---
title: "Chapter 11: 偏微分 (Partial Derivatives)"
---
```{r}
#| include: false
source(here::here("R/_common.R"))
```
## 學習目標 {.unnumbered}
- 理解多變量函數的幾何意義(3D 曲面)
- 掌握偏微分的概念:「固定其他變數,對一個變數微分」
- 視覺化理解偏微分的幾何意義
- 連結到多元迴歸係數的推導
- 理解多參數 MLE 的最佳化過程
## 從單變量到多變量
### 回顧:單變量函數
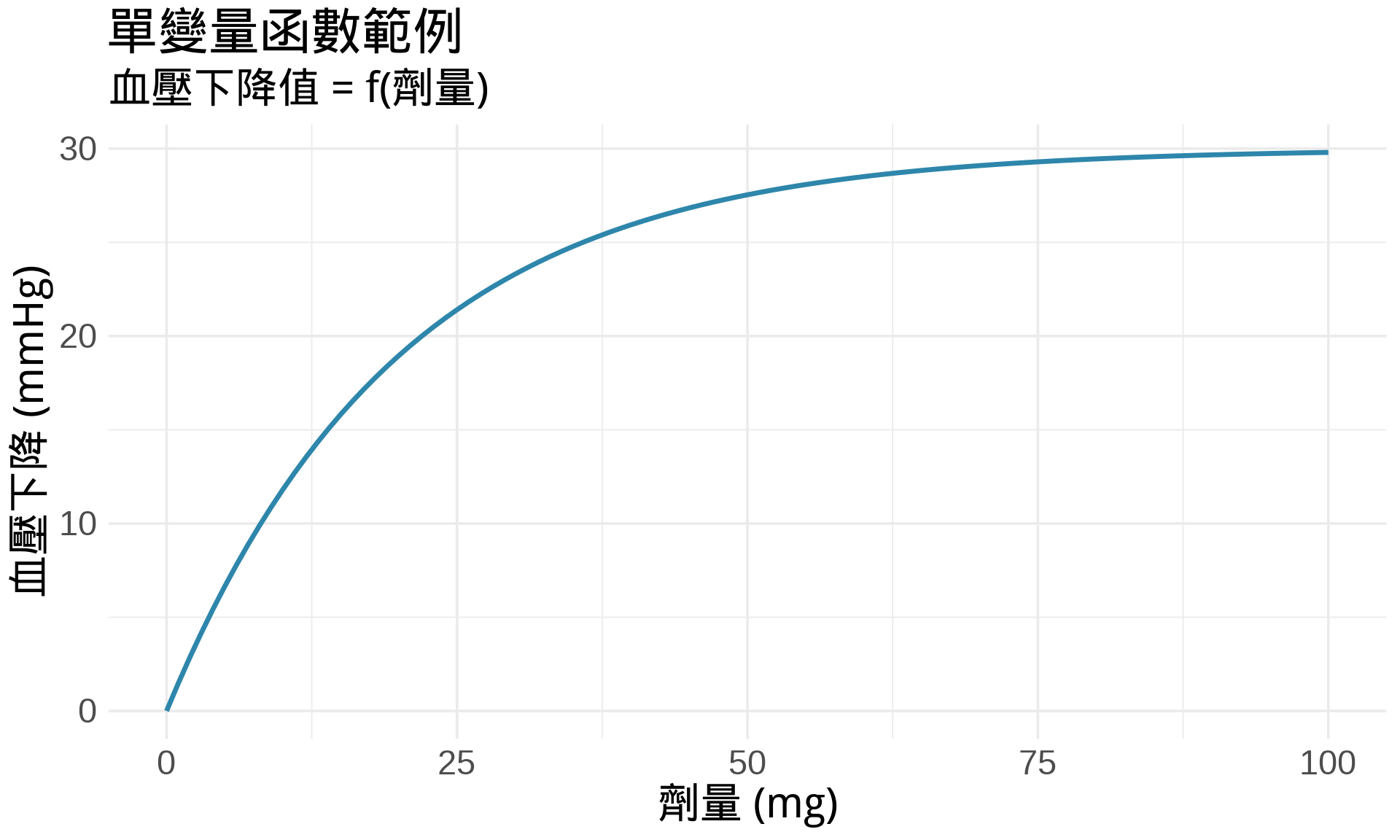
在之前的章節,我們處理的都是 $y = f(x)$ 這種形式 [@stewart2015calculus]:
- **Input**:一個變數 $x$(例如:劑量)
- **Output**:一個變數 $y$(例如:血壓下降值)
```{r}
#| label: fig-single-variable
#| fig-cap: "單變量函數:血壓下降 vs 劑量"
# 劑量反應曲線
dose <- seq(0, 100, by = 1)
response <- 30 * (1 - exp(-dose / 20))
ggplot(data.frame(dose, response), aes(dose, response)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
labs(
title = "單變量函數範例",
subtitle = "血壓下降值 = f(劑量)",
x = "劑量 (mg)",
y = "血壓下降 (mmHg)"
) +
theme_minimal(base_size = 14)
```
### 多變量函數的必要性
但臨床現實更複雜。同樣的劑量,給不同年齡的患者,效果可能不同:
$$\text{血壓下降} = f(\text{劑量}, \text{年齡})$$
這就是**多變量函數** (multivariate function) [@thomas2018calculus]:
- **Input**:多個變數 $x, y, z, \ldots$
- **Output**:一個變數 $z = f(x, y)$
## 多變量函數的視覺化
### 3D 曲面圖
對於兩個變數的函數 $z = f(x, y)$,我們可以用 **3D 曲面** (surface) 表示。
```{r}
#| label: fig-3d-surface
#| fig-cap: "3D 曲面:血壓下降 = f(劑量, 年齡)"
library(plotly)
# 建立資料
dose <- seq(0, 100, length.out = 50)
age <- seq(30, 80, length.out = 50)
