---
title: "Chapter 9: 積分技巧"
---
```{r}
#| include: false
source(here::here("R/_common.R"))
```
## 學習目標 {.unnumbered}
- 學習基本積分公式
- 理解換元積分法 (Substitution Method)
- 了解分部積分法 (Integration by Parts) 的基本概念
- 應用積分計算期望值與累積機率
## 為什麼需要學積分技巧?
在上一章,我們理解了積分的**概念**:曲線下面積。但在實際統計應用中,我們需要**計算**這些面積:
- 計算機率:$P(a \leq X \leq b) = \int_a^b f(x)dx$
- 計算期望值:$E(X) = \int_{-\infty}^{\infty} x \cdot f(x)dx$
- 驗證分布的正規化:$\int_{-\infty}^{\infty} f(x)dx = 1$
這就需要**積分技巧**!
## 基本積分公式
### 不定積分 vs 定積分
**不定積分 (Indefinite Integral)**:找反導數
$$\int f(x)dx = F(x) + C$$
其中 $F'(x) = f(x)$,$C$ 是任意常數。
**定積分 (Definite Integral)**:計算面積
$$\int_a^b f(x)dx = F(b) - F(a)$$
這就是**微積分基本定理 (Fundamental Theorem of Calculus)** [@stewart2015calculus; @thomas2018calculus]!
### 常用積分公式表
| 函數 $f(x)$ | 不定積分 $\int f(x)dx$ | 說明 |
|------------|----------------------|------|
| $k$ (常數) | $kx + C$ | 常數積分 |
| $x^n$ | $\frac{x^{n+1}}{n+1} + C$ | 冪次積分 ($n \neq -1$) |
| $\frac{1}{x}$ | $\ln|x| + C$ | 重要! |
| $e^x$ | $e^x + C$ | 指數函數 |
| $e^{ax}$ | $\frac{1}{a}e^{ax} + C$ | 一般指數 |
| $\sin x$ | $-\cos x + C$ | 三角函數 |
