---
title: "Chapter 12: 多重積分 (Multiple Integrals)"
---
```{r}
#| include: false
source(here::here("R/_common.R"))
```
## 學習目標 {.unnumbered}
- 理解雙重積分的幾何意義(體積)
- 掌握積分順序與積分範圍的設定
- 理解聯合機率分布與邊際分布的關係
- 用多重積分計算期望值與變異數
- 連結到貝氏統計的後驗分布計算
## 從單重積分到雙重積分
### 回顧:單重積分
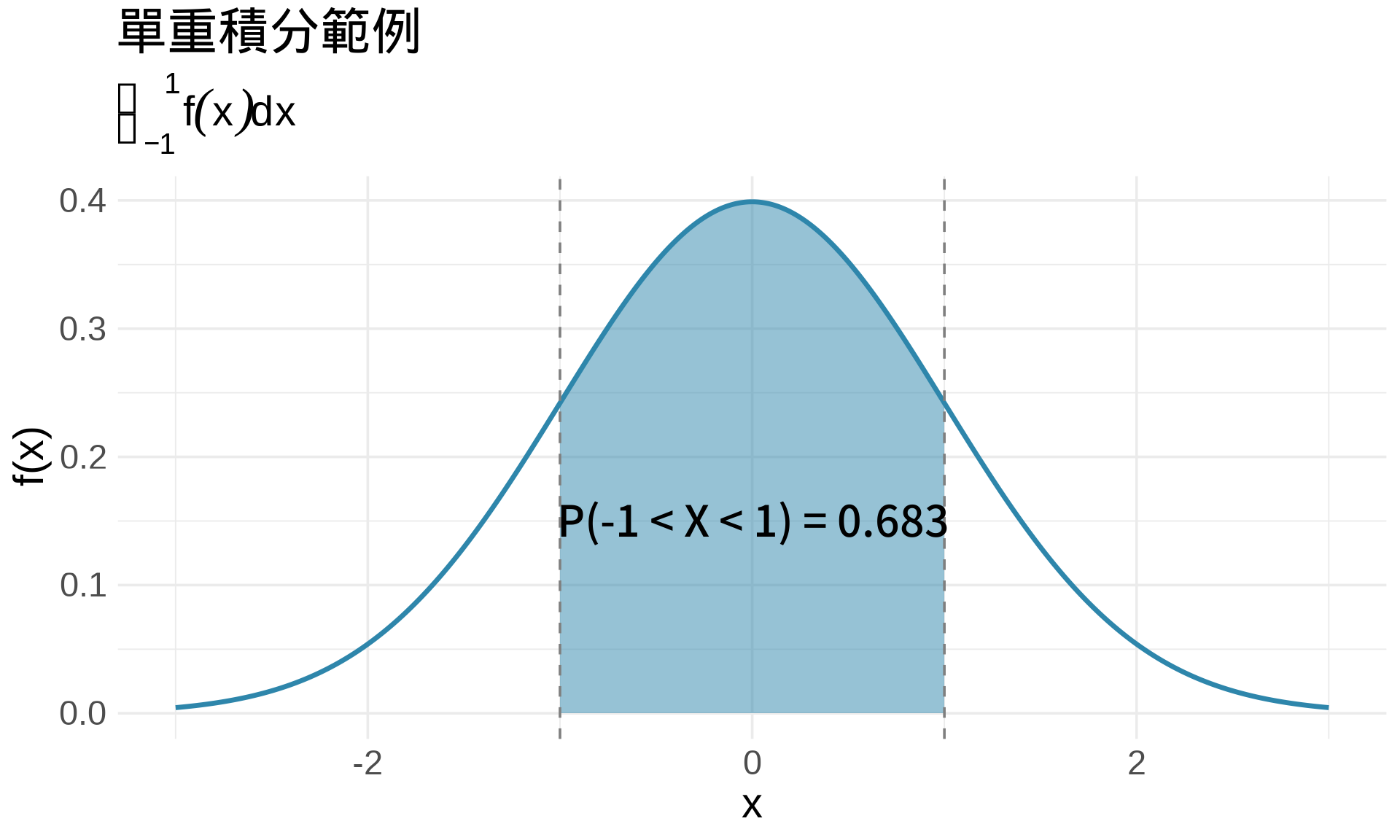
在單變量情況,積分代表**曲線下面積**:
$$\int_a^b f(x) \, dx = \text{面積}$$
```{r}
#| label: fig-single-integral
#| fig-cap: "單重積分:曲線下面積"
# 標準常態 PDF
x <- seq(-3, 3, by = 0.01)
y <- dnorm(x)
# 計算 P(-1 < X < 1)
df <- data.frame(x = x, y = y)
df_shade <- df[df$x >= -1 & df$x <= 1, ]
ggplot(df, aes(x, y)) +
geom_line(color = "#2E86AB", linewