---
title: "Chapter 16: 存活分析 (Survival Analysis)"
---
```{r}
#| include: false
source(here::here("R/_common.R"))
```
## 學習目標 {.unnumbered}
- 理解 survival function 與 cumulative distribution function 的關係
- 掌握 hazard function 的微積分定義與直觀意義
- 了解 cumulative hazard 的積分概念
- 視覺化不同分布下的存活曲線與風險函數
- 連結存活分析與微積分的實際應用
## 概念說明 {#sec-survival}
### 存活分析的核心問題
在醫學研究中,我們經常關心「病人能活多久?」這個問題。存活分析 (survival analysis) 就是用來回答這類時間相關問題的統計方法[@collett2015modelling; @kleinbaum2012survival]。
舉個例子:
- **臨床試驗**:新藥能延長癌症病人的生存期嗎?
- **公共衛生**:吸菸者的壽命比不吸菸者短多少?
- **醫療器材**:心臟支架能用多久才會失效?
這些問題的共同特徵是:我們觀察**某個事件發生的時間**。這個事件可能是死亡、疾病復發、或器材故障。
### 為什麼需要特殊的數學工具?
存活分析之所以需要特殊的微積分工具,是因為它處理的是**連續時間**上的風險。我們不只想知道「有多少人會死」,更想知道「在什麼時間點,風險有多高」。
這就需要用到我們學過的微積分概念:
- **Survival function**:還活著的機率(積分的應用)
- **Hazard function**:瞬時死亡風險(導數的應用)
- **Cumulative hazard**:累積風險(積分與對數的結合)
## 視覺化理解
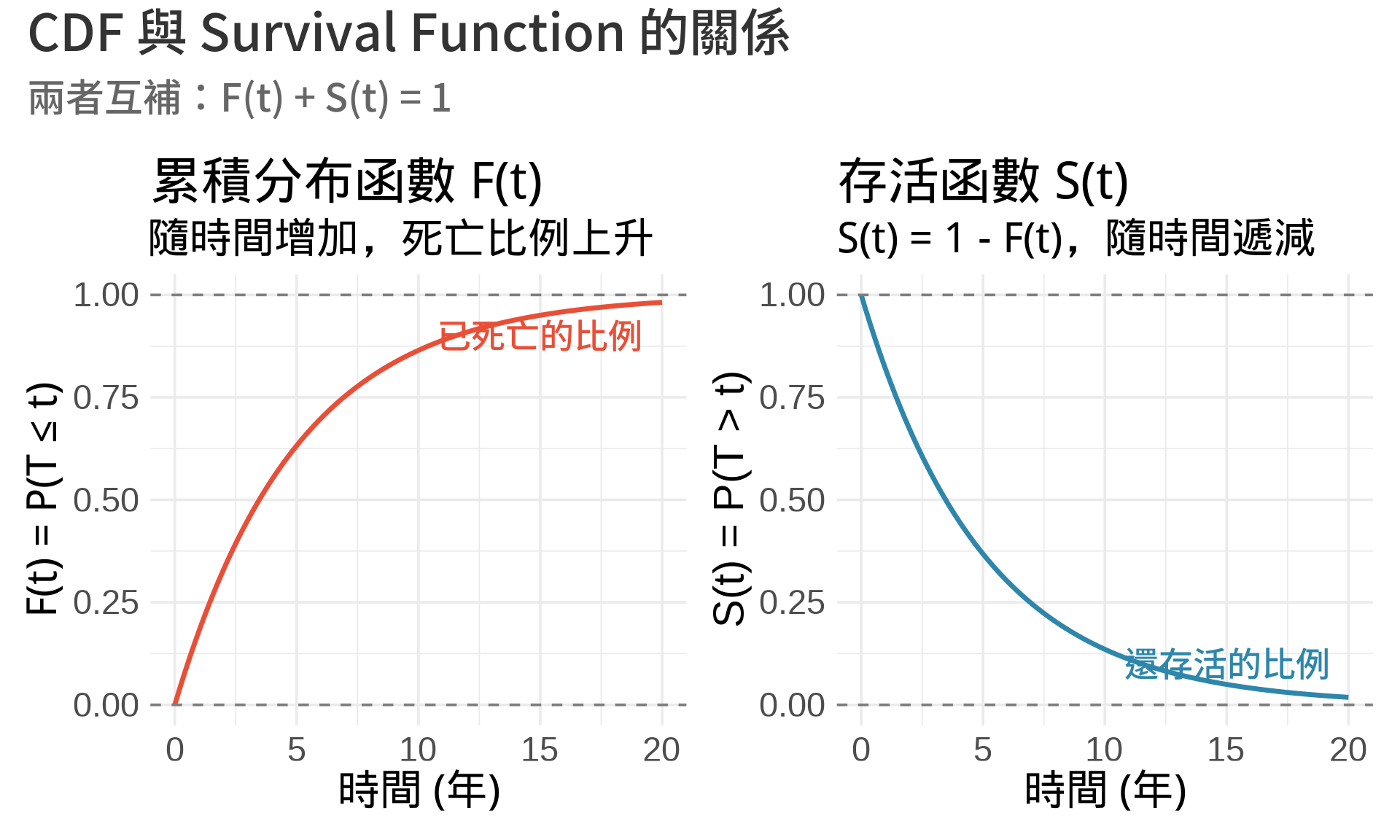
### 1. Survival Function: $S(t) = 1 - F(t)$
Survival function $S(t)$ 代表「存活到時間 $t$ 的機率」。
如果 $F(t)$ 是累積分布函數 (CDF),代表「在時間 $t$ 之前死亡的機率」,那麼:
$$S(t) = P(T > t) = 1 - F(t)$$
這個關係非常直觀:
- 如果 $F(t) = 0.3$(30% 的人在時間 $t$ 前死亡)
- 那麼 $S(t) = 0.7$(70% 的人還活著)
```{r}
#| label: fig-survival-basic
#| fig-cap: "Survival Function 的基本形狀"
#| warning: false
#| message: false
# 指數分布的例子 (lambda = 0.2)
t <- seq(0, 20, by = 0.1)
lambda <- 0.2
# CDF: F(t) = 1 - exp(-lambda * t)
F_t <- 1 - exp(-lambda * t)
# Survival function: S(t) = 1 - F(t) = exp(-lambda * t)
S_t <- exp(-lambda * t)
df <- data.frame(t, F_t, S_t)
p1 <- ggplot(df, aes(t, F_t)) +
geom_line(color = "#E94F37", linewidth = 1.2) +