| $\cos x$ | $\sin x + C$ | 三角函數 |
**記憶技巧**:積分公式大多是微分公式的「反向」!
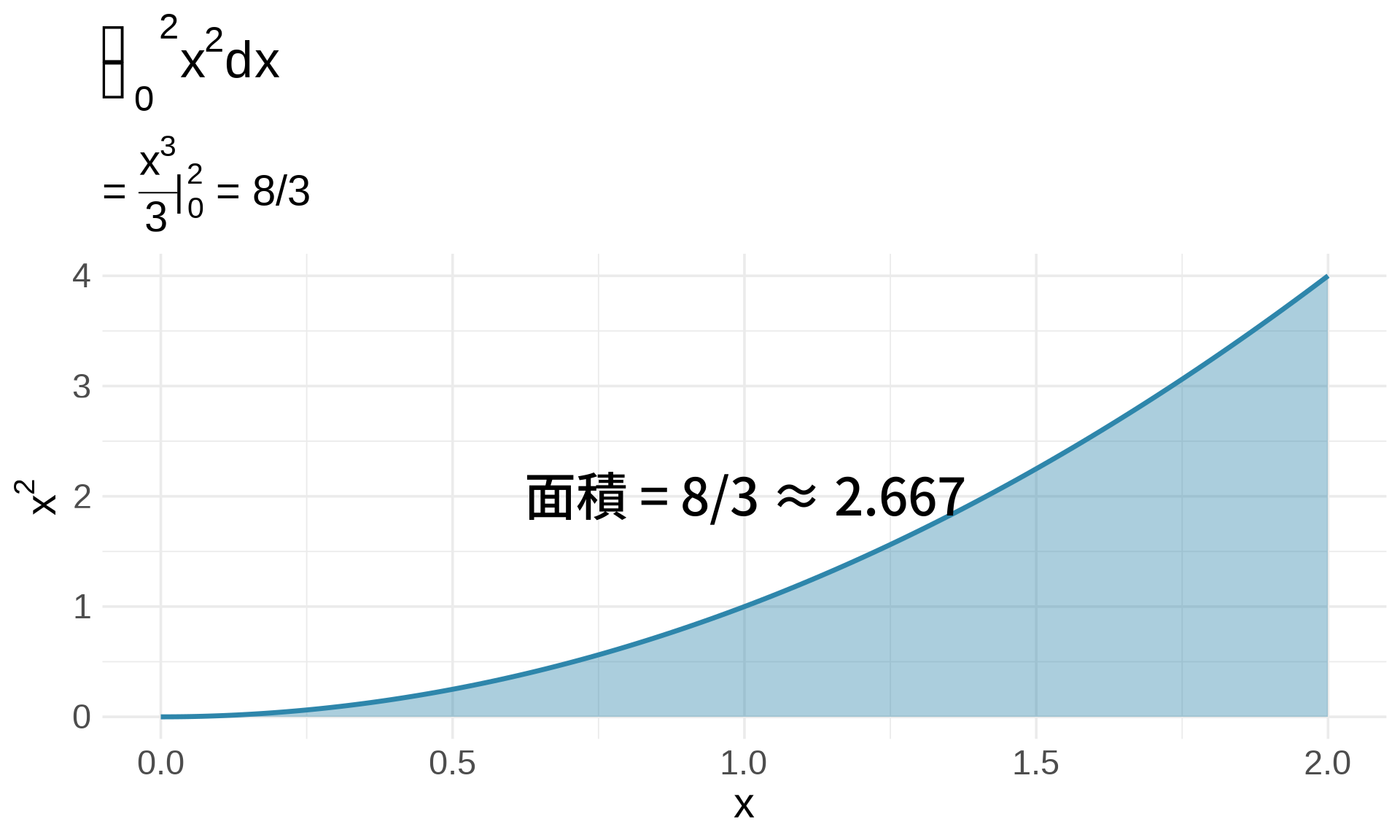
### 範例:冪次積分
**問題**:計算 $\int_0^2 x^2 dx$
**解答**:
$$\int_0^2 x^2 dx = \left[\frac{x^3}{3}\right]_0^2 = \frac{2^3}{3} - \frac{0^3}{3} = \frac{8}{3}$$
**R 驗證**:
```{r}
# 方法 1:手算
area_manual <- 8/3
print(paste("手算結果:", round(area_manual, 4)))
# 方法 2:數值積分
f <- function(x) x^2
area_integrate <- integrate(f, lower = 0, upper = 2)$value
print(paste("R 積分:", round(area_integrate, 4)))
# 幾乎相同!
```
**視覺化**:
```{r}
#| label: fig-power-integral
#| fig-cap: "冪次積分:x² 的面積"
#| warning: false
#| message: false
x <- seq(0, 2, by = 0.01)
y <- x^2
ggplot(data.frame(x, y), aes(x, y)) +
geom_area(fill = "#2E86AB", alpha = 0.4) +
geom_line(linewidth = 1.2, color = "#2E86AB") +
annotate("text", x = 1, y = 2,
label = paste0("面積 = 8/3 ≈ ", round(8/3, 3)),
size = 6, fontface = "bold") +
labs(
title = expression(integral(x^2*dx, 0, 2)),
subtitle = expression("= " * frac(x^3, 3) * "|"[0]^2 * " = 8/3"),
x = "x", y = expression(x^2)
) +
theme_minimal(base_size = 14)
```
## 換元積分法 (Substitution Method)
### 概念
換元積分法是**連鎖律 (Chain Rule)** 的反向操作。
**連鎖律(微分)**:
$$\frac{d}{dx}[f(g(x))] = f'(g(x)) \cdot g'(x)$$
**換元法(積分)**:
$$\int f'(g(x)) \cdot g'(x)dx = f(g(x)) + C$$
### 步驟
1. 令 $u = g(x)$
2. 計算 $du = g'(x)dx$
3. 代換:$\int f(u)du$
4. 積分後代回原變數
### 範例:計算 $\int 2x e^{x^2} dx$
**解答**:
1. 令 $u = x^2$
2. $du = 2x dx$
3. 原式變成 $\int e^u du = e^u + C$
4. 代回:$e^{x^2} + C$
**R 驗證**:
```{r}
# 定義原函數
f <- function(x) 2*x * exp(x^2)
# 數值積分(0 到 1)
area <- integrate(f, lower = 0, upper = 1)$value
# 用公式算(F(1) - F(0))
F <- function(x) exp(x^2)
area_formula <- F(1) - F(0)
cat("數值積分:", round(area, 5), "\n")
cat("公式計算:", round(area_formula, 5), "\n")
```
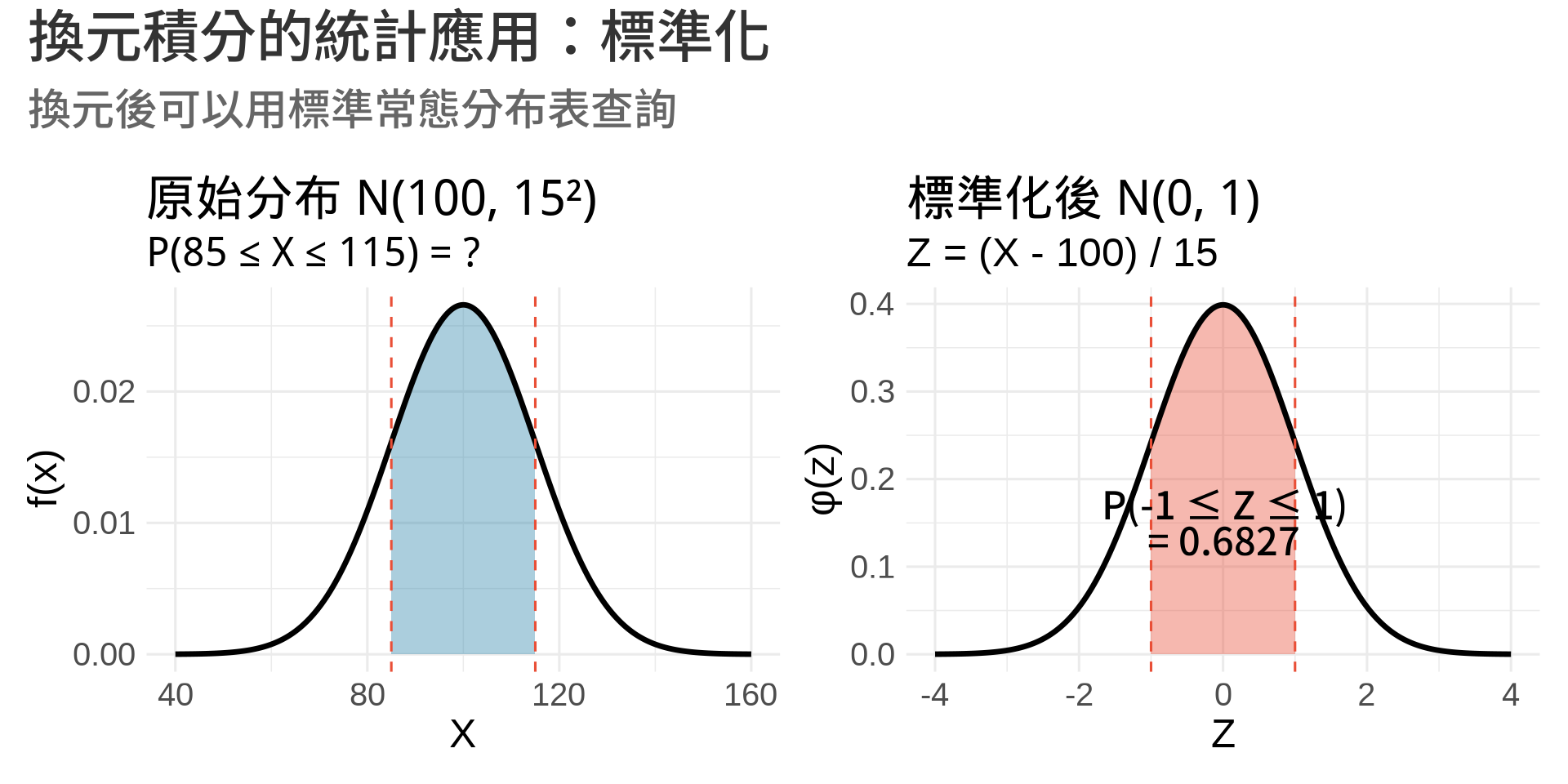
### 統計應用:常態分布的標準化
計算 $P(a \leq X \leq b)$ 當 $X \sim N(\mu, \sigma^2)$:
$$P(a \leq X \leq b) = \int_a^b \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}dx$$
**換元**:令 $z = \frac{x-\mu}{\sigma}$,$dz = \frac{1}{\sigma}dx$
$$= \int_{(a-\mu)/\sigma}^{(b-\mu)/\sigma} \frac{1}{\sqrt{2\pi}} e^{-z^2/2}dz$$
這就是為什麼我們可以用**標準常態分布表**!
