# 指數與對數函數 (Exponential & Logarithmic Functions)
```{r}
#| include: false
source(here::here("R/_common.R"))
```
## 學習目標 {.unnumbered}
- 理解 $e$ 的特殊性質:$\frac{d}{dx}e^x = e^x$
- 掌握對數微分:$\frac{d}{dx}\ln x = \frac{1}{x}$
- 認識 log transformation 的效果
- 連結醫學統計:log-likelihood, log-odds, hazard ratio
## 為什麼統計學愛用 $e$ 和 $\ln$?
在統計文獻中,你會不斷看到:
- **Log-likelihood**:為什麼要取對數?
- **Logistic regression**:log-odds 是什麼?
- **Cox regression**:hazard ratio 為什麼要取 log?
- **右偏資料**:為什麼要做 log transformation?
答案都跟 $e$ 和 $\ln$ 的特殊微分性質有關!
## 神奇的數字 $e$
### $e$ 的定義
**自然對數的底 (natural logarithm base)**:
$$
e = \lim_{n \to \infty} \left(1 + \frac{1}{n}\right)^n \approx 2.71828...
$$
或者用另一種定義:
$$
e = \sum_{n=0}^{\infty} \frac{1}{n!} = 1 + 1 + \frac{1}{2} + \frac{1}{6} + \frac{1}{24} + \cdots
$$
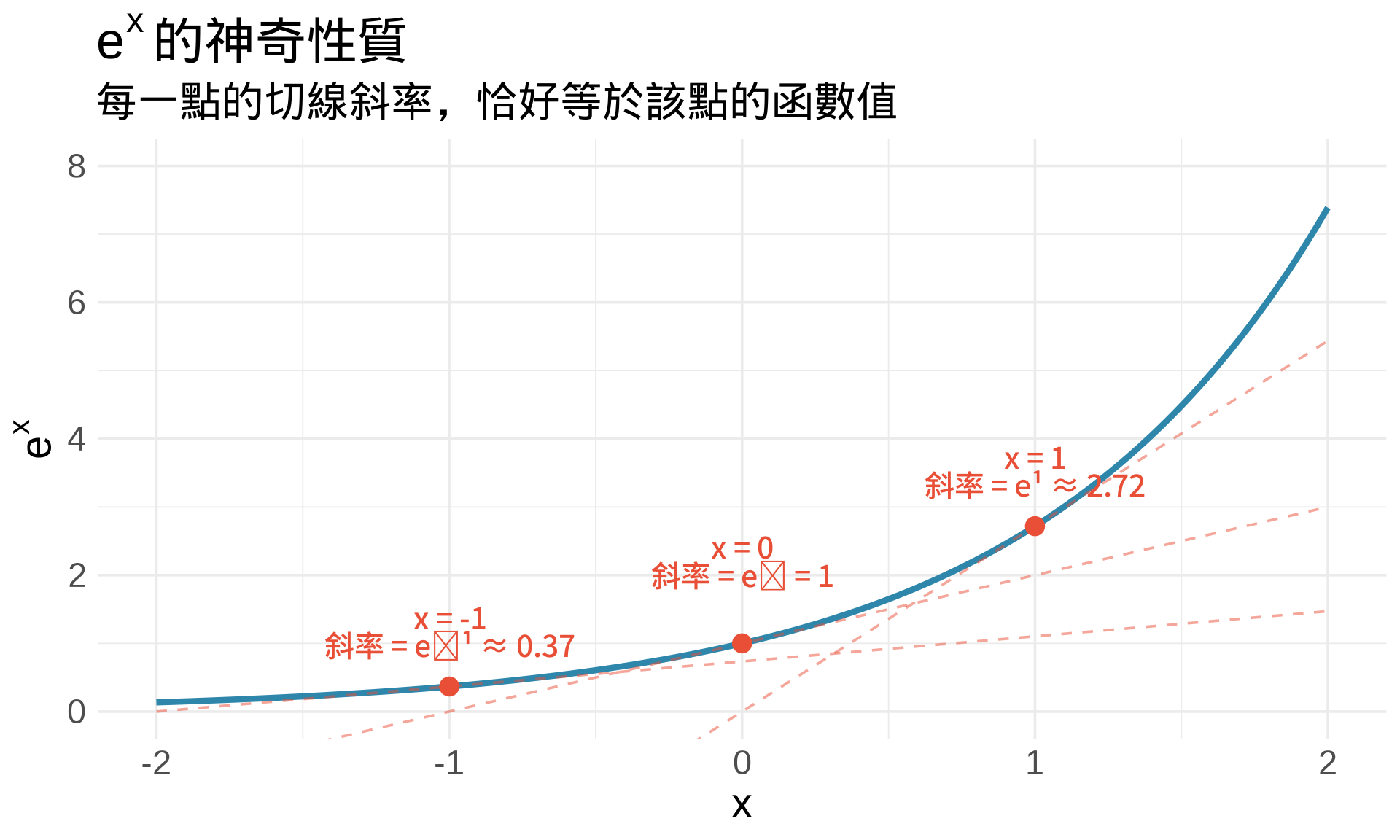
### $e^x$ 的神奇性質
**定理**:
$$
\frac{d}{dx}e^x = e^x
$$
這是 $e$ 最重要的性質:**$e^x$ 是唯一一個導數等於自己的函數!**
```{r}
#| label: fig-exp-derivative
#| fig-cap: "e^x 的神奇性質:每一點的斜率都等於函數值"
#| warning: false
#| message: false
x <- seq(-2, 2, by = 0.01)
y <- exp(x)
# 在幾個點畫切線
points_x <- c(-1, 0, 1)
slopes <- exp(points_x) # 斜率 = e^x
# 切線方程式:y - y0 = slope * (x - x0)
make_tangent <- function(x0, slope) {
y0 <- exp(x0)
function(x) y0 + slope * (x - x0)
}
tangents <- lapply(seq_along(points_x), function(i) {
data.frame(
x = x,
y = make_tangent(points_x[i], slopes[i])(x),
point = i
)
})