geom_hline(yintercept = c(0, 1), linetype = "dashed", color = "gray50") +
annotate("text", x = 15, y = 0.9,
label = "已死亡的比例", size = 4, color = "#E94F37") +
labs(
title = "累積分布函數 F(t)",
subtitle = "隨時間增加,死亡比例上升",
x = "時間 (年)",
y = "F(t) = P(T ≤ t)"
) +
theme_minimal(base_size = 14)
p2 <- ggplot(df, aes(t, S_t)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
geom_hline(yintercept = c(0, 1), linetype = "dashed", color = "gray50") +
annotate("text", x = 15, y = 0.1,
label = "還存活的比例", size = 4, color = "#2E86AB") +
labs(
title = "存活函數 S(t)",
subtitle = "S(t) = 1 - F(t),隨時間遞減",
x = "時間 (年)",
y = "S(t) = P(T > t)"
) +
theme_minimal(base_size = 14)
p1 + p2 +
plot_annotation(
title = "CDF 與 Survival Function 的關係",
subtitle = "兩者互補:F(t) + S(t) = 1"
)
```
**重要觀察**:
1. $S(0) = 1$:時間為零時,所有人都還活著
2. $S(\infty) = 0$:時間無限大時,所有人終將死亡
3. $S(t)$ 是遞減函數:隨時間增加,存活機率下降
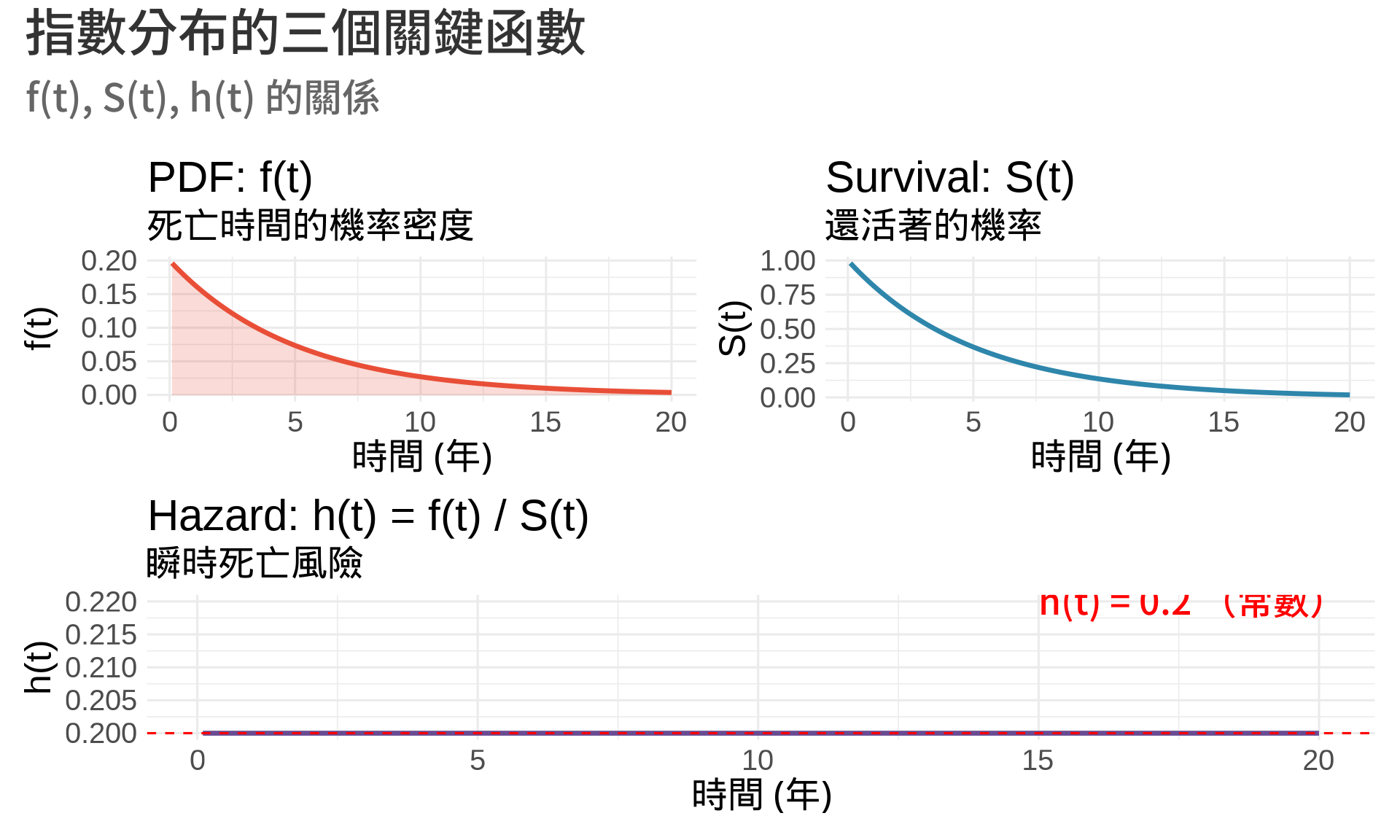
### 2. Hazard Function: $h(t) = \frac{f(t)}{S(t)}$
Hazard function(風險函數或危險率)是存活分析中最關鍵的概念。它代表**在時間 $t$ 的瞬時死亡風險**。
#### 直觀理解
想像你是一位 70 歲的醫師,你問:「我在明天死亡的機率是多少?」
- 如果用 PDF $f(70)$,它給的是「恰好在 70 歲死亡」的機率密度
- 但這不是你真正想問的!你想知道的是:**在已經活到 70 歲的條件下,接下來瞬間死亡的風險**
這就是 hazard function:
$$h(t) = \lim_{\Delta t \to 0} \frac{P(t < T \leq t + \Delta t \mid T > t)}{\Delta t}$$
#### 微積分推導
從條件機率出發:
$$P(t < T \leq t + \Delta t \mid T > t) = \frac{P(t < T \leq t + \Delta t)}{P(T > t)} = \frac{F(t + \Delta t) - F(t)}{S(t)}$$
除以 $\Delta t$ 並取極限:
$$h(t) = \lim_{\Delta t \to 0} \frac{F(t + \Delta t) - F(t)}{\Delta t \cdot S(t)} = \frac{F'(t)}{S(t)} = \frac{f(t)}{S(t)}$$
這就得到了 hazard function 的經典形式!