```{r}
#| label: fig-standardization
#| fig-cap: "常態分布的標準化"
#| warning: false
#| message: false
#| fig-width: 10
#| fig-height: 5
# 原始分布 N(100, 15²)
mu <- 100
sigma <- 15
x1 <- seq(mu - 4*sigma, mu + 4*sigma, by = 0.1)
y1 <- dnorm(x1, mean = mu, sd = sigma)
# 標記區間 [85, 115]
a <- 85
b <- 115
x1_shade <- seq(a, b, by = 0.1)
y1_shade <- dnorm(x1_shade, mean = mu, sd = sigma)
p1 <- ggplot(data.frame(x1, y1), aes(x1, y1)) +
geom_area(data = data.frame(x = x1_shade, y = y1_shade),
aes(x, y), fill = "#2E86AB", alpha = 0.4) +
geom_line(linewidth = 1.2) +
geom_vline(xintercept = c(a, b), linetype = "dashed", color = "#E94F37") +
labs(
title = "原始分布 N(100, 15²)",
subtitle = "P(85 ≤ X ≤ 115) = ?",
x = "X", y = "f(x)"
) +
theme_minimal(base_size = 12)
# 標準化後 N(0, 1)
z_a <- (a - mu) / sigma
z_b <- (b - mu) / sigma
z <- seq(-4, 4, by = 0.01)
y2 <- dnorm(z)
z_shade <- seq(z_a, z_b, by = 0.01)
y2_shade <- dnorm(z_shade)
p2 <- ggplot(data.frame(z, y2), aes(z, y2)) +
geom_area(data = data.frame(z = z_shade, y = y2_shade),
aes(z, y), fill = "#E94F37", alpha = 0.4) +
geom_line(linewidth = 1.2) +
geom_vline(xintercept = c(z_a, z_b), linetype = "dashed", color = "#E94F37") +
annotate("text", x = 0, y = 0.15,
label = paste0("P(", round(z_a, 2), " ≤ Z ≤ ", round(z_b, 2), ")\n= ",
round(pnorm(z_b) - pnorm(z_a), 4)),
size = 4) +
labs(
title = "標準化後 N(0, 1)",
subtitle = paste0("Z = (X - ", mu, ") / ", sigma),
x = "Z", y = "φ(z)"
) +
theme_minimal(base_size = 12)
p1 + p2 +
plot_annotation(
title = "換元積分的統計應用:標準化",
subtitle = "換元後可以用標準常態分布表查詢"
)
```
## 分部積分法 (Integration by Parts)
### 概念
分部積分法來自**乘法規則 (Product Rule)** 的反向操作。
**乘法規則(微分)**:
$$\frac{d}{dx}[u \cdot v] = u' \cdot v + u \cdot v'$$
**分部積分(積分)**:
$$\int u \cdot v' dx = u \cdot v - \int u' \cdot v dx$$
或寫成:
$$\int u \, dv = uv - \int v \, du$$
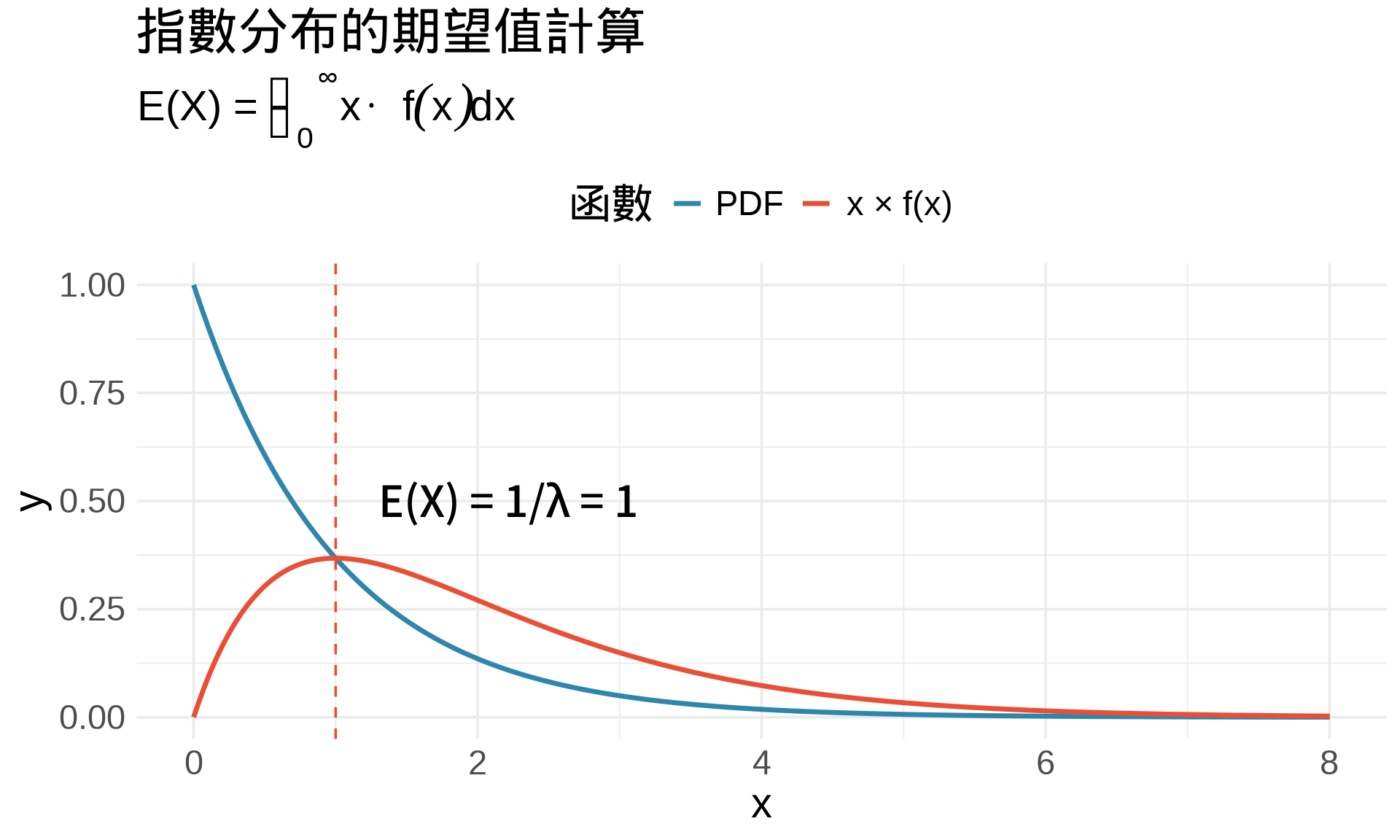
### 範例:計算期望值
**問題**:計算指數分布的期望值
$$E(X) = \int_0^{\infty} x \cdot \lambda e^{-\lambda x}dx$$
其中 $\lambda = 1$(簡化計算)。
**解答**:
令 $u = x$, $dv = e^{-x}dx$
則 $du = dx$, $v = -e^{-x}$
$$\int_0^{\infty} x e^{-x}dx = \left[-xe^{-x}\right]_0^{\infty} - \int_0^{\infty} (-e^{-x})dx$$
$$= 0 + \int_0^{\infty} e^{-x}dx = \left[-e^{-x}\right]_0^{\infty} = 1$$
所以 $E(X) = \frac{1}{\lambda}$(這是指數分布的期望值公式!)