tangent_df <- do.call(rbind, tangents)
ggplot() +
# 原函數曲線
geom_line(aes(x = x, y = y), color = "#2E86AB", linewidth = 1.5) +
# 切線
geom_line(data = tangent_df, aes(x = x, y = y, group = point),
color = "#E94F37", alpha = 0.5, linetype = "dashed") +
# 切點
geom_point(aes(x = points_x, y = exp(points_x)),
color = "#E94F37", size = 4) +
# 標註
annotate("text", x = -1, y = exp(-1) + 0.8,
label = paste0("x = -1\n斜率 = e⁻¹ ≈ ", round(exp(-1), 2)),
hjust = 0.5, size = 3.5, color = "#E94F37") +
annotate("text", x = 0, y = exp(0) + 1.2,
label = paste0("x = 0\n斜率 = e⁰ = 1"),
hjust = 0.5, size = 3.5, color = "#E94F37") +
annotate("text", x = 1, y = exp(1) + 0.8,
label = paste0("x = 1\n斜率 = e¹ ≈ ", round(exp(1), 2)),
hjust = 0.5, size = 3.5, color = "#E94F37") +
labs(
title = expression(e^x ~ "的神奇性質"),
subtitle = "每一點的切線斜率,恰好等於該點的函數值",
x = "x", y = expression(e^x)
) +
coord_cartesian(xlim = c(-2, 2), ylim = c(0, 8)) +
theme_minimal(base_size = 14)
```
### 推廣:$e^{kx}$ 的導數
使用連鎖律:
$$
\frac{d}{dx}e^{kx} = ke^{kx}
$$
**範例**:
- $\frac{d}{dx}e^{2x} = 2e^{2x}$
- $\frac{d}{dx}e^{-x} = -e^{-x}$
- $\frac{d}{dx}e^{-0.5t} = -0.5e^{-0.5t}$(藥物代謝)
## 對數函數 $\ln x$
### 對數的定義
**自然對數 (natural logarithm)**:$\ln x$ 是 $e^x$ 的反函數。
$$
y = \ln x \quad \Leftrightarrow \quad e^y = x
$$
**性質**:
- $\ln(e) = 1$
- $\ln(1) = 0$
- $\ln(ab) = \ln(a) + \ln(b)$(乘法變加法!)
- $\ln(a^b) = b\ln(a)$
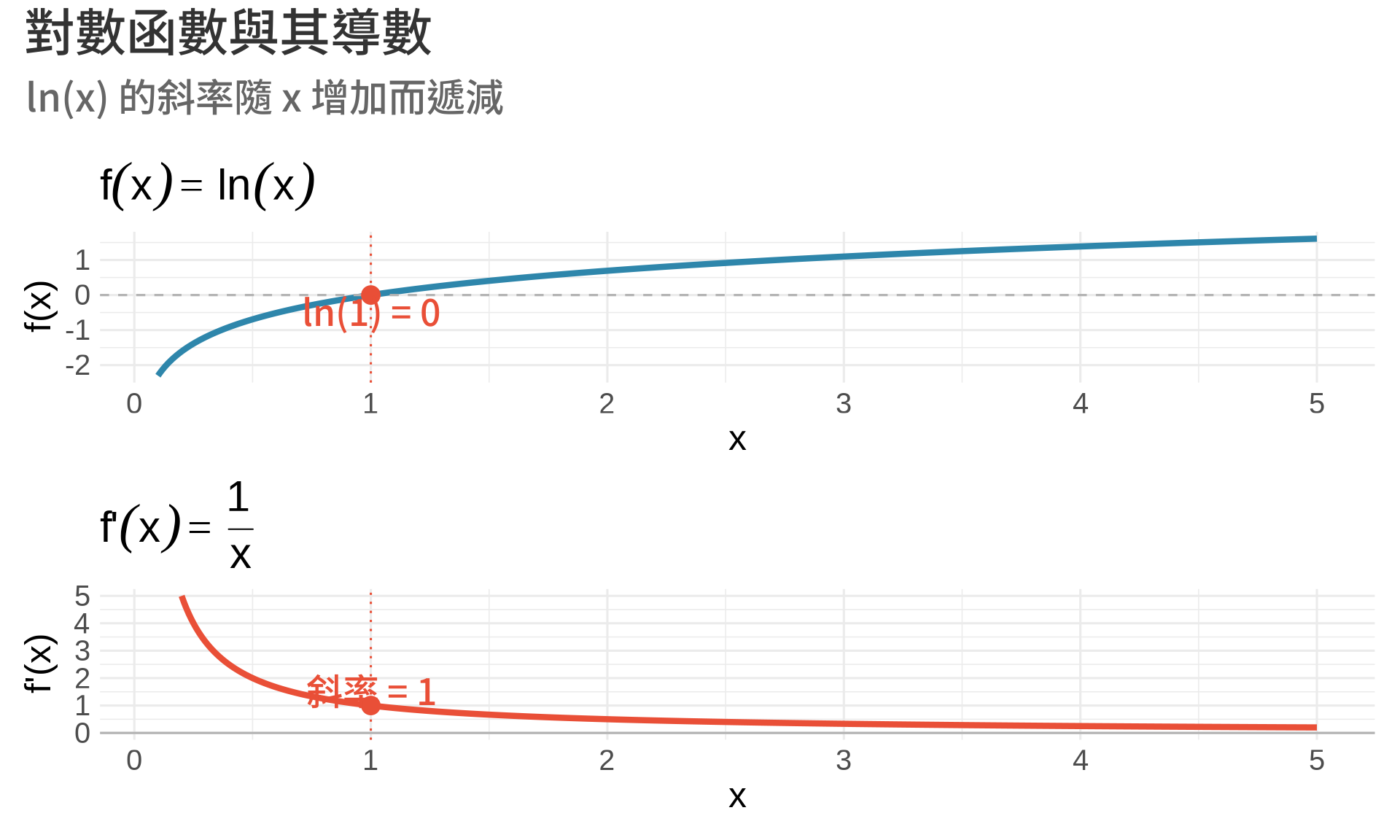