# 血壓下降模型(劑量效果 - 年齡修正)
response <- outer(dose, age, function(d, a) {
30 * (1 - exp(-d / 20)) * (1 - (a - 30) / 200)
})
plot_ly(
x = dose,
y = age,
z = response,
type = "surface",
colorscale = list(c(0, "#2E86AB"), c(1, "#E94F37"))
) %>%
layout(
title = "血壓下降 = f(劑量, 年齡)",
scene = list(
xaxis = list(title = "劑量 (mg)"),
yaxis = list(title = "年齡 (歲)"),
zaxis = list(title = "血壓下降 (mmHg)")
)
)
```
**觀察重點**:
- **曲面的高度** = 血壓下降值
- **固定年齡**,沿著「劑量」方向移動 → 看劑量效果
- **固定劑量**,沿著「年齡」方向移動 → 看年齡效果
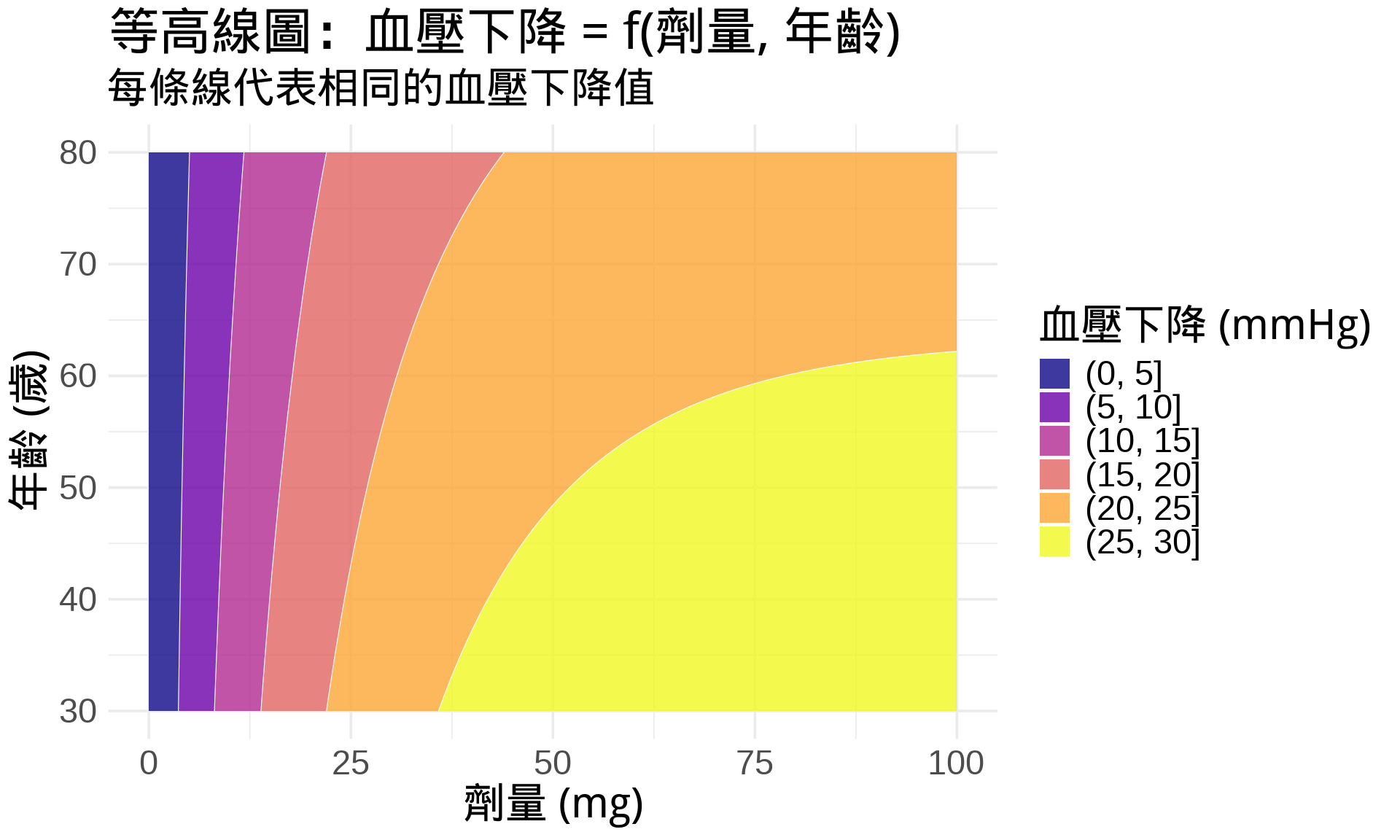
### 等高線圖 (Contour Plot)
3D 圖不好印刷?用**等高線圖**!就像地圖上的海拔線。
```{r}
#| label: fig-contour
#| fig-cap: "等高線圖:相同血壓下降值的曲線"
# 建立網格資料
grid <- expand.grid(
dose = seq(0, 100, length.out = 100),
age = seq(30, 80, length.out = 100)
)
grid$response <- 30 * (1 - exp(-grid$dose / 20)) *
(1 - (grid$age - 30) / 200)
ggplot(grid, aes(dose, age, z = response)) +
geom_contour_filled(alpha = 0.8) +
geom_contour(color = "white", linewidth = 0.2) +
scale_fill_viridis_d(option = "plasma", name = "血壓下降 (mmHg)") +
labs(
title = "等高線圖:血壓下降 = f(劑量, 年齡)",
subtitle = "每條線代表相同的血壓下降值",
x = "劑量 (mg)",
y = "年齡 (歲)"
) +
theme_minimal(base_size = 14) +
theme(legend.position = "right")
```
## 偏微分的概念
### 問題:曲面的斜率是多少?
在單變量函數中,我們問:「這條曲線在某點的斜率是多少?」答案是**導數** $f'(x)$。
在多變量函數中,問題變複雜了:
> 「這個曲面在某點的斜率是多少?」
**答案**:要看你往**哪個方向**走!
### 偏微分的定義
**偏微分** (partial derivative) 就是:
> 固定其他變數,只對一個變數微分
**符號**:
- 對 $x$ 的偏微分:$\frac{\partial f}{\partial x}$ 或 $f_x$
- 對 $y$ 的偏微分:$\frac{\partial f}{\partial y}$ 或 $f_y$
**讀音**:「偏 f 偏 x」(partial f partial x)
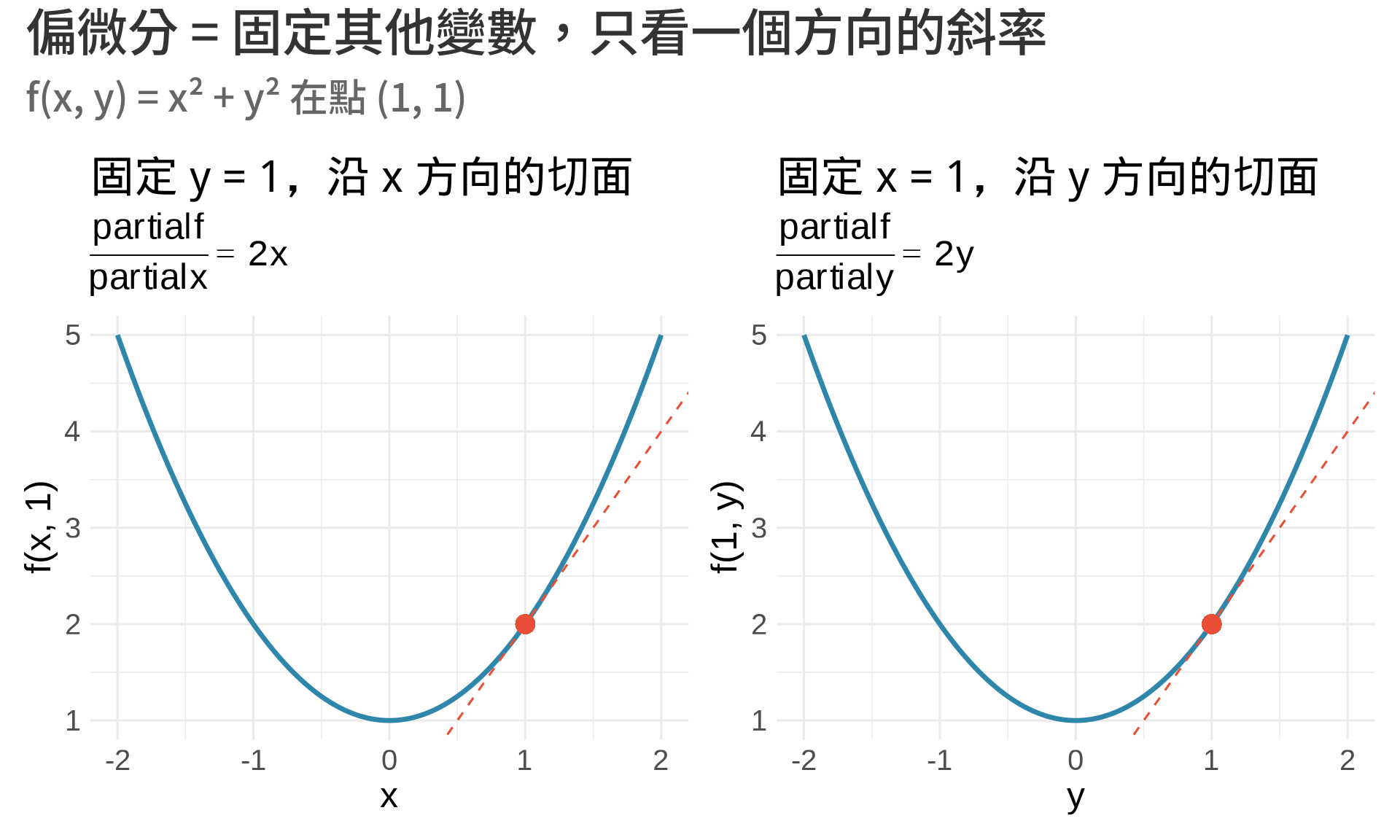
### 幾何意義
```{r}
#| label: fig-partial-derivative-geometry
#| fig-cap: "偏微分的幾何意義:固定一個方向的切線斜率"
# 函數 f(x, y) = x² + y²
f <- function(x, y) x^2 + y^2
# 固定 y = 1,看 x 方向的切面
x_seq <- seq(-2, 2, by = 0.01)
y_fixed <- 1
z_x <- f(x_seq, y_fixed)
p1 <- ggplot(data.frame(x = x_seq, z = z_x), aes(x, z)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
geom_point(aes(x = 1, y = f(1, y_fixed)), color = "#E94F37", size = 4) +
geom_abline(intercept = f(1, y_fixed) - 2*1, slope = 2,
color = "#E94F37", linetype = "dashed") +
labs(
title = "固定 y = 1,沿 x 方向的切面",
subtitle = expression(frac(partial*f, partial*x) == 2*x),
x = "x", y = "f(x, 1)"
) +
theme_minimal(base_size = 12)
# 固定 x = 1,看 y 方向的切面
y_seq <- seq(-2, 2, by = 0.01)
x_fixed <- 1
z_y <- f(x_fixed, y_seq)
p2 <- ggplot(data.frame(y = y_seq, z = z_y), aes(y, z)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
geom_point(aes(x = y_fixed, y = f(x_fixed, 1)), color = "#E94F37", size = 4) +
geom_abline(intercept = f(x_fixed, y_fixed) - 2*1, slope = 2,
color = "#E94F37", linetype = "dashed") +
labs(
title = "固定 x = 1,沿 y 方向的切面",
subtitle = expression(frac(partial*f, partial*y) == 2*y),
x = "y", y = "f(1, y)"
) +
theme_minimal(base_size = 12)
p1 + p2 +
plot_annotation(
title = "偏微分 = 固定其他變數,只看一個方向的斜率",
subtitle = "f(x, y) = x² + y² 在點 (1, 1)"
)
```
**重點理解**:
- $\frac{\partial f}{\partial x}$:把 $y$ 當作**常數**,對 $x$ 微分
- $\frac{\partial f}{\partial y}$:把 $x$ 當作**常數**,對 $y$ 微分
## 偏微分的計算
### 基本原則
> 對哪個變數偏微分,就把其他變數當作常數
### 範例 1:簡單多項式
$$f(x, y) = x^2 + 3xy + y^2$$
**對 $x$ 偏微分**(把 $y$ 當常數):
$$\frac{\partial f}{\partial x} = 2x + 3y$$
**對 $y$ 偏微分**(把 $x$ 當常數):
$$\frac{\partial f}{\partial y} = 3x + 2y$$
```{r}
#| label: fig-polynomial-partial
#| fig-cap: "多項式函數的偏微分視覺化"
# f(x, y) = x² + 3xy + y²
f <- function(x, y) x^2 + 3*x*y + y^2
# 偏微分
fx <- function(x, y) 2*x + 3*y