#### 另一種表達方式
因為 $S(t) = 1 - F(t)$,所以 $S'(t) = -F'(t) = -f(t)$,因此:
$$h(t) = \frac{f(t)}{S(t)} = -\frac{S'(t)}{S(t)} = -\frac{d}{dt} \ln S(t)$$
這個形式在數學推導中非常有用!
```{r}
#| label: fig-hazard-concept
#| fig-cap: "Hazard Function 的直觀意義"
#| warning: false
#| message: false
# 指數分布的例子
t <- seq(0.1, 20, by = 0.1) # 從 0.1 開始避免除以零
lambda <- 0.2
# PDF: f(t) = lambda * exp(-lambda * t)
f_t <- lambda * exp(-lambda * t)
# Survival: S(t) = exp(-lambda * t)
S_t <- exp(-lambda * t)
# Hazard: h(t) = f(t) / S(t) = lambda (常數!)
h_t <- f_t / S_t
df <- data.frame(t, f_t, S_t, h_t)
p1 <- ggplot(df, aes(t, f_t)) +
geom_line(color = "#E94F37", linewidth = 1.2) +
geom_area(fill = "#E94F37", alpha = 0.2) +
labs(
title = "PDF: f(t)",
subtitle = "死亡時間的機率密度",
x = "時間 (年)",
y = "f(t)"
) +
theme_minimal(base_size = 12)
p2 <- ggplot(df, aes(t, S_t)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
labs(
title = "Survival: S(t)",
subtitle = "還活著的機率",
x = "時間 (年)",
y = "S(t)"
) +
theme_minimal(base_size = 12)
p3 <- ggplot(df, aes(t, h_t)) +
geom_line(color = "#6A4C93", linewidth = 1.2) +
geom_hline(yintercept = lambda, linetype = "dashed", color = "red") +
annotate("text", x = 15, y = lambda + 0.02,
label = paste0("h(t) = ", lambda, " (常數)"),
hjust = 0, color = "red") +
labs(
title = "Hazard: h(t) = f(t) / S(t)",
subtitle = "瞬時死亡風險",
x = "時間 (年)",
y = "h(t)"
) +
theme_minimal(base_size = 12)
(p1 | p2) / p3 +
plot_annotation(
title = "指數分布的三個關鍵函數",
subtitle = "f(t), S(t), h(t) 的關係"
)
```
**重要發現**:
- 對於**指數分布**,hazard function 是**常數**!
- 這代表「無記憶性」:不管活了多久,未來的死亡風險都一樣
- 但現實中,大部分疾病的風險會隨時間變化
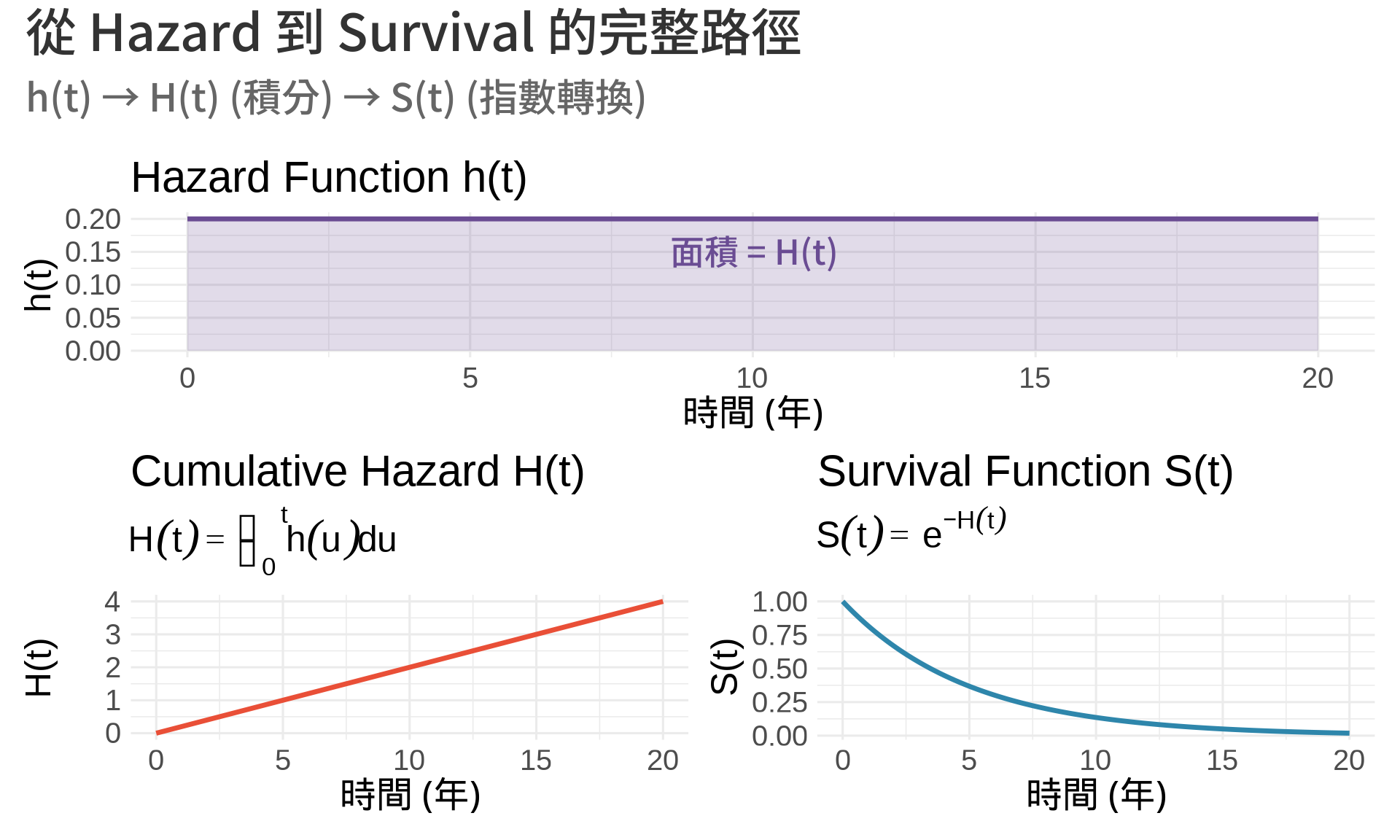
### 3. Cumulative Hazard: $H(t) = \int_0^t h(u) du$
Cumulative hazard(累積風險函數)是 hazard function 的積分:
$$H(t) = \int_0^t h(u) \, du$$
#### 與 Survival Function 的關係
從前面我們知道:
$$h(t) = -\frac{d}{dt} \ln S(t)$$
兩邊積分:
$$\int_0^t h(u) \, du = -\int_0^t \frac{d}{du} \ln S(u) \, du = -\left[ \ln S(u) \right]_0^t = -(\ln S(t) - \ln S(0))$$