### $\ln x$ 的導數
**定理**:
$$
\frac{d}{dx}\ln x = \frac{1}{x}
$$
```{r}
#| label: fig-log-derivative
#| fig-cap: "ln(x) 與其導數 1/x"
#| warning: false
#| message: false
x <- seq(0.1, 5, by = 0.01)
f <- log(x) # ln(x)
f_prime <- 1/x # d/dx ln(x) = 1/x
df <- data.frame(x, f, f_prime)
p1 <- ggplot(df, aes(x, f)) +
geom_line(color = "#2E86AB", linewidth = 1.5) +
geom_hline(yintercept = 0, color = "gray70", linetype = "dashed") +
geom_vline(xintercept = 1, color = "#E94F37", linetype = "dotted") +
annotate("point", x = 1, y = 0, color = "#E94F37", size = 4) +
annotate("text", x = 1, y = -0.5, label = "ln(1) = 0",
hjust = 0.5, color = "#E94F37") +
labs(title = expression(f(x) == ln(x)), y = "f(x)") +
theme_minimal(base_size = 12)
p2 <- ggplot(df, aes(x, f_prime)) +
geom_line(color = "#E94F37", linewidth = 1.5) +
geom_hline(yintercept = 0, color = "gray70") +
geom_vline(xintercept = 1, color = "#E94F37", linetype = "dotted") +
annotate("point", x = 1, y = 1, color = "#E94F37", size = 4) +
annotate("text", x = 1, y = 1.5, label = "斜率 = 1",
hjust = 0.5, color = "#E94F37") +
labs(title = expression(f*"'"*(x) == frac(1, x)), y = "f'(x)") +
ylim(0, 5) +
theme_minimal(base_size = 12)
p1 / p2 +
plot_annotation(
title = "對數函數與其導數",
subtitle = "ln(x) 的斜率隨 x 增加而遞減"
)
```
**觀察**:
- $\ln x$ 在 $x=1$ 處斜率最大(= 1)
- 隨著 $x$ 增加,斜率越來越小
- $\ln x$ 持續增加,但增加速度越來越慢
### 推廣:$\ln(g(x))$ 的導數
使用連鎖律:
$$
\frac{d}{dx}\ln(g(x)) = \frac{1}{g(x)} \cdot g'(x) = \frac{g'(x)}{g(x)}
$$
**範例**:
$$
\frac{d}{dx}\ln(x^2 + 1) = \frac{2x}{x^2 + 1}
$$
## Log Transformation 的效果
### 為什麼要做 log transformation?
在醫學資料中,很多變數是**右偏 (right-skewed)** 的:
- 醫療費用
- 住院天數
- 病毒量
- 收入
對數轉換可以:
1. **壓縮尺度**:把大範圍壓縮到小範圍
2. **接近常態**:讓右偏分布更對稱
3. **乘法變加法**:$\ln(ab) = \ln a + \ln b$
4. **穩定變異**:讓變異數更穩定
```{r}
#| label: fig-log-transform
#| fig-cap: "Log transformation 的效果:右偏資料變對稱"
#| warning: false
#| message: false
set.seed(42)
# 模擬醫療費用資料(右偏)
cost <- rlnorm(1000, meanlog = 10, sdlog = 1)
df <- data.frame(
cost = cost,
log_cost = log(cost)
)
p1 <- ggplot(df, aes(cost)) +
geom_histogram(fill = "#2E86AB", color = "white", bins = 50) +
geom_vline(xintercept = median(cost), color = "#E94F37",
linewidth = 1, linetype = "dashed") +
annotate("text", x = median(cost), y = 80,
label = paste0("中位數 = ", scales::comma(round(median(cost)))),
hjust = -0.1, color = "#E94F37") +
labs(
title = "原始資料:醫療費用",
subtitle = "嚴重右偏",
x = "費用(元)", y = "次數"
) +
scale_x_continuous(labels = scales::comma) +
theme_minimal(base_size = 12)
p2 <- ggplot(df, aes(log_cost)) +
geom_histogram(fill = "#E94F37", color = "white", bins = 50) +
geom_vline(xintercept = median(log(cost)), color = "#2E86AB",
linewidth = 1, linetype = "dashed") +
annotate("text", x = median(log(cost)), y = 80,
label = paste0("中位數 = ", round(median(log(cost)), 2)),
hjust = -0.1, color = "#2E86AB") +
labs(
title = "Log 轉換後",
subtitle = "接近常態分布",
x = "log(費用)", y = "次數"
) +
theme_minimal(base_size = 12)
p1 / p2 +
plot_annotation(
title = "Log Transformation 的威力",
subtitle = "右偏資料經過 log 轉換後更對稱、更接近常態"
)
```