fy <- function(x, y) 3*x + 2*y
# 在點 (1, 2) 計算
x0 <- 1
y0 <- 2
cat("在點 (1, 2):\n")
cat("f(1, 2) =", f(x0, y0), "\n")
cat("∂f/∂x =", fx(x0, y0), "(x 方向的斜率)\n")
cat("∂f/∂y =", fy(x0, y0), "(y 方向的斜率)\n")
# 3D 視覺化
x <- seq(-2, 2, length.out = 50)
y <- seq(-2, 2, length.out = 50)
z <- outer(x, y, f)
plot_ly(x = x, y = y, z = z, type = "surface",
colorscale = list(c(0, "#2E86AB"), c(1, "#E94F37"))) %>%
add_trace(
x = c(x0), y = c(y0), z = c(f(x0, y0)),
type = "scatter3d", mode = "markers",
marker = list(size = 8, color = "red")
) %>%
layout(
title = "f(x, y) = x² + 3xy + y²",
scene = list(
xaxis = list(title = "x"),
yaxis = list(title = "y"),
zaxis = list(title = "f(x,y)")
)
)
```
### 範例 2:指數函數(統計常見)
$$f(x, y) = e^{-(x^2 + y^2)}$$
這是**雙變量常態分布**的核心形式(標準化版本)。
**對 $x$ 偏微分**(用 chain rule):
$$\frac{\partial f}{\partial x} = e^{-(x^2 + y^2)} \cdot (-2x) = -2x \cdot f(x, y)$$
**對 $y$ 偏微分**:
$$\frac{\partial f}{\partial y} = -2y \cdot f(x, y)$$
```{r}
#| label: fig-bivariate-normal
#| fig-cap: "雙變量常態分布的核心函數"
# 雙變量常態(標準化)
f <- function(x, y) exp(-(x^2 + y^2))
x <- seq(-3, 3, length.out = 100)
y <- seq(-3, 3, length.out = 100)
z <- outer(x, y, f)
plot_ly(x = x, y = y, z = z, type = "surface",
colorscale = list(c(0, "white"), c(0.5, "#2E86AB"), c(1, "#E94F37"))) %>%
layout(
title = "f(x, y) = exp(-(x² + y²))",
subtitle = "雙變量常態分布(標準化)",
scene = list(
xaxis = list(title = "x"),
yaxis = list(title = "y"),
zaxis = list(title = "f(x,y)")
)
)
```
### 範例 3:對數函數(MLE 常見)
$$f(\mu, \sigma) = \log L(\mu, \sigma \mid \text{data})$$
這是**對數概似函數** (log-likelihood function)。
假設觀察到資料 $x_1, \ldots, x_n$,常態分布的 log-likelihood:
$$\log L(\mu, \sigma) = -\frac{n}{2}\log(2\pi) - n\log\sigma - \frac{1}{2\sigma^2}\sum_{i=1}^n (x_i - \mu)^2$$
**對 $\mu$ 偏微分**:
$$\frac{\partial \log L}{\partial \mu} = \frac{1}{\sigma^2}\sum_{i=1}^n (x_i - \mu)$$
**對 $\sigma$ 偏微分**:
$$\frac{\partial \log L}{\partial \sigma} = -\frac{n}{\sigma} + \frac{1}{\sigma^3}\sum_{i=1}^n (x_i - \mu)^2$$
```{r}
#| label: fig-log-likelihood
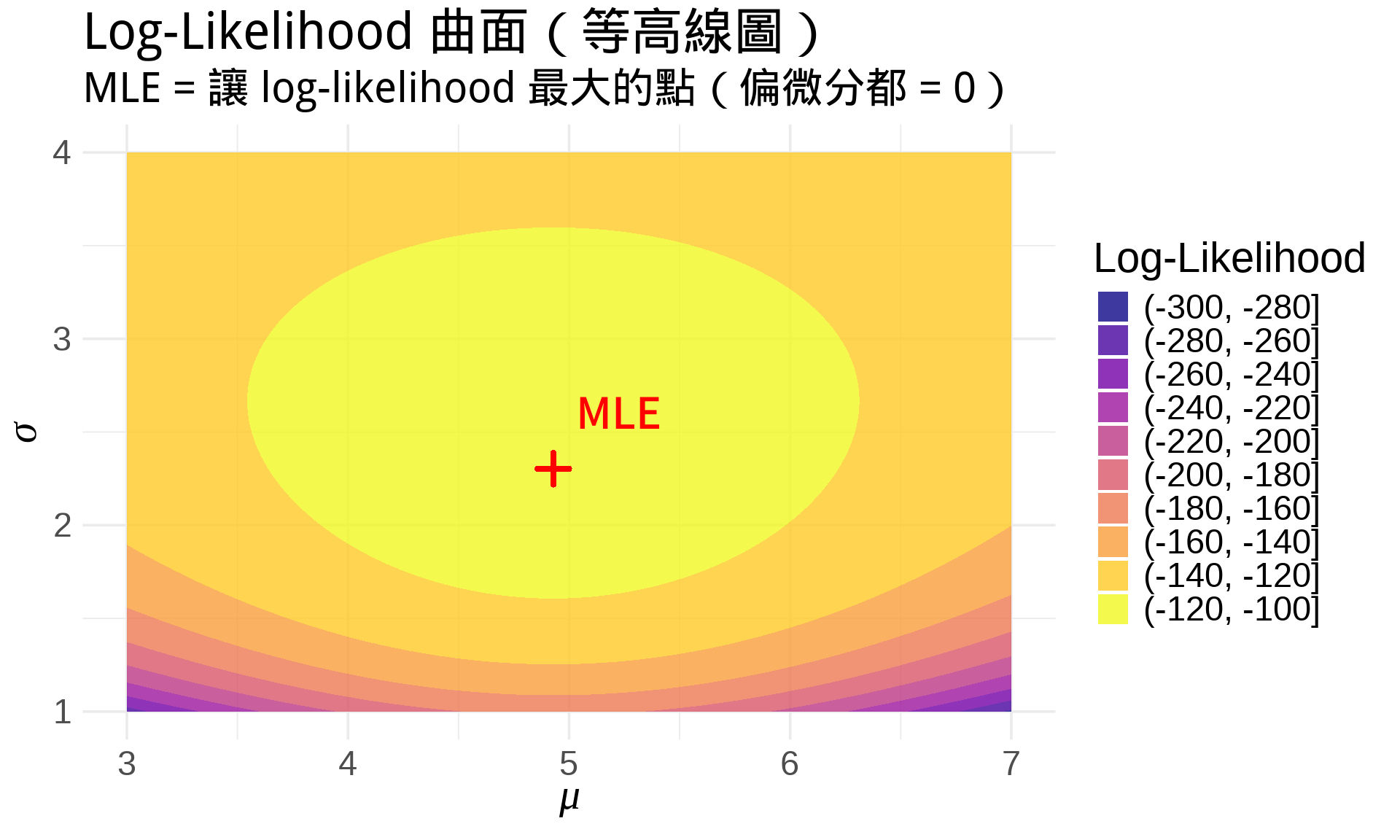
#| fig-cap: "對數概似函數的 3D 曲面(MLE 就是找最高點)"
# 模擬資料
set.seed(42)
data <- rnorm(50, mean = 5, sd = 2)