因為 $S(0) = 1$,所以 $\ln S(0) = 0$:
$$H(t) = -\ln S(t)$$
反過來寫:
$$S(t) = e^{-H(t)}$$
這是存活分析中極為重要的關係式!
```{r}
#| label: fig-cumulative-hazard
#| fig-cap: "Cumulative Hazard 與 Survival Function 的關係"
#| warning: false
#| message: false
# 指數分布
t <- seq(0, 20, by = 0.1)
lambda <- 0.2
# Hazard (常數)
h_t <- rep(lambda, length(t))
# Cumulative Hazard: H(t) = lambda * t
H_t <- lambda * t
# Survival: S(t) = exp(-H(t))
S_t <- exp(-H_t)
df <- data.frame(t, h_t, H_t, S_t)
p1 <- ggplot(df, aes(t, h_t)) +
geom_line(color = "#6A4C93", linewidth = 1.2) +
geom_area(fill = "#6A4C93", alpha = 0.2) +
annotate("text", x = 10, y = 0.15,
label = "面積 = H(t)", size = 4, color = "#6A4C93") +
labs(
title = "Hazard Function h(t)",
x = "時間 (年)",
y = "h(t)"
) +
theme_minimal(base_size = 12)
p2 <- ggplot(df, aes(t, H_t)) +
geom_line(color = "#E94F37", linewidth = 1.2) +
labs(
title = "Cumulative Hazard H(t)",
subtitle = expression(H(t) == integral(h(u)*du, 0, t)),
x = "時間 (年)",
y = "H(t)"
) +
theme_minimal(base_size = 12)
p3 <- ggplot(df, aes(t, S_t)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
labs(
title = "Survival Function S(t)",
subtitle = expression(S(t) == e^{-H(t)}),
x = "時間 (年)",
y = "S(t)"
) +
theme_minimal(base_size = 12)
p1 / (p2 | p3) +
plot_annotation(
title = "從 Hazard 到 Survival 的完整路徑",
subtitle = "h(t) → H(t) (積分) → S(t) (指數轉換)"
)
```
## 數學定義
### Survival Function
**定義**:存活函數 $S(t)$ 是存活時間 $T$ 超過時間 $t$ 的機率:
$$S(t) = P(T > t) = 1 - F(t) = \int_t^{\infty} f(u) \, du$$
**性質**:
1. $S(0) = 1$(初始時所有人都活著)
2. $S(\infty) = 0$(最終所有人都會死亡)
3. $S(t)$ 是非遞增函數
4. $S(t) \in [0, 1]$ 且右連續
### Hazard Function
**定義**:風險函數 $h(t)$ 是在時間 $t$ 的瞬時失效率:
$$h(t) = \lim_{\Delta t \to 0} \frac{P(t < T \leq t + \Delta t \mid T > t)}{\Delta t} = \frac{f(t)}{S(t)} = -\frac{S'(t)}{S(t)}$$
**性質**:
1. $h(t) \geq 0$(風險不能是負的)
2. $h(t)$ 沒有上界(可以 > 1)
3. $h(t)$ 不是機率,而是**率** (rate)