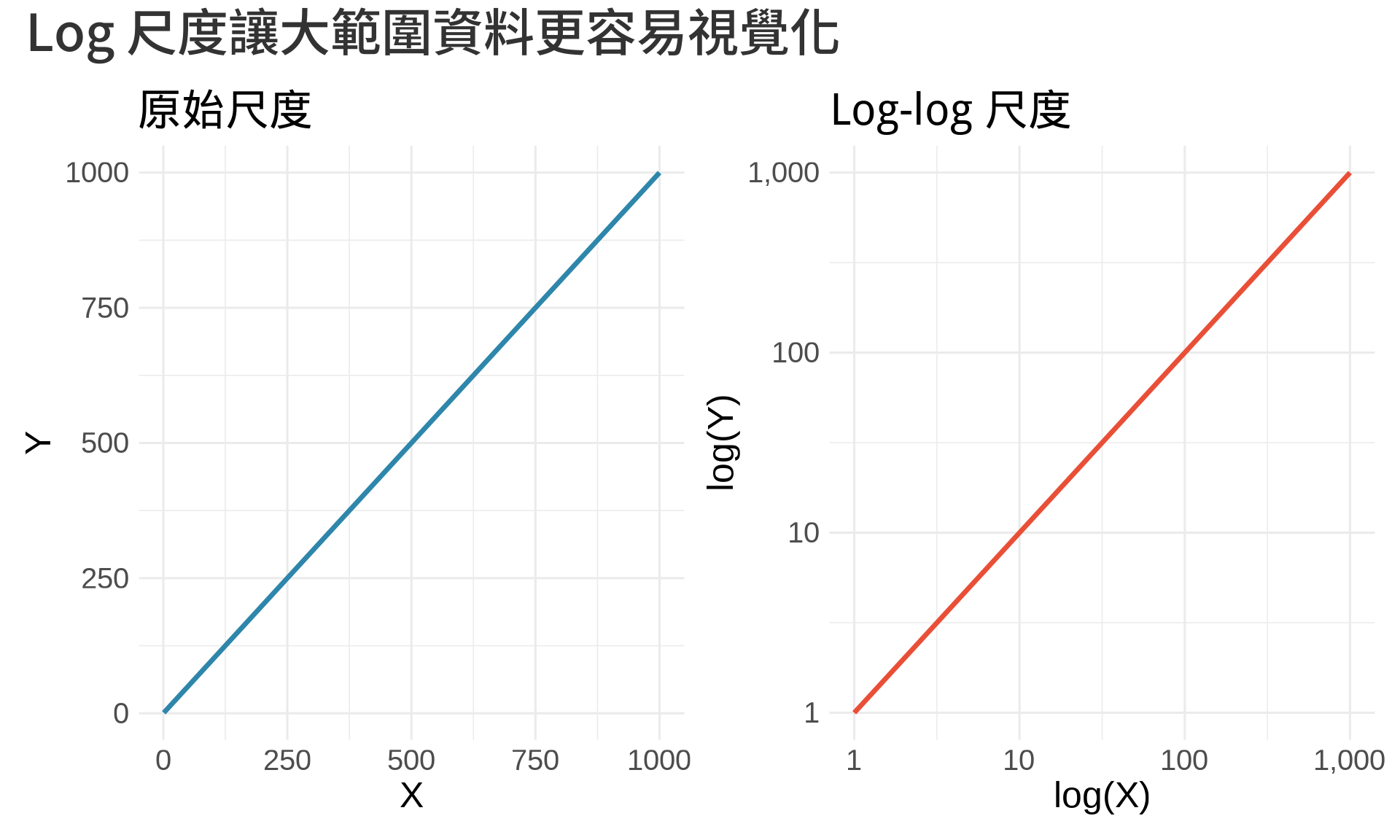
### Log transformation 的視覺效果
```{r}
#| label: fig-log-scale
#| fig-cap: "原始尺度 vs. Log 尺度"
#| warning: false
#| message: false
x <- seq(1, 1000, by = 1)
y <- x # 假設是線性關係
df <- data.frame(x, y)
p1 <- ggplot(df, aes(x, y)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
labs(
title = "原始尺度",
x = "X", y = "Y"
) +
theme_minimal(base_size = 12)
p2 <- ggplot(df, aes(x, y)) +
geom_line(color = "#E94F37", linewidth = 1.2) +
scale_x_log10(labels = scales::comma) +
scale_y_log10(labels = scales::comma) +
labs(
title = "Log-log 尺度",
x = "log(X)", y = "log(Y)"
) +
theme_minimal(base_size = 12)
p1 + p2 +
plot_annotation(
title = "Log 尺度讓大範圍資料更容易視覺化"
)
```
## 統計應用
### 1. Log-likelihood
在最大概似估計中,我們常對 likelihood 取對數:
$$
\ell(\theta) = \ln L(\theta) = \ln \prod_{i=1}^n f(x_i; \theta) = \sum_{i=1}^n \ln f(x_i; \theta)
$$
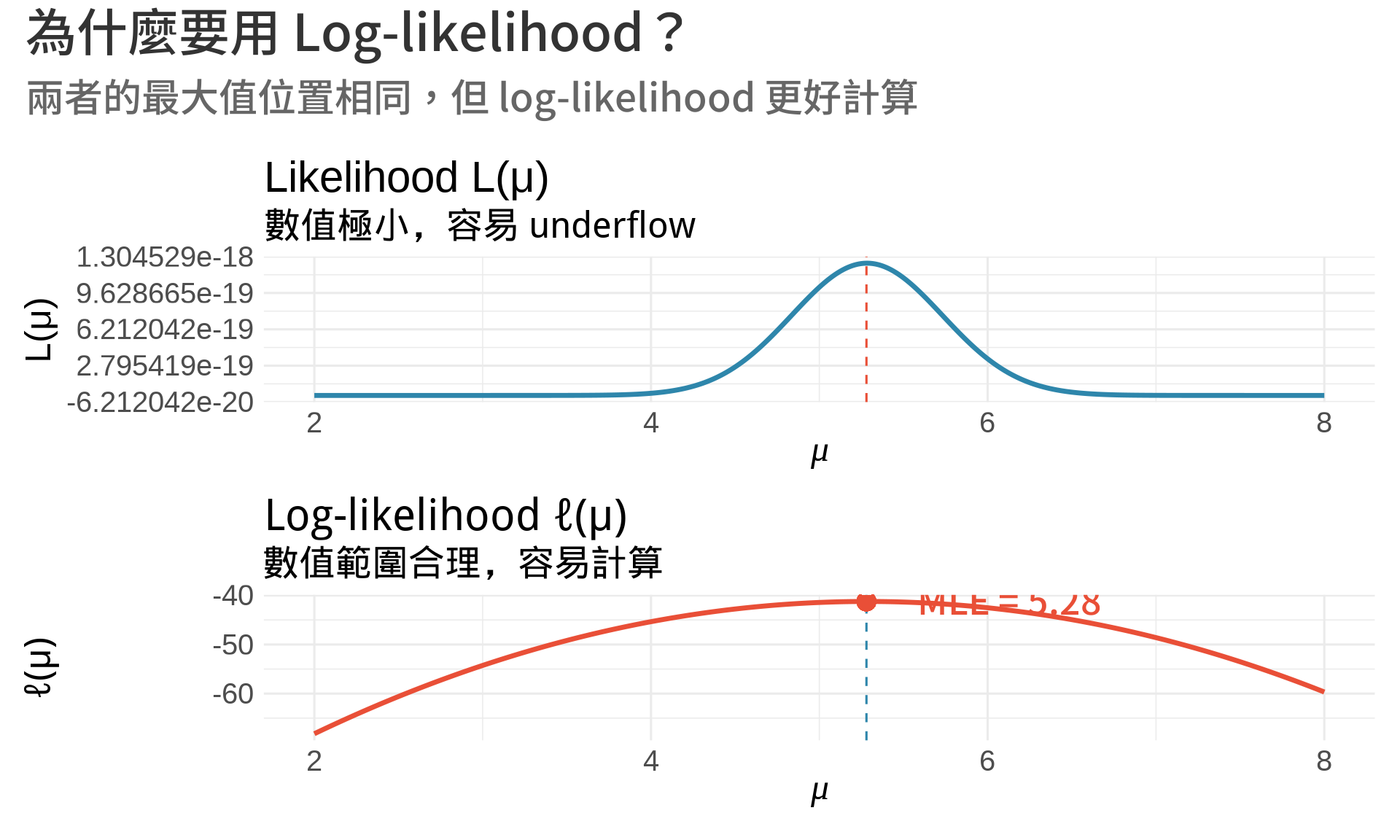
**為什麼要取 log?**
1. **乘法變加法**:$\ln(ab) = \ln a + \ln b$
2. **數值穩定**:很多小數相乘會 underflow,取 log 避免此問題
3. **微分簡單**:$\frac{d}{d\theta}\ln L(\theta)$ 比 $\frac{d}{d\theta}L(\theta)$ 容易計算
4. **保持單調性**:$\ln$ 是單調遞增函數,最大值位置不變
```{r}
#| label: fig-log-likelihood
#| fig-cap: "Likelihood vs. Log-likelihood"
#| warning: false
#| message: false
# 假設觀察到的資料
set.seed(123)
data <- rnorm(20, mean = 5, sd = 2)
# Likelihood 函數(固定 sigma = 2)
likelihood <- function(mu) {
prod(dnorm(data, mean = mu, sd = 2))
}
# Log-likelihood 函數
log_lik <- function(mu) {
sum(dnorm(data, mean = mu, sd = 2, log = TRUE))
}
mu_range <- seq(2, 8, by = 0.01)
L_values <- sapply(mu_range, likelihood)
ll_values <- sapply(mu_range, log_lik)
# MLE
mu_mle <- mu_range[which.max(ll_values)]