# Log-likelihood 函數
log_lik <- function(mu, sigma) {
n <- length(data)
-n/2 * log(2*pi) - n*log(sigma) -
sum((data - mu)^2) / (2 * sigma^2)
}
# 建立網格
mu_seq <- seq(3, 7, length.out = 100)
sigma_seq <- seq(1, 4, length.out = 100)
ll_grid <- expand.grid(mu = mu_seq, sigma = sigma_seq)
ll_grid$ll <- mapply(log_lik, ll_grid$mu, ll_grid$sigma)
# 找 MLE
mu_mle <- mean(data)
sigma_mle <- sd(data)
ggplot(ll_grid, aes(mu, sigma, z = ll)) +
geom_contour_filled(alpha = 0.8) +
geom_point(aes(x = mu_mle, y = sigma_mle),
color = "red", size = 4, shape = 3, stroke = 2) +
annotate("text", x = mu_mle + 0.3, y = sigma_mle + 0.3,
label = "MLE", color = "red", fontface = "bold", size = 5) +
scale_fill_viridis_d(option = "plasma", name = "Log-Likelihood") +
labs(
title = "Log-Likelihood 曲面(等高線圖)",
subtitle = "MLE = 讓 log-likelihood 最大的點(偏微分都 = 0)",
x = expression(mu),
y = expression(sigma)
) +
theme_minimal(base_size = 14)
```
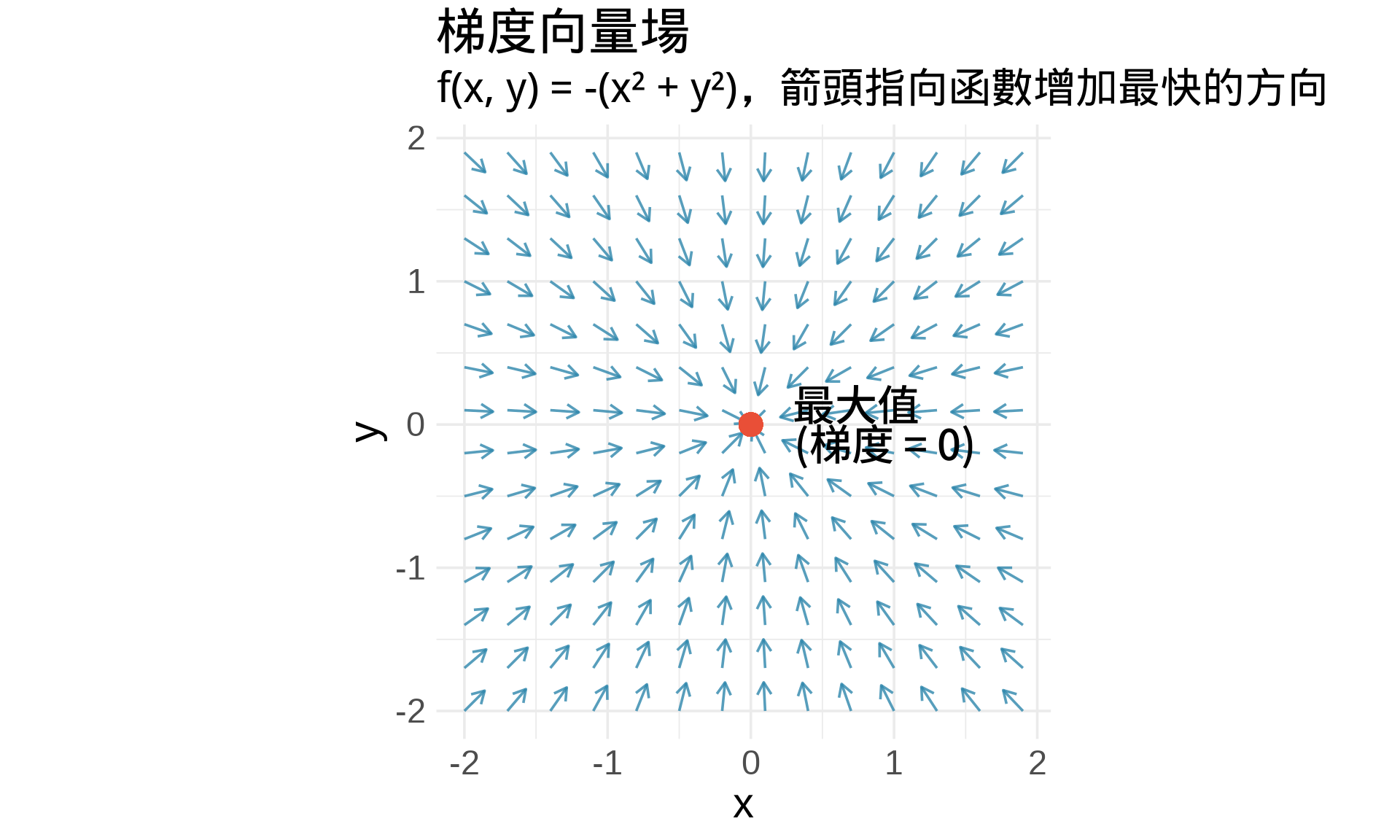
## 梯度 (Gradient)
### 定義
把所有偏微分組成一個向量,叫做**梯度** (gradient) [@bishop2006pattern]:
$$\nabla f = \left( \frac{\partial f}{\partial x}, \frac{\partial f}{\partial y} \right)$$
讀音:「nabla f」或「grad f」
### 幾何意義
**梯度向量指向函數上升最快的方向** [@murphy2012machine]
```{r}
#| label: fig-gradient
#| fig-cap: "梯度向量場:箭頭指向函數上升最快的方向"
# 函數 f(x, y) = -(x² + y²)(向下的拋物面)
f <- function(x, y) -(x^2 + y^2)
fx <- function(x, y) -2*x
fy <- function(x, y) -2*y
# 建立向量場
grid <- expand.grid(
x = seq(-2, 2, by = 0.3),
y = seq(-2, 2, by = 0.3)
)
grid$dx <- fx(grid$x, grid$y)
grid$dy <- fy(grid$x, grid$y)
# 正規化箭頭長度
grid$length <- sqrt(grid$dx^2 + grid$dy^2)
grid$dx_norm <- grid$dx / grid$length * 0.2
grid$dy_norm <- grid$dy / grid$length * 0.2
ggplot(grid) +
geom_segment(
aes(x = x, y = y, xend = x + dx_norm, yend = y + dy_norm),
arrow = arrow(length = unit(0.1, "inches")),
color = "#2E86AB", alpha = 0.8
) +
geom_point(aes(x = 0, y = 0), color = "#E94F37", size = 5) +
annotate("text", x = 0.3, y = 0, label = "最大值\n(梯度 = 0)", hjust = 0) +
coord_equal() +
labs(
title = "梯度向量場",
subtitle = "f(x, y) = -(x² + y²),箭頭指向函數增加最快的方向",
x = "x", y = "y"
) +
theme_minimal(base_size = 14)
```
**重點**:
- 梯度向量指向**上升**方向