**R 驗證**:
```{r}
# 數值積分計算期望值
lambda <- 1
f <- function(x) x * lambda * exp(-lambda * x)
# 理論上應該等於 1/lambda = 1
expectation <- integrate(f, lower = 0, upper = Inf)$value
cat("數值積分:", round(expectation, 5), "\n")
cat("理論值:", 1/lambda, "\n")
```
**視覺化**:
```{r}
#| label: fig-exponential-expectation
#| fig-cap: "指數分布的期望值"
#| warning: false
#| message: false
x <- seq(0, 8, by = 0.01)
lambda <- 1
f_x <- lambda * exp(-lambda * x)
xf_x <- x * f_x # x * f(x)
df <- data.frame(x, f_x, xf_x)
ggplot(df) +
# PDF
geom_line(aes(x, f_x, color = "PDF"), linewidth = 1.2) +
# x * f(x)
geom_line(aes(x, xf_x, color = "x × f(x)"), linewidth = 1.2) +
# 期望值位置
geom_vline(xintercept = 1/lambda, linetype = "dashed", color = "#E94F37") +
annotate("text", x = 1/lambda + 0.3, y = 0.5,
label = paste0("E(X) = 1/λ = ", 1/lambda),
hjust = 0, size = 5) +
scale_color_manual(
values = c("PDF" = "#2E86AB", "x × f(x)" = "#E94F37"),
name = "函數"
) +
labs(
title = "指數分布的期望值計算",
subtitle = expression("E(X) = " * integral(x %.% f(x)*dx, 0, infinity)),
x = "x", y = "y"
) +
theme_minimal(base_size = 14) +
theme(legend.position = "top")
```
**醫學應用**:指數分布常用於模擬「等待時間」,例如:
- 病患到院的時間間隔
- 醫療器材的故障時間
- 疾病復發的時間
## 統計應用:期望值與變異數
### 期望值的積分定義
對於連續型隨機變數 $X$ [@casella2002statistical; @degroot2012probability]:
$$E(X) = \int_{-\infty}^{\infty} x \cdot f(x)dx$$
**白話文**:把每個 $x$ 值乘以它的「機率密度」,然後全部加總。
### 變異數的積分定義
$$\text{Var}(X) = E(X^2) - [E(X)]^2$$
其中:
$$E(X^2) = \int_{-\infty}^{\infty} x^2 \cdot f(x)dx$$
### 範例:標準常態分布
**已知**:$X \sim N(0, 1)$,$f(x) = \frac{1}{\sqrt{2\pi}}e^{-x^2/2}$
**計算 $E(X)$**:
$$E(X) = \int_{-\infty}^{\infty} x \cdot \frac{1}{\sqrt{2\pi}}e^{-x^2/2}dx = 0$$
為什麼是 0?因為 $f(x)$ 對稱於 $x = 0$,正負抵消!
**計算 $E(X^2)$**:
$$E(X^2) = \int_{-\infty}^{\infty} x^2 \cdot \frac{1}{\sqrt{2\pi}}e^{-x^2/2}dx = 1$$
所以 $\text{Var}(X) = 1 - 0^2 = 1$
**R 驗證**:
```{r}
# 用模擬驗證
set.seed(42)
x <- rnorm(100000, mean = 0, sd = 1)
cat("模擬的平均值:", round(mean(x), 4), "\n")
cat("模擬的變異數:", round(var(x), 4), "\n")
# 理論值
cat("理論平均值:", 0, "\n")
cat("理論變異數:", 1, "\n")
```
## 練習題
### 觀念題
1. 為什麼 $\int x^{-1}dx = \ln|x| + C$ 而不是 $\frac{x^0}{0}$?
::: {.callout-tip collapse="true" title="參考答案"}
因為冪次積分公式 $\int x^n dx = \frac{x^{n+1}}{n+1} + C$ 只在 $n \neq -1$ 時有效。當 $n = -1$ 時,分母會變成 0,所以這個公式不適用。$\frac{1}{x}$ 是一個特殊情況,它的反導數是 $\ln|x|$(可以驗證:$\frac{d}{dx}\ln|x| = \frac{1}{x}$)。
:::
2. 說明「換元積分法」與「連鎖律」的關係。
::: {.callout-tip collapse="true" title="參考答案"}
換元積分法是連鎖律的反向操作。連鎖律告訴我們如何微分複合函數:$\frac{d}{dx}[f(g(x))] = f'(g(x)) \cdot g'(x)$。反過來,當我們看到積分 $\int f'(g(x)) \cdot g'(x)dx$ 時,就可以用換元法令 $u = g(x)$,使積分變簡單。這就像「解開」連鎖律的過程。
:::
3. 為什麼對稱分布的期望值等於對稱中心?