df <- data.frame(mu = mu_range, L = L_values, ll = ll_values)
p1 <- ggplot(df, aes(mu, L)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
geom_vline(xintercept = mu_mle, color = "#E94F37", linetype = "dashed") +
labs(
title = "Likelihood L(μ)",
subtitle = "數值極小,容易 underflow",
x = expression(mu), y = "L(μ)"
) +
theme_minimal(base_size = 12)
p2 <- ggplot(df, aes(mu, ll)) +
geom_line(color = "#E94F37", linewidth = 1.2) +
geom_vline(xintercept = mu_mle, color = "#2E86AB", linetype = "dashed") +
geom_point(aes(x = mu_mle, y = max(ll_values)),
color = "#E94F37", size = 4) +
annotate("text", x = mu_mle + 0.3, y = max(ll_values),
label = paste0("MLE = ", round(mu_mle, 2)),
hjust = 0, color = "#E94F37") +
labs(
title = "Log-likelihood ℓ(μ)",
subtitle = "數值範圍合理,容易計算",
x = expression(mu), y = "ℓ(μ)"
) +
theme_minimal(base_size = 12)
p1 / p2 +
plot_annotation(
title = "為什麼要用 Log-likelihood?",
subtitle = "兩者的最大值位置相同,但 log-likelihood 更好計算"
)
```
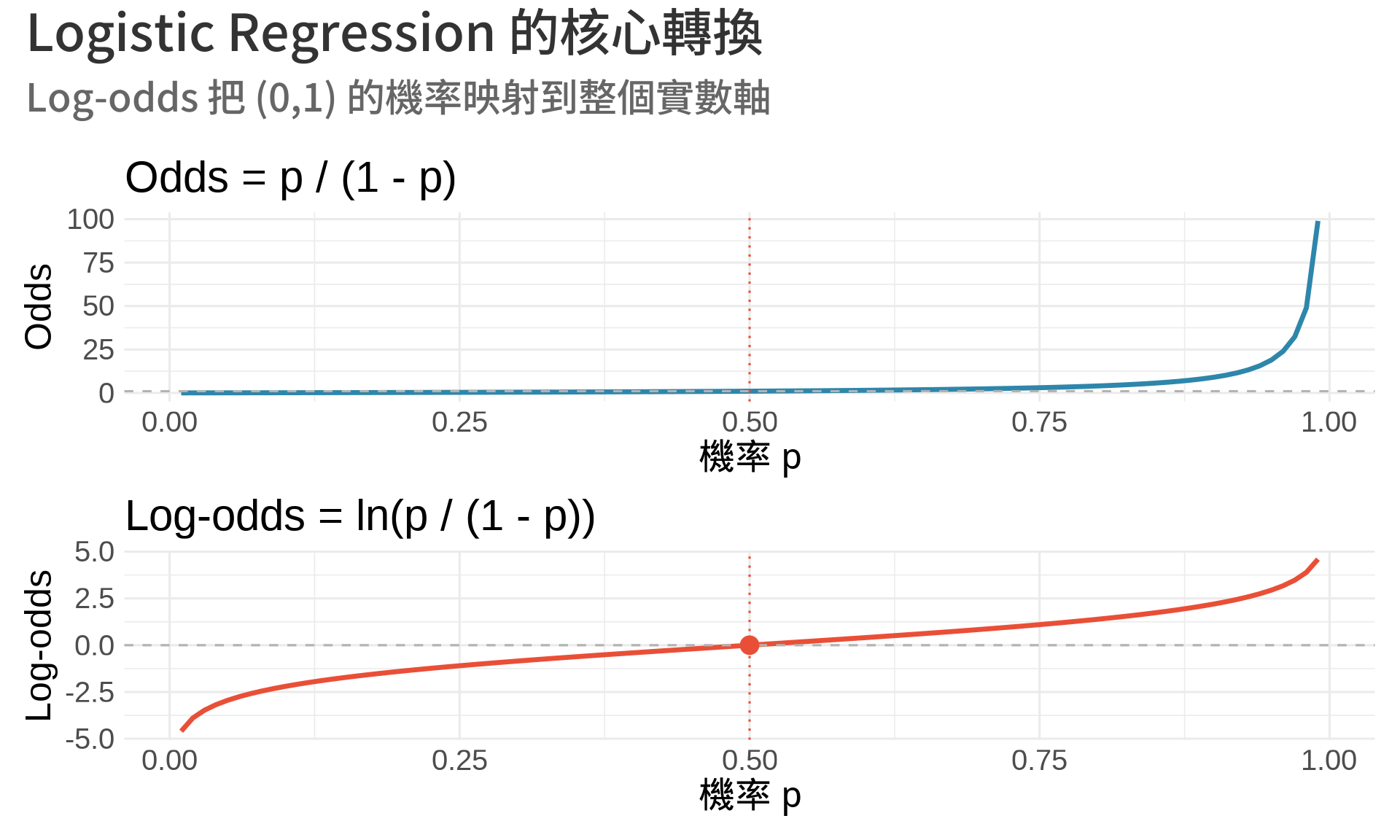
### 2. Logistic Regression 的 Log-odds
**Logistic regression** 模型:
$$
\ln\left(\frac{p}{1-p}\right) = \beta_0 + \beta_1 x_1 + \cdots + \beta_k x_k
$$
左邊叫做 **log-odds** 或 **logit**。
**為什麼要取 log?**
- 機率 $p \in (0, 1)$,範圍受限
- Odds $= \frac{p}{1-p} \in (0, \infty)$,範圍是正數
- Log-odds $= \ln\left(\frac{p}{1-p}\right) \in (-\infty, \infty)$,範圍是全實數
這樣就可以用線性模型了!
```{r}
#| label: fig-log-odds
#| fig-cap: "機率 → Odds → Log-odds 的轉換"
#| warning: false
#| message: false
p <- seq(0.01, 0.99, by = 0.01)
odds <- p / (1 - p)
log_odds <- log(odds)
df <- data.frame(p, odds, log_odds)
p1 <- ggplot(df, aes(p, odds)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