- 梯度的**大小**代表上升的**速度**
- 在極值點,梯度 = $(0, 0)$(所有偏微分都 = 0)
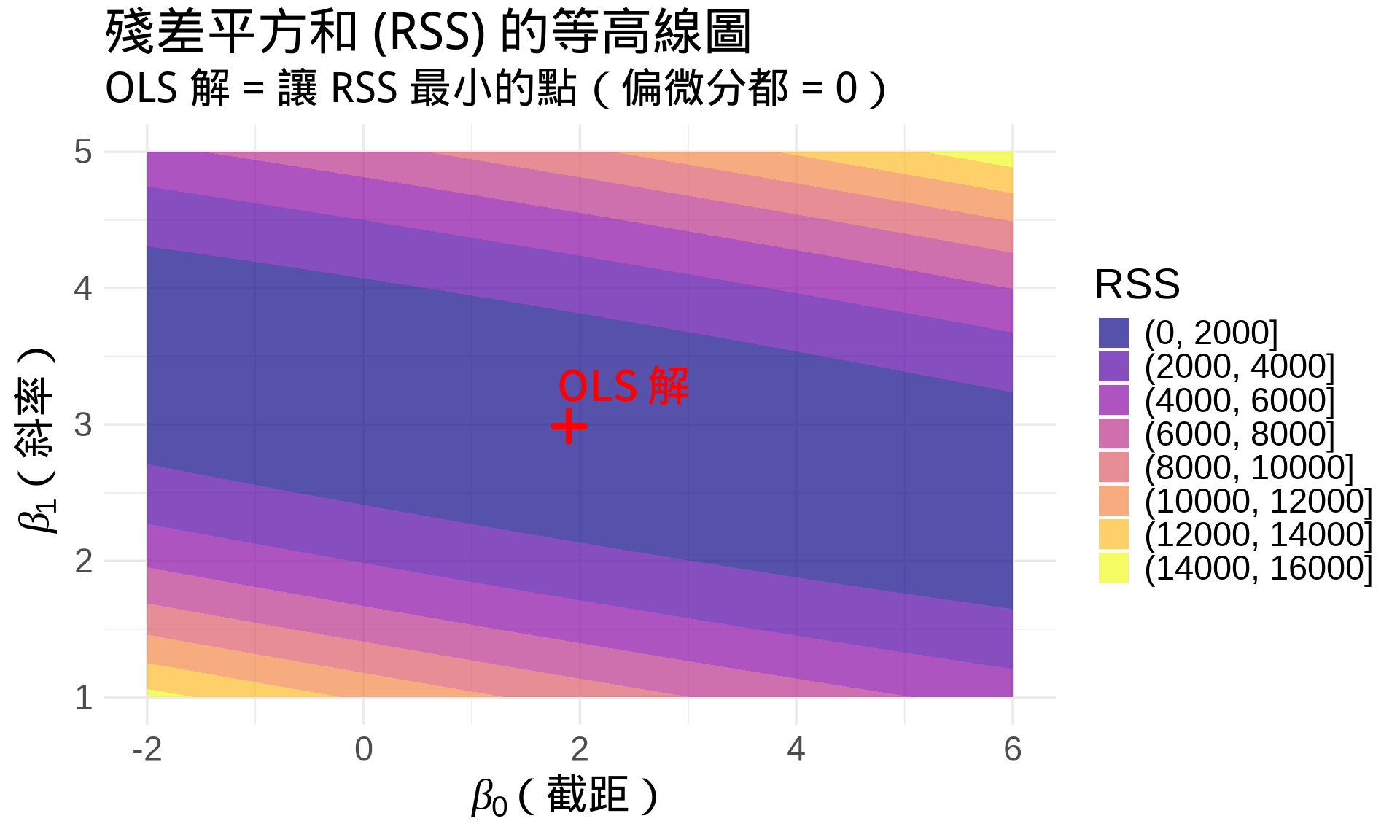
## 統計應用 1:多元迴歸
### 線性迴歸的矩陣形式
$$\mathbf{Y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon}$$
我們要最小化**殘差平方和** (RSS) [@hastie2009elements]:
$$\text{RSS}(\boldsymbol{\beta}) = \sum_{i=1}^n (y_i - \hat{y}_i)^2$$
這是一個**多變量函數**:$\boldsymbol{\beta} = (\beta_0, \beta_1, \beta_2, \ldots, \beta_p)$
### 最小二乘法的推導
**步驟**:
1. 對每個 $\beta_j$ 偏微分
2. 令所有偏微分 = 0
3. 解聯立方程組
**結果**(矩陣形式) [@casella2002statistical]:
$$\hat{\boldsymbol{\beta}} = (\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{Y}$$
```{r}
#| label: fig-regression-surface
#| fig-cap: "簡單迴歸的 RSS 曲面(兩個參數:截距與斜率)"
# 模擬資料
set.seed(42)
x <- runif(50, 0, 10)
y <- 2 + 3*x + rnorm(50, sd = 3)
# RSS 函數
rss <- function(b0, b1) {
sum((y - (b0 + b1 * x))^2)
}
# 建立網格
b0_seq <- seq(-2, 6, length.out = 100)
b1_seq <- seq(1, 5, length.out = 100)
rss_grid <- expand.grid(b0 = b0_seq, b1 = b1_seq)
rss_grid$rss <- mapply(rss, rss_grid$b0, rss_grid$b1)
# OLS 解
fit <- lm(y ~ x)
b0_ols <- coef(fit)[1]
b1_ols <- coef(fit)[2]
ggplot(rss_grid, aes(b0, b1, z = rss)) +
geom_contour_filled(alpha = 0.7) +
geom_point(aes(x = b0_ols, y = b1_ols),
color = "red", size = 4, shape = 3, stroke = 2) +
annotate("text", x = b0_ols + 0.5, y = b1_ols + 0.3,
label = "OLS 解", color = "red", fontface = "bold") +
scale_fill_viridis_d(option = "plasma", name = "RSS") +
labs(
title = "殘差平方和 (RSS) 的等高線圖",
subtitle = "OLS 解 = 讓 RSS 最小的點(偏微分都 = 0)",
x = expression(beta[0]~"(截距)"),
y = expression(beta[1]~"(斜率)")
) +
theme_minimal(base_size = 14)
```
## 統計應用 2:多參數 MLE
### 問題設定
假設我們要估計常態分布的**兩個參數** $\mu$ 和 $\sigma$ [@casella2002statistical]:
$$L(\mu, \sigma \mid x_1, \ldots, x_n) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x_i - \mu)^2}{2\sigma^2}}$$
取 log:
$$\log L(\mu, \sigma) = -\frac{n}{2}\log(2\pi) - n\log\sigma - \frac{1}{2\sigma^2}\sum_{i=1}^n (x_i - \mu)^2$$
### 最大化過程
**步驟** [@murphy2012machine]:
1. 對 $\mu$ 偏微分,令 = 0
2. 對 $\sigma$ 偏微分,令 = 0
3. 解聯立方程組
**結果**:
$$\hat{\mu}_{\text{MLE}} = \bar{x} = \frac{1}{n}\sum_{i=1}^n x_i$$
$$\hat{\sigma}_{\text{MLE}} = \sqrt{\frac{1}{n}\sum_{i=1}^n (x_i - \bar{x})^2}$$