4. $\int_0^{\infty} h(t) \, dt = \infty$(對於 proper distribution)
### Cumulative Hazard Function
**定義**:累積風險函數 $H(t)$ 是風險函數的積分:
$$H(t) = \int_0^t h(u) \, du = -\ln S(t)$$
**與 Survival 的關係**:
$$S(t) = \exp\left(-H(t)\right) = \exp\left(-\int_0^t h(u) \, du\right)$$
### 關係總結
這四個函數之間的微積分關係:
$$\begin{align}
f(t) &= F'(t) = -S'(t) \\
h(t) &= \frac{f(t)}{S(t)} = -\frac{d}{dt}\ln S(t) = H'(t) \\
H(t) &= \int_0^t h(u) \, du = -\ln S(t) \\
S(t) &= \exp(-H(t)) = \exp\left(-\int_0^t h(u) \, du\right)
\end{align}$$
## 實例比較:Exponential vs Weibull
### Exponential Distribution(指數分布)
**醫學情境**:假設死亡風險是**常數**(不隨年齡改變)
**數學形式**(參數 $\lambda > 0$):
$$\begin{align}
S(t) &= e^{-\lambda t} \\
f(t) &= \lambda e^{-\lambda t} \\
h(t) &= \lambda \quad \text{(常數!)} \\
H(t) &= \lambda t
\end{align}$$
**特性**:
- 無記憶性:$P(T > s + t \mid T > s) = P(T > t)$
- Hazard 是常數
- Mean survival time = $1/\lambda$
- Median survival time = $\ln(2)/\lambda$
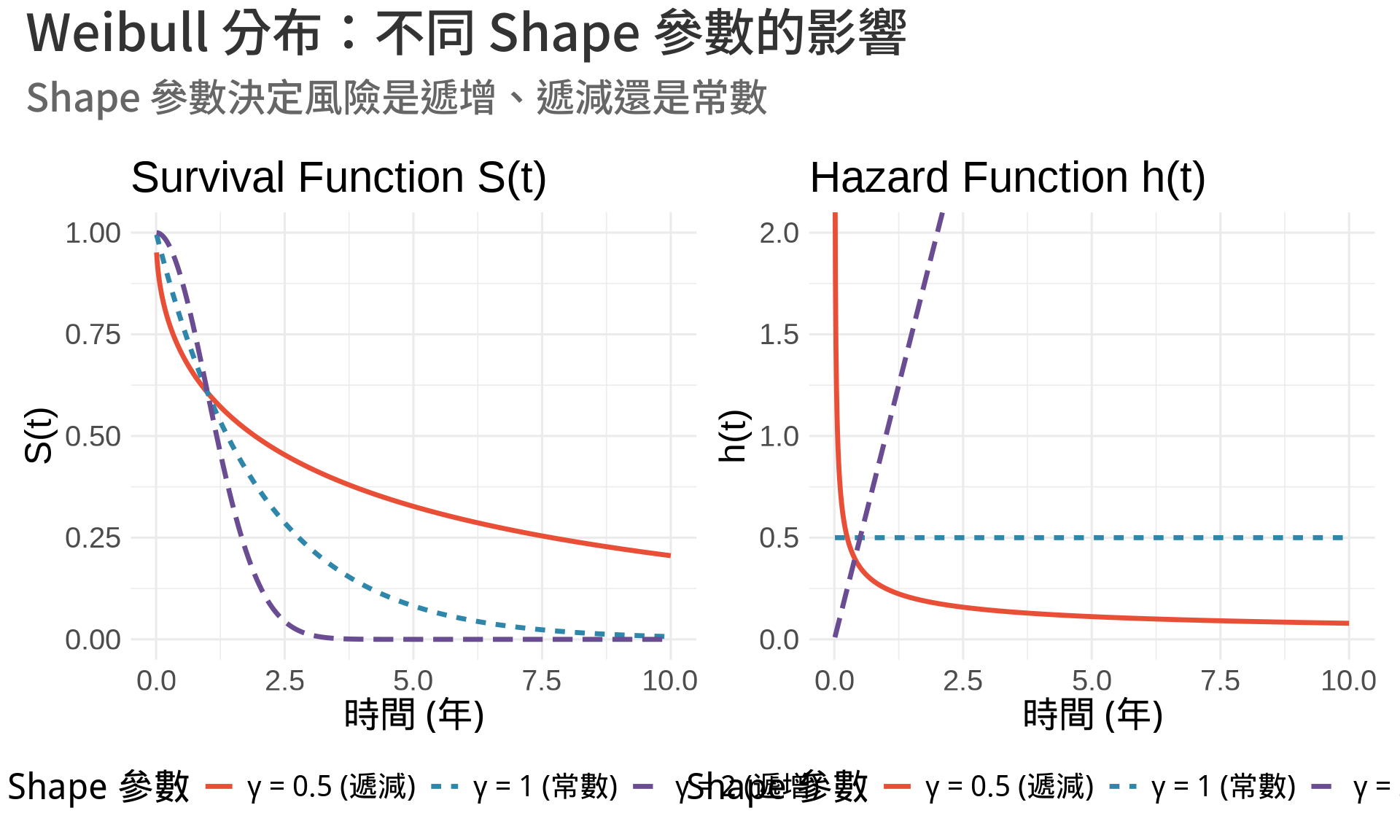
### Weibull Distribution(韋伯分布)
**醫學情境**:死亡風險會隨時間**增加或減少**(更符合實際)
**數學形式**(參數 $\lambda > 0$, shape $\gamma > 0$):
$$\begin{align}
S(t) &= e^{-\lambda t^{\gamma}} \\
f(t) &= \lambda \gamma t^{\gamma-1} e^{-\lambda t^{\gamma}} \\
h(t) &= \lambda \gamma t^{\gamma-1} \\
H(t) &= \lambda t^{\gamma}
\end{align}$$
**Hazard 的形狀取決於 $\gamma$**:
- $\gamma < 1$:遞減風險(嬰兒死亡率)
- $\gamma = 1$:常數風險(指數分布的特例)
- $\gamma > 1$:遞增風險(老化、器官衰竭)
```{r}
#| label: fig-weibull-shapes
#| fig-cap: "不同 Shape 參數的 Weibull 分布"
#| warning: false
#| message: false
library(dplyr)
t <- seq(0.01, 10, by = 0.01)
lambda <- 0.5
# 三種不同的 shape 參數
shapes <- c(0.5, 1, 2)
shape_labels <- c("γ = 0.5 (遞減)", "γ = 1 (常數)", "γ = 2 (遞增)")
# 計算三種情況
df_list <- lapply(1:length(shapes), function(i) {
gamma <- shapes[i]
data.frame(
t = t,
S_t = exp(-lambda * t^gamma),
h_t = lambda * gamma * t^(gamma - 1),
shape = shape_labels[i]
)
})
df <- bind_rows(df_list)
df$shape <- factor(df$shape, levels = shape_labels)
