x)$ 是一個合法的機率密度函數。
:::
### 計算題
4. 用 R 的 `integrate()` 函數計算 $\int_0^2 x^2 dx$,並驗證答案是否為 $\frac{8}{3}$。
::: {.callout-tip collapse="true" title="參考答案"}
```r
f <- function(x) x^2
result <- integrate(f, lower = 0, upper = 2)
print(result$value) # 應得到 2.666667
print(8/3) # 驗證:8/3 = 2.666667
```
理論解答:$\int_0^2 x^2 dx = \frac{x^3}{3}\Big|_0^2 = \frac{8}{3} - 0 = 2.667$,與數值積分結果相符。
:::
```{r}
#| eval: false
# 提示
f <- function(x) x^2
integrate(f, lower = 0, upper = 2)
```
5. 計算標準常態分布在 $[-2, 2]$ 區間的機率(用兩種方法)。
::: {.callout-tip collapse="true" title="參考答案"}
**方法 1:使用 CDF**
```r
p1 <- pnorm(2) - pnorm(-2)
print(p1) # 約 0.9545
```
**方法 2:使用數值積分**
```r
f <- function(x) dnorm(x)
p2 <- integrate(f, lower = -2, upper = 2)$value
print(p2) # 約 0.9545
```
兩種方法結果相同,約 95.45%。這就是統計學中常說的「95% 信賴區間對應約 ±2 個標準差」的由來。
:::
### R 操作題
6. 修改 Riemann Sum 的程式碼,改用**右端點**而非左端點計算長方形高度,觀察結果有何不同。
::: {.callout-tip collapse="true" title="參考答案"}
將程式碼中的 `x_left <- x_breaks[-(n_rect + 1)]` 改為 `x_right <- x_breaks[-1]`,並使用 `heights <- f(x_right)`。對於遞增函數,右端點會高估面積;對於遞減函數則會低估。但當長方形數量 → ∞ 時,左端點和右端點的結果都會收斂到相同的真實積分值。這說明積分的定義與選擇哪個端點無關。
:::
7. 繪製指數分布 $f(x) = \lambda e^{-\lambda x}$ (其中 $\lambda = 0.5$) 的 PDF 與 CDF,並標記 $P(X \leq 2)$ 的區域。
::: {.callout-tip collapse="true" title="參考答案"}
```r
library(ggplot2)
library(patchwork)
lambda <- 0.5
x <- seq(0, 10, by = 0.01)
# PDF
x_shade <- seq(0, 2, by = 0.01)
p1 <- ggplot(data.frame(x), aes(x)) +
geom_area(data = data.frame(x = x_shade),
aes(x, y = dexp(x_shade, rate = lambda)),
fill = "#2E86AB", alpha = 0.5) +
stat_function(fun = dexp, args = list(rate = lambda), linewidth = 1) +
geom_vline(xintercept = 2, linetype = "dashed", color = "red") +