```{r}
#| label: fig-mle-3d
#| fig-cap: "MLE 的 3D 視覺化(找最高點)"
# 重複使用前面的資料
z_matrix <- matrix(ll_grid$ll, nrow = 100, ncol = 100)
plot_ly(
x = mu_seq,
y = sigma_seq,
z = z_matrix,
type = "surface",
colorscale = list(c(0, "#2E86AB"), c(1, "#E94F37"))
) %>%
add_trace(
x = c(mu_mle), y = c(sigma_mle), z = c(log_lik(mu_mle, sigma_mle)),
type = "scatter3d", mode = "markers",
marker = list(size = 8, color = "red", symbol = "x")
) %>%
layout(
title = "Log-Likelihood 的 3D 曲面",
scene = list(
xaxis = list(title = "μ"),
yaxis = list(title = "σ"),
zaxis = list(title = "log L(μ, σ)")
)
)
```
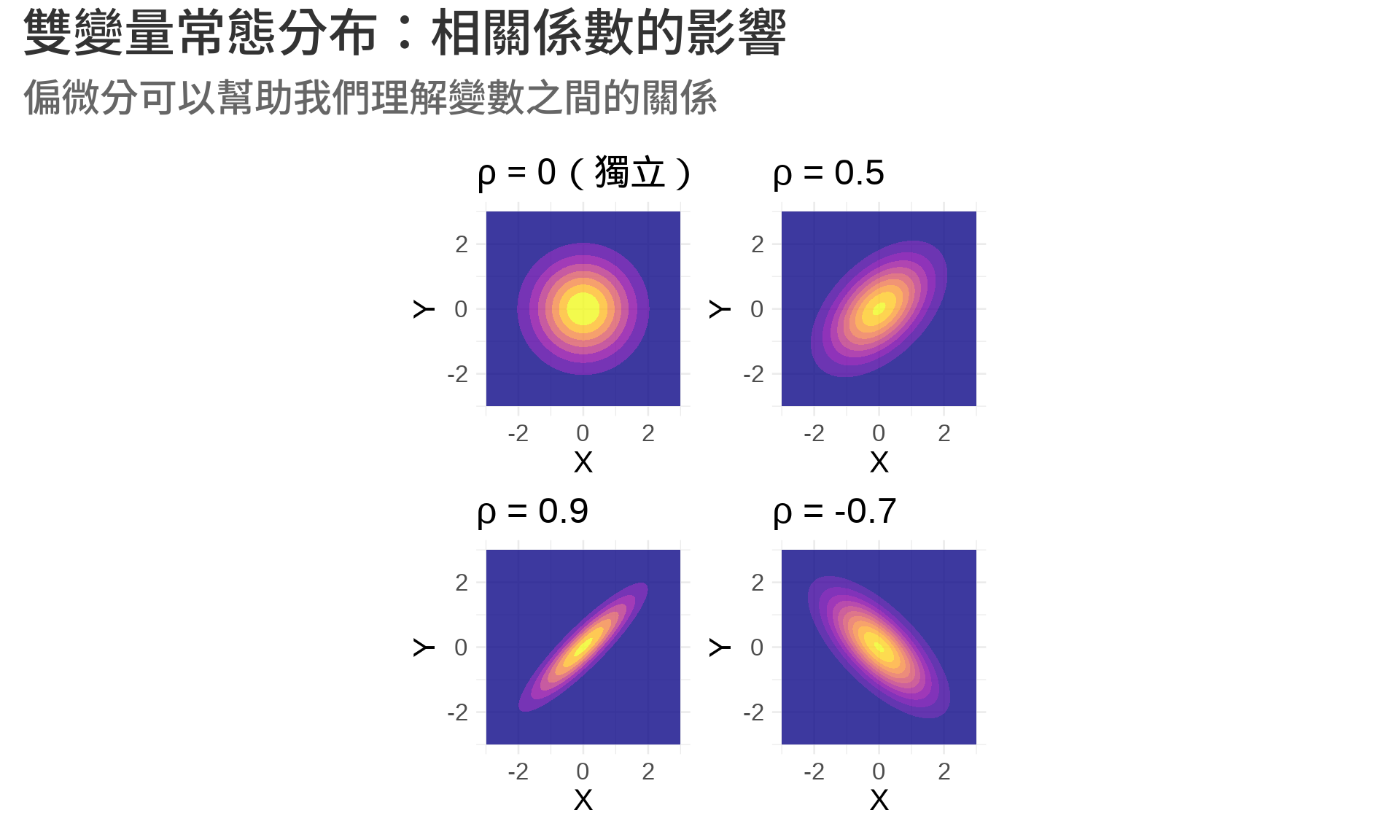
## 統計應用 3:聯合機率分布
### 雙變量常態分布
兩個變數 $X$ 和 $Y$ 的聯合機率密度函數 [@bishop2006pattern]:
$$f(x, y) = \frac{1}{2\pi\sigma_X\sigma_Y\sqrt{1-\rho^2}} \exp\left(-\frac{1}{2(1-\rho^2)}\left[\frac{(x-\mu_X)^2}{\sigma_X^2} + \frac{(y-\mu_Y)^2}{\sigma_Y^2} - \frac{2\rho(x-\mu_X)(y-\mu_Y)}{\sigma_X\sigma_Y}\right]\right)$$
其中 $\rho$ 是**相關係數** (correlation coefficient)。
```{r}
#| label: fig-bivariate-normal-corr
#| fig-cap: "不同相關係數的雙變量常態分布"
library(MASS) # 用於 mvrnorm
# 函數:產生雙變量常態的等高線圖
plot_bivariate_normal <- function(rho, title) {
# 共變異數矩陣
Sigma <- matrix(c(1, rho, rho, 1), 2, 2)
# 建立網格
x <- seq(-3, 3, length.out = 100)
y <- seq(-3, 3, length.out = 100)
grid <- expand.grid(x = x, y = y)
# 計算密度
library(mvtnorm)
grid$density <- dmvnorm(as.matrix(grid), mean = c(0, 0), sigma = Sigma)
ggplot(grid, aes(x, y, z = density)) +
geom_contour_filled(alpha = 0.8) +
scale_fill_viridis_d(option = "plasma") +
labs(title = title, x = "X", y = "Y") +
coord_equal() +
theme_minimal(base_size = 10) +
theme(legend.position = "none")
}
p1 <- plot_bivariate_normal(0, "ρ = 0(獨立)")
p2 <- plot_bivariate_normal(0.5, "ρ = 0.5")
p3 <- plot_bivariate_normal(0.9, "ρ = 0.9")
p4 <- plot_bivariate_normal(-0.7, "ρ = -0.7")
(p1 | p2) / (p3 | p4) +
plot_annotation(
title = "雙變量常態分布:相關係數的影響",
subtitle = "偏微分可以幫助我們理解變數之間的關係"
)
```
**偏微分的應用**:
- $\frac{\partial^2 f}{\partial x \partial y}$(混合偏微分)與相關性有關
- 如果 $X$ 和 $Y$ 獨立,則 $\frac{\partial^2 f}{\partial x \partial y} = 0$
## 練習題
### 觀念題
1. 用自己的話解釋:什麼是「偏微分」?為什麼叫「偏」?