# Survival curves
p1 <- ggplot(df, aes(t, S_t, color = shape, linetype = shape)) +
geom_line(linewidth = 1.2) +
scale_color_manual(values = c("#E94F37", "#2E86AB", "#6A4C93")) +
labs(
title = "Survival Function S(t)",
x = "時間 (年)",
y = "S(t)",
color = "Shape 參數",
linetype = "Shape 參數"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "bottom")
# Hazard functions
p2 <- ggplot(df, aes(t, h_t, color = shape, linetype = shape)) +
geom_line(linewidth = 1.2) +
scale_color_manual(values = c("#E94F37", "#2E86AB", "#6A4C93")) +
coord_cartesian(ylim = c(0, 2)) +
labs(
title = "Hazard Function h(t)",
x = "時間 (年)",
y = "h(t)",
color = "Shape 參數",
linetype = "Shape 參數"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "bottom")
p1 + p2 +
plot_annotation(
title = "Weibull 分布:不同 Shape 參數的影響",
subtitle = "Shape 參數決定風險是遞增、遞減還是常數"
)
```
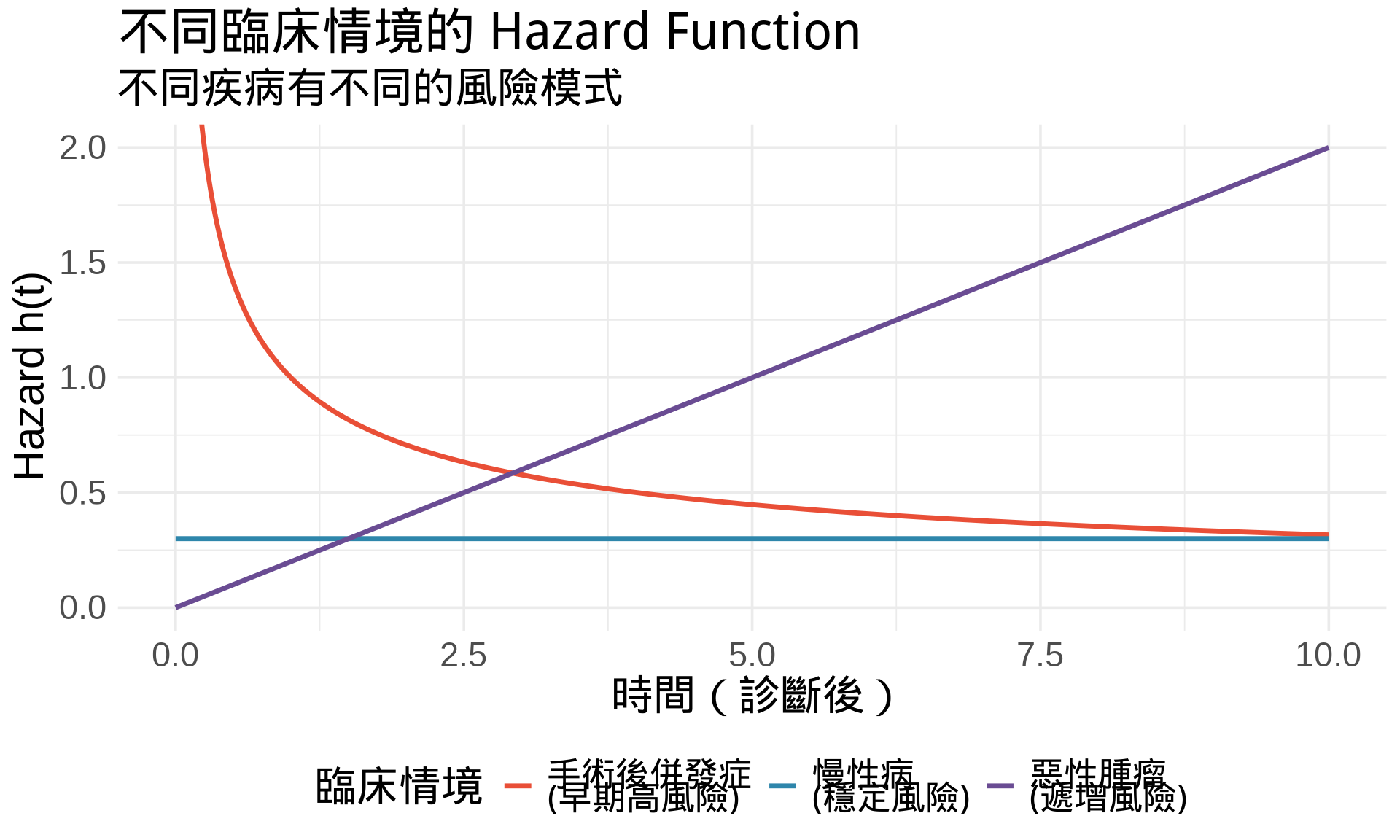
### 臨床意義
```{r}
#| label: fig-clinical-examples
#| fig-cap: "不同臨床情境的 Hazard 形狀"
#| warning: false
#| message: false
# 模擬三種臨床情境
t <- seq(0, 10, by = 0.01)
# 1. 手術後早期高風險,之後下降 (γ < 1)
h1 <- 2 * 0.5 * t^(-0.5)
# 2. 慢性病,風險穩定 (γ = 1)
h2 <- rep(0.3, length(t))
# 3. 癌症,風險隨時間上升 (γ > 1)
h3 <- 0.1 * 2 * t
df <- data.frame(
t = rep(t, 3),
h_t = c(h1, h2, h3),
scenario = rep(
c("手術後併發症\n(早期高風險)",
"慢性病\n(穩定風險)",
"惡性腫瘤\n(遞增風險)"),
each = length(t)
)
)
df$scenario <- factor(df$scenario,
levels = c("手術後併發症\n(早期高風險)",
"慢性病\n(穩定風險)",
"惡性腫瘤\n(遞增風險)"))
ggplot(df, aes(t, h_t, color = scenario)) +
geom_line(linewidth = 1.2) +
scale_color_manual(values = c("#E94F37", "#2E86AB", "#6A4C93")) +
coord_cartesian(ylim = c(0, 2)) +
labs(
title = "不同臨床情境的 Hazard Function",
subtitle = "不同疾病有不同的風險模式",
x = "時間(診斷後)",
y = "Hazard h(t)",
color = "臨床情境"
) +
theme_minimal(base_size = 14) +
theme(legend.position = "bottom")
```
## 練習題
### 觀念題
1. **解釋差異**:Survival function $S(t)$ 與 cumulative distribution function $F(t)$ 有什麼關係?為什麼存活分析用 $S(t)$ 而不是 $F(t)$?