labs(title = "PDF", y = "f(x)")
# CDF
p2 <- ggplot(data.frame(x), aes(x)) +
stat_function(fun = pexp, args = list(rate = lambda),
color = "#E94F37", linewidth = 1) +
geom_point(aes(x = 2, y = pexp(2, rate = lambda)), size = 3) +
labs(title = "CDF", y = "F(x)")
p1 + p2
print(pexp(2, rate = 0.5)) # P(X ≤ 2) ≈ 0.632
```
:::
```{r}
#| eval: false
# 提示
dexp(x, rate = 0.5) # PDF
pexp(x, rate = 0.5) # CDF
```
## 統計應用
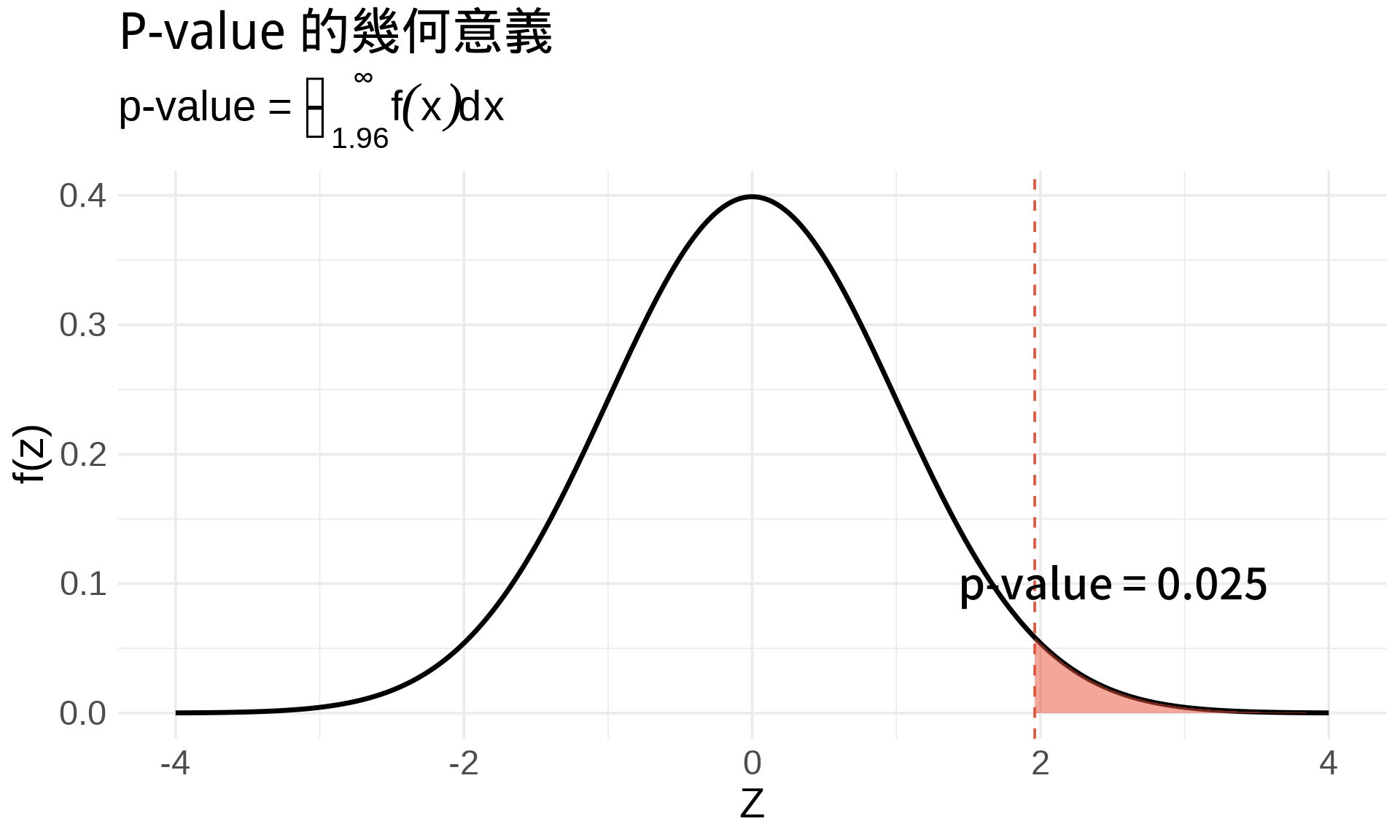
### P-value 就是一個積分
在假設檢定中,p-value 的定義是:
$$\text{p-value} = P(\text{觀察到更極端的結果} | H_0 \text{ 為真})$$
這通常是一個**積分**:
```{r}
#| label: fig-pvalue
#| fig-cap: "P-value = 尾端面積"
#| warning: false
#| message: false
x <- seq(-4, 4, by = 0.01)
y <- dnorm(x)
# 假設觀察到 z = 1.96
z_obs <- 1.96
x_tail <- x[x >= z_obs]
y_tail <- dnorm(x_tail)
pval <- 1 - pnorm(z_obs)
ggplot(data.frame(x, y), aes(x, y)) +
geom_line(linewidth = 1.2) +
geom_area(data = data.frame(x = x_tail, y = y_tail),
aes(x, y), fill = "#E94F37", alpha = 0.5) +
geom_vline(xintercept = z_obs, linetype = "dashed", color = "#E94F37") +
annotate("text", x = 2.5, y = 0.1,
label = paste0("p-value = ", round(pval, 4)),
size = 5, fontface = "bold") +
labs(
title = "P-value 的幾何意義",
subtitle = expression("p-value = " * integral(f(x)*dx, 1.96, infinity)),
x = "Z",
y = "f(z)"
) +
theme_minimal(base_size = 14)
```
## 本章重點整理 {.unnumbered}
1. **積分 = 曲線下面積**,是 Riemann Sum 的極限形式
2. **Riemann Sum**:用長方形近似面積,長方形越多越精確
3. **統計連結**:
- PDF 下的面積 = 機率
- CDF 是 PDF 的積分:$F(x) = \int_{-\infty}^x f(t)dt$
- P-value 就是一個積分值
4. R 函數:`integrate()` 計算數值積分
5. 微積分基本定理:積分與微分互為反向操作
---
**下一章預告**:我們將學習如何**計算積分**——不只是理解概念,還要會實際運算!