::: {.callout-tip collapse="true" title="參考答案"}
偏微分就是「固定其他變數,只對一個變數做微分」。叫「偏」是因為我們只關注「偏向某一個方向」的變化率,而不是整體的變化。就像在曲面上只看 x 方向或 y 方向的斜率,而不是同時看所有方向。
:::
2. 在 3D 曲面 $z = f(x, y)$ 上,$\frac{\partial f}{\partial x}$ 的幾何意義是什麼?
::: {.callout-tip collapse="true" title="參考答案"}
$\frac{\partial f}{\partial x}$ 代表「固定 y 值,沿著 x 方向移動時,曲面的斜率」。幾何上,就是在曲面上沿 x 方向切一刀,得到的切面曲線在該點的斜率。這條切線的斜率告訴我們:當 x 增加一點點時,z 值會增加或減少多少。
:::
3. 為什麼在 MLE 中,我們要讓所有偏微分都等於 0?
::: {.callout-tip collapse="true" title="參考答案"}
因為我們要找 log-likelihood 的「最大值」。在多變量函數中,極值點(最大值或最小值)必定發生在梯度為零的地方,也就是所有偏微分都等於 0 的點。這就像爬山到山頂時,無論往哪個方向都是下坡(所有方向的斜率都是 0)。
:::
4. 梯度向量的方向代表什麼?大小代表什麼?
::: {.callout-tip collapse="true" title="參考答案"}
梯度向量的「方向」指向函數值增加最快的方向(最陡上升方向)。梯度的「大小」代表在該方向上函數值增加的速度有多快。如果梯度很大,表示函數在該點變化很劇烈;如果梯度接近零,表示接近極值點或平坦區域。
:::
### 計算題
5. 計算以下函數的偏微分:
a. $f(x, y) = x^3 + 2xy + y^2$
b. $f(x, y) = e^{xy}$
c. $f(x, y) = \log(x^2 + y^2)$
::: {.callout-tip collapse="true" title="參考答案"}
a. $\frac{\partial f}{\partial x} = 3x^2 + 2y$;$\frac{\partial f}{\partial y} = 2x + 2y$
b. 使用 chain rule:$\frac{\partial f}{\partial x} = ye^{xy}$;$\frac{\partial f}{\partial y} = xe^{xy}$
c. 使用 chain rule:$\frac{\partial f}{\partial x} = \frac{2x}{x^2 + y^2}$;$\frac{\partial f}{\partial y} = \frac{2y}{x^2 + y^2}$
:::
6. 給定函數 $f(x, y) = x^2 - 2xy + 3y^2$,求在點 $(1, 2)$ 的梯度向量。
::: {.callout-tip collapse="true" title="參考答案"}
先求偏微分:$\frac{\partial f}{\partial x} = 2x - 2y$;$\frac{\partial f}{\partial y} = -2x + 6y$。代入點 $(1, 2)$:$\frac{\partial f}{\partial x}|_{(1,2)} = 2(1) - 2(2) = -2$;$\frac{\partial f}{\partial y}|_{(1,2)} = -2(1) + 6(2) = 10$。因此梯度向量 $\nabla f(1, 2) = (-2, 10)$。
:::
### R 操作題
7. 修改以下程式碼,繪製函數 $f(x, y) = \sin(x) \cdot \cos(y)$ 的 3D 曲面:
```r
library(plotly)
x <- seq(-2*pi, 2*pi, length.out = 50)
y <- seq(-2*pi, 2*pi, length.out = 50)
# 在這裡修改函數
z <- outer(x, y, function(x, y) _______)
plot_ly(x = x, y = y, z = z, type = "surface")
```
::: {.callout-tip collapse="true" title="參考答案"}
將空白處填入 `sin(x) * cos(y)` 即可。完整程式碼:
```r
z <- outer(x, y, function(x, y) sin(x) * cos(y))
```
觀察這個曲面的波浪狀結構,以及偏微分如何影響曲面在不同方向的變化。
:::
8. 產生 100 個來自常態分布 $N(10, 3)$ 的隨機數,然後繪製 log-likelihood 曲面(對 $\mu$ 和 $\sigma$),找出 MLE。
::: {.callout-tip collapse="true" title="參考答案"}
參考本章範例,程式碼架構如下:先產生資料 `data <- rnorm(100, mean = 10, sd = 3)`,建立 log-likelihood 函數,用 `expand.grid()` 建立參數網格,計算每個參數組合的 log-likelihood 值,最後用 `ggplot` 繪製等高線圖或用 `plotly` 繪製 3D 曲面。MLE 應該在 $\mu \approx 10$、$\sigma \approx 3$ 附近。
:::
### 統計連結題
9. 在多元線性迴歸中,我們有多個 $\beta$ 參數。說明如何用偏微分找到這些參數的估計值。
::: {.callout-tip collapse="true" title="參考答案"}
在多元迴歸中,RSS 是所有 $\beta$ 參數的函數:$\text{RSS}(\beta_0, \beta_1, \ldots, \beta_p)$。我們對每個 $\beta_j$ 分別做偏微分,得到 $p+1$ 個偏微分方程式,然後令它們全部等於 0。解這個聯立方程組,就得到 OLS 估計值。矩陣形式的解為 $\hat{\boldsymbol{\beta}} = (\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{Y}$。
:::
10. 解釋為什麼「調整共變數」(adjusting for covariates) 在數學上是一個多變量問題,需要用到偏微分的概念。
::: {.callout-tip collapse="true" title="參考答案"}
當我們說「調整年齡後,劑量對血壓的效果」,數學上就是在問:「固定年齡不變時,劑量改變對血壓的影響」,這正是偏微分的定義!在多變量函數 $\text{血壓} = f(\text{劑量}, \text{年齡})$ 中,$\frac{\partial f}{\partial \text{劑量}}$ 就代表「控制年齡後的劑量效果」。這就是為什麼多元迴歸的係數可以解釋為「調整其他變數後的效果」。
:::
## 本章重點整理 {.unnumbered}
✅ **多變量函數**:$z = f(x, y)$ 可以用 3D 曲面或等高線圖視覺化
✅ **偏微分**:固定其他變數,對一個變數微分;符號 $\frac{\partial f}{\partial x}$
✅ **幾何意義**:偏微分 = 某個方向的切線斜率
✅ **梯度**:$\nabla f = (\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y})$,指向函數上升最快的方向
✅ **統計應用**:
- 多元迴歸:對每個 $\beta$ 偏微分,令 = 0,得 OLS 解
- 多參數 MLE:對每個參數偏微分,令 = 0,得 MLE
- 聯合分布:描述多個變數的同時機率
✅ **核心思想**:在多變量世界中,「變化率」取決於「方向」,偏微分讓我們能精確描述每個方向的變化