::: {.callout-tip collapse="true" title="參考答案"}
如果 PDF $f(x)$ 對稱於 $x = \mu$,則對於對稱中心兩側相同距離的點,它們的機率密度相同。在計算 $E(X) = \int x \cdot f(x)dx$ 時,對稱中心左側的負偏離值($x < \mu$)和右側的正偏離值($x > \mu$)會完全抵消,最後只剩下對稱中心 $\mu$。標準常態分布 $N(0,1)$ 就是最好的例子:對稱於 0,所以 $E(X) = 0$。
:::
### 計算題
4. 計算下列積分(用公式與 R 驗證):
a. $\int_0^1 (3x^2 + 2x)dx$
b. $\int_1^2 \frac{1}{x}dx$
c. $\int_0^1 e^{2x}dx$
```{r}
#| eval: false
# 提示
integrate(function(x) 3*x^2 + 2*x, lower = 0, upper = 1)
```
::: {.callout-tip collapse="true" title="參考答案"}
**a.** $\int_0^1 (3x^2 + 2x)dx = [x^3 + x^2]_0^1 = (1 + 1) - (0 + 0) = 2$
**b.** $\int_1^2 \frac{1}{x}dx = [\ln|x|]_1^2 = \ln 2 - \ln 1 = \ln 2 \approx 0.693$
**c.** $\int_0^1 e^{2x}dx = [\frac{1}{2}e^{2x}]_0^1 = \frac{1}{2}(e^2 - e^0) = \frac{e^2 - 1}{2} \approx 3.195$
用 R 驗證各題的積分值應該與手算結果一致。
:::
5. 驗證均勻分布 $U(0, 1)$ 的期望值是 $\frac{1}{2}$:
$$E(X) = \int_0^1 x \cdot 1 \, dx$$
::: {.callout-tip collapse="true" title="參考答案"}
$$E(X) = \int_0^1 x \cdot 1 \, dx = \left[\frac{x^2}{2}\right]_0^1 = \frac{1}{2} - 0 = \frac{1}{2}$$
這證明了均勻分布的期望值恰好在區間的中點。用 R 驗證:`integrate(function(x) x, lower = 0, upper = 1)` 應該得到 0.5。
:::
### R 操作題
6. 用 R 計算標準常態分布的**四階動差** $E(X^4)$(提示:應該等於 3)。
```{r}
#| eval: false
f <- function(x) x^4 * dnorm(x)
integrate(f, lower = -Inf, upper = Inf)
```
::: {.callout-tip collapse="true" title="參考答案"}
執行程式碼後應該得到接近 3 的結果。這是標準常態分布的重要性質:$E(X^4) = 3$。這個值在統計學中用來計算峰度 (kurtosis)。你也可以用模擬驗證:`mean(rnorm(100000)^4)` 應該也接近 3。
:::
7. 繪製 Beta 分布 $\text{Beta}(2, 5)$ 的 PDF,並計算其期望值:
$$E(X) = \int_0^1 x \cdot f(x)dx$$
驗證是否等於理論值 $\frac{\alpha}{\alpha + \beta} = \frac{2}{7}$。
```{r}
#| eval: false
dbeta(x, shape1 = 2, shape2 = 5) # PDF
```
::: {.callout-tip collapse="true" title="參考答案"}
先繪製 Beta(2,5) 的 PDF,然後用積分計算期望值。程式碼範例:
```r
# 計算期望值
f <- function(x) x * dbeta(x, shape1 = 2, shape2 = 5)
E_X <- integrate(f, lower = 0, upper = 1)$value
# 理論值
theoretical <- 2 / (2 + 5)
```
應該得到 $E(X) \approx 0.286 = \frac{2}{7}$,與理論公式完全吻合。Beta 分布常用於貝氏統計的先驗分布。
:::
## 本章重點整理 {.unnumbered}
1. **基本積分公式**:大多是微分公式的反向操作
2. **微積分基本定理**:$\int_a^b f(x)dx = F(b) - F(a)$
3. **換元積分法**:連鎖律的反向,用於複合函數
4. **統計應用**:
- 期望值:$E(X) = \int x \cdot f(x)dx$
- 變異數:$\text{Var}(X) = E(X^2) - [E(X)]^2$
- 標準化:換元法的應用
5. R 函數:`integrate(f, lower, upper)` 計算數值積分
---
**下一章預告**:我們將處理積分的「邊界問題」,當積分範圍延伸到無窮大時會發生什麼事?這對理解機率分布至關重要!