::: {.callout-tip collapse="true" title="參考答案"}
$S(t) = 1 - F(t)$ 是互補關係。存活分析關注「還活著的機率」而非「已死亡的機率」,因此用 $S(t)$ 更直觀。此外,$S(t)$ 從 1 開始遞減至 0,更符合臨床思維:我們追蹤病人從健康到死亡的過程。
:::
2. **直觀理解**:為什麼 hazard function $h(t)$ 可以大於 1,但機率不行?用瞬時變化率的概念解釋。
::: {.callout-tip collapse="true" title="參考答案"}
$h(t)$ 是「率」(rate) 而非機率。它代表單位時間內的瞬時風險,類似速度的概念。例如 $h(t) = 2$ 表示每單位時間有 200% 的風險率,這在數學上合理。相對地,機率必須介於 0 到 1 之間,因為它代表事件發生的可能性比例。
:::
3. **無記憶性**:指數分布有「無記憶性」。這在醫學上合理嗎?舉一個合適和一個不合適的例子。
::: {.callout-tip collapse="true" title="參考答案"}
**合適**:某些突發事件(如車禍死亡)可能符合無記憶性,因為風險不隨年齡顯著改變。**不合適**:癌症或心臟病不符合,因為隨著年齡增長或病程進展,死亡風險會上升(需要 Weibull 分布,$\gamma > 1$)。
:::
4. **Shape 參數的意義**:
- 如果 Weibull 分布的 shape 參數 $\gamma = 0.8$,這代表什麼?
- 如果 $\gamma = 1.5$,這適合描述什麼疾病?
::: {.callout-tip collapse="true" title="參考答案"}
$\gamma = 0.8 < 1$ 代表風險遞減,適合描述手術後早期併發症(早期高風險,之後下降)。$\gamma = 1.5 > 1$ 代表風險遞增,適合描述慢性退化性疾病(如癌症、器官衰竭),隨時間病情惡化,死亡風險上升。
:::
5. **微積分關係**:為什麼 $h(t) = -\frac{d}{dt}\ln S(t)$?用連鎖律 (chain rule) 證明這個等式。
::: {.callout-tip collapse="true" title="參考答案"}
由 $h(t) = \frac{f(t)}{S(t)}$ 開始。因為 $f(t) = -S'(t)$($S(t) = 1 - F(t)$ 的導數),所以 $h(t) = \frac{-S'(t)}{S(t)}$。根據連鎖律,$\frac{d}{dt}\ln S(t) = \frac{1}{S(t)} \cdot S'(t) = \frac{S'(t)}{S(t)}$,因此 $h(t) = -\frac{d}{dt}\ln S(t)$。
:::
### 計算題
6. **指數分布的參數**:假設某疾病的平均存活時間是 5 年,且符合指數分布。
- (a) 求參數 $\lambda$
- (b) 求 3 年存活率 $S(3)$
- (c) 求 hazard $h(t)$
- (d) 用 R 驗證答案
::: {.callout-tip collapse="true" title="參考答案"}
(a) 指數分布的平均值 = $1/\lambda$,所以 $\lambda = 1/5 = 0.2$。(b) $S(3) = e^{-\lambda \cdot 3} = e^{-0.6} \approx 0.549$(約 55% 存活率)。(c) 指數分布的 hazard 是常數:$h(t) = \lambda = 0.2$。(d) R 驗證:`lambda <- 0.2; S_3 <- exp(-lambda * 3); S_3` 得到 0.5488。
:::
7. **Cumulative hazard 計算**:給定 $h(t) = 0.1t$(線性遞增),求:
- (a) $H(5)$
- (b) $S(5)$
- (c) 中位存活時間($S(t) = 0.5$ 的時間)
::: {.callout-tip collapse="true" title="參考答案"}
(a) $H(5) = \int_0^5 0.1t \, dt = 0.1 \cdot \frac{t^2}{2}\Big|_0^5 = 0.05 \times 25 = 1.25$。(b) $S(5) = e^{-H(5)} = e^{-1.25} \approx 0.287$。(c) 令 $S(t) = e^{-0.05t^2} = 0.5$,取對數:$-0.05t^2 = \ln(0.5) = -0.693$,所以 $t^2 = 13.86$,$t \approx 3.72$ 年。
:::
8. **從 Survival 推 Hazard**:如果 $S(t) = \frac{1}{1 + t}$(不是標準分布),求:
- (a) $f(t)$
- (b) $h(t)$
- (c) $H(t)$
::: {.callout-tip collapse="true" title="參考答案"}
(a) $f(t) = -S'(t) = -\frac{d}{dt}(1+t)^{-1} = (1+t)^{-2} = \frac{1}{(1+t)^2}$。(b) $h(t) = \frac{f(t)}{S(t)} = \frac{1/(1+t)^2}{1/(1+t)} = \frac{1}{1+t}$。(c) $H(t) = -\ln S(t) = -\ln\frac{1}{1+t} = \ln(1+t)$。驗證:$H'(t) = \frac{1}{1+t} = h(t)$ ✓
:::
### R 操作題
9. **模擬指數分布存活資料**:
```r
# 修改下列程式碼,探索不同 lambda 的影響
set.seed(123)
n <- 1000
lambda <- 0.2
survival_times <- rexp(n, rate = lambda)
# TODO: 繪製經驗存活曲線與理論曲線的比較
# TODO: 計算平均存活時間並與 1/lambda 比較
```