geom_hline(yintercept = 1, color = "gray70", linetype = "dashed") +
geom_vline(xintercept = 0.5, color = "#E94F37", linetype = "dotted") +
labs(
title = "Odds = p / (1 - p)",
x = "機率 p", y = "Odds"
) +
theme_minimal(base_size = 12)
p2 <- ggplot(df, aes(p, log_odds)) +
geom_line(color = "#E94F37", linewidth = 1.2) +
geom_hline(yintercept = 0, color = "gray70", linetype = "dashed") +
geom_vline(xintercept = 0.5, color = "#E94F37", linetype = "dotted") +
annotate("point", x = 0.5, y = 0, color = "#E94F37", size = 4) +
labs(
title = "Log-odds = ln(p / (1 - p))",
x = "機率 p", y = "Log-odds"
) +
theme_minimal(base_size = 12)
p1 / p2 +
plot_annotation(
title = "Logistic Regression 的核心轉換",
subtitle = "Log-odds 把 (0,1) 的機率映射到整個實數軸"
)
```
### 3. Cox Regression 的 Hazard Ratio
**Cox proportional hazards model**:
$$
h(t|X) = h_0(t) \cdot \exp(\beta_1 X_1 + \cdots + \beta_k X_k)
$$
兩組的 **hazard ratio (HR)**:
$$
\text{HR} = \frac{h(t|X=1)}{h(t|X=0)} = e^{\beta}
$$
**Log hazard ratio**:
$$
\ln(\text{HR}) = \beta
$$
迴歸係數 $\beta$ 就是 log hazard ratio!
- 如果 HR = 2,代表風險是 2 倍,$\beta = \ln(2) \approx 0.69$
- 如果 HR = 0.5,代表風險是一半,$\beta = \ln(0.5) \approx -0.69$
## 練習題
### 觀念題
1. 用自己的話解釋:為什麼 $e^x$ 的導數等於自己很特別?
::: {.callout-tip collapse="true" title="參考答案"}
大部分函數的導數(斜率)都會隨著 x 改變,但 $e^x$ 很神奇:在任何一點,它的斜率都恰好等於該點的函數值。這使得 $e^x$ 在描述「變化率與當前狀態成正比」的現象時非常好用,例如人口成長、放射性衰變、藥物濃度下降等。
:::
2. 為什麼統計學要對 likelihood 取對數?列出至少三個理由。
::: {.callout-tip collapse="true" title="參考答案"}
三個主要理由:(1) **乘法變加法**:多個機率的乘積變成對數的和,計算更簡單;(2) **數值穩定**:很多小數相乘會造成 underflow,取 log 可避免;(3) **微分容易**:log-likelihood 的導數形式比原始 likelihood 簡單得多,方便求最大值。此外,log 是單調遞增函數,最大值位置不變。
:::
3. 在 logistic regression 中,為什麼要用 log-odds 而不是直接用機率?
::: {.callout-tip collapse="true" title="參考答案"}
機率 $p$ 的範圍被限制在 $(0, 1)$,無法直接用線性模型(線性模型的值域是全實數)。透過轉換:機率 → odds ($\frac{p}{1-p}$) → log-odds ($\ln\frac{p}{1-p}$),將範圍從 $(0,1)$ 映射到 $(-\infty, \infty)$,這樣就可以用線性模型來建模了。
:::
### 計算題
4. 計算下列函數的導數:
a. $f(x) = e^{3x}$
b. $g(x) = \ln(2x + 1)$
c. $h(x) = x^2 e^x$(使用乘法規則)
::: {.callout-tip collapse="true" title="參考答案"}
a. 使用連鎖律:$f'(x) = 3e^{3x}$
b. 使用連鎖律:$g'(x) = \frac{1}{2x+1} \cdot 2 = \frac{2}{2x+1}$
c. 使用乘法規則 $(uv)' = u'v + uv'$:$h'(x) = 2x \cdot e^x + x^2 \cdot e^x = (2x + x^2)e^x = x(2 + x)e^x$
:::
5. 如果 HR = 1.5,計算 log HR(即 $\beta$)。
::: {.callout-tip collapse="true" title="參考答案"}
$\beta = \ln(\text{HR}) = \ln(1.5) \approx 0.405$。可用 R 驗證:`log(1.5)`。這表示在 Cox regression 中,如果某個變數的 HR 是 1.5(風險增加 50%),其對應的迴歸係數約為 0.405。
:::
6. 驗證:$\frac{d}{dx}[\ln(x^2)] = \frac{2}{x}$
::: {.callout-tip collapse="true" title="參考答案"}
方法一(連鎖律):$\frac{d}{dx}\ln(x^2) = \frac{1}{x^2} \cdot 2x = \frac{2x}{x^2} = \frac{2}{x}$ ✓
方法二(對數性質):$\ln(x^2) = 2\ln(x)$,所以 $\frac{d}{dx}[2\ln(x)] = 2 \cdot \frac{1}{x} = \frac{2}{x}$ ✓
:::
### R 操作題
7. 模擬一組右偏資料,繪製 log transformation 前後的直方圖。
::: {.callout-tip collapse="true" title="參考答案"}
```r
set.seed(123)
data <- rlnorm(1000, meanlog = 5, sdlog = 1)
# 原始資料
hist(data, breaks = 50, col = "#2E86AB",
main = "原始資料(右偏)", xlab = "值")
# Log 轉換後
hist(log(data), breaks = 50, col = "#E94F37",
main = "Log 轉換後(更對稱)", xlab = "log(值)")
```
參數說明:`meanlog` 和 `sdlog` 控制分布的位置和離散程度,數值越大越右偏。
:::
```{r}
#| eval: false
set.seed(___)
data <- rlnorm(1000, meanlog = ___, sdlog = ___)
# 繪製 histogram
```
8. 繪製 $f(x) = xe^{-x}$ 及其導數,找出極值點。
::: {.callout-tip collapse="true" title="參考答案"}
先求導數:使用乘法規則,$f'(x) = e^{-x} + x \cdot (-e^{-x}) = e^{-x}(1-x)$。令 $f'(x) = 0$ 得 $x = 1$。
```r
x <- seq(0, 5, by = 0.01)
f <- x * exp(-x)
f_prime <- exp(-x) * (1 - x)
# 繪製函數
plot(x, f, type = "l", col = "#2E86AB", lwd = 2,
ylab = "y", main = "f(x) = x·e^(-x) 及其導數")
lines(x, f_prime, col = "#E94F37", lwd = 2)
abline(v = 1, lty = 2, col = "gray")
abline(h = 0, lty = 2, col = "gray")
legend("topright", c("f(x)", "f'(x)"), col = c("#2E86AB", "#E94F37"), lwd = 2)
```
極值點在 $x = 1$,$f(1) = e^{-1} \approx 0.368$(極大值)。
:::
## 本章重點整理 {.unnumbered}
:::{.callout-important}
## 核心概念
**微分公式**:
1. $\frac{d}{dx}e^x = e^x$ —— $e^x$ 是唯一導數等於自己的函數
2. $\frac{d}{dx}e^{kx} = ke^{kx}$
3. $\frac{d}{dx}\ln x = \frac{1}{x}$
4. $\frac{d}{dx}\ln(g(x)) = \frac{g'(x)}{g(x)}$
**為什麼統計學愛用 log**:
1. **Log-likelihood**:乘法變加法、數值穩定、微分簡單
2. **Logistic regression**:log-odds 把 (0,1) 映射到全實數
3. **Cox regression**:log HR 就是迴歸係數
4. **Data transformation**:讓右偏資料更對稱
**下一章**:我們會用導數來解決最佳化問題——找出讓函數最大或最小的點!
:::