::: {.callout-tip collapse="true" title="參考答案"}
```r
# 計算經驗存活曲線
library(survival)
km_fit <- survfit(Surv(survival_times) ~ 1)
plot(km_fit, xlab = "時間", ylab = "S(t)", main = "經驗 vs 理論")
# 加上理論曲線
curve(exp(-lambda * x), add = TRUE, col = "red", lwd = 2)
# 平均存活時間
mean(survival_times) # 應接近 1/lambda = 5
```
:::
10. **比較兩個 Weibull 分布**:
```r
# 修改程式碼,比較兩種治療的存活曲線
t <- seq(0, 10, by = 0.01)
# 治療 A: shape = 1.2, scale = 5
# 治療 B: shape = 0.8, scale = 6
# TODO: 繪製兩者的 S(t), f(t), h(t) 並比較
# TODO: 哪一個治療在早期較好?晚期呢?
```
::: {.callout-tip collapse="true" title="參考答案"}
```r
# 治療 A 的曲線
S_A <- pweibull(t, shape = 1.2, scale = 5, lower.tail = FALSE)
h_A <- dweibull(t, 1.2, 5) / S_A
# 治療 B 的曲線
S_B <- pweibull(t, shape = 0.8, scale = 6, lower.tail = FALSE)
h_B <- dweibull(t, 0.8, 6) / S_B
# 比較:早期(t < 3)B 較好(S_B > S_A),晚期(t > 6)A 較好
```
:::
## 統計應用
### 1. Kaplan-Meier 估計量
在實際研究中,我們通常無法觀察到所有人的完整存活時間(有些人還活著,或失聯)。這稱為**設限資料** (censored data)。
Kaplan-Meier 估計量[@kaplan1958nonparametric]用來估計 survival function:
$$\hat{S}(t) = \prod_{t_i \leq t} \left(1 - \frac{d_i}{n_i}\right)$$
其中:
- $t_i$:觀察到的死亡時間
- $d_i$:在 $t_i$ 時刻死亡的人數
- $n_i$:在 $t_i$ 時刻仍在風險中的人數
這個估計量是**階梯函數**(不連續),但當樣本夠大時會趨近真實的 $S(t)$。
### 2. Cox Proportional Hazards Model
Cox proportional hazards model [@cox1972regression]是存活分析中最常用的模型:
$$h(t \mid X) = h_0(t) \exp(\beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p)$$
**重要特性**:
- $h_0(t)$ 是 baseline hazard(不需指定形式)
- $\exp(\beta)$ 是 hazard ratio
- 如果 $\beta_1 = 0.5$,則 $\exp(0.5) \approx 1.65$:該變數每增加一單位,hazard 增加 65%
### 3. Hazard Ratio 的解讀
如果比較兩個治療組:
$$\text{HR} = \frac{h_{\text{treatment}}(t)}{h_{\text{control}}(t)} = \exp(\beta)$$
- HR = 1:兩組風險相同
- HR < 1:治療組風險較低(有效)
- HR > 1:治療組風險較高(有害)
**微積分的應用**:
$$\ln(\text{HR}) = \beta$$
所以我們在 Cox 迴歸中估計的是 **log hazard ratio**,然後取指數還原。
### 4. 預測未來存活機率
給定 Cox 模型的估計結果,我們可以預測個別病人的存活機率:
$$\hat{S}(t \mid X) = \left[\hat{S}_0(t)\right]^{\exp(X\beta)}$$
這需要:
1. Baseline survival $\hat{S}_0(t)$(從資料估計)
2. 迴歸係數 $\hat{\beta}$(從 Cox 模型估計)
3. 病人的共變數 $X$
## 本章重點整理 {.unnumbered}
1. **四個關鍵函數的微積分關係**:
- Survival: $S(t) = 1 - F(t) = \exp(-H(t))$
- PDF: $f(t) = F'(t) = -S'(t)$
- Hazard: $h(t) = f(t)/S(t) = -S'(t)/S(t) = -\frac{d}{dt}\ln S(t)$
- Cumulative Hazard: $H(t) = \int_0^t h(u)du = -\ln S(t)$
2. **Hazard function 的意義**:
- 表示瞬時失效率(導數的概念)
- 是條件機率的極限(已活到 $t$ 的條件下)
- 可以 > 1(因為是率,不是機率)
3. **指數分布 vs Weibull 分布**:
- 指數:hazard 是常數(無記憶性)
- Weibull:hazard 可遞增、遞減或常數(shape 參數 $\gamma$ 決定)
4. **臨床應用**:
- Kaplan-Meier 估計 survival curve
- Cox 迴歸估計 hazard ratio
- Log transformation 讓乘法關係變成加法
5. **微積分工具的必要性**:
- 連續時間需要用導數描述瞬時變化
- 累積風險需要用積分計算
- 對數函數讓複雜關係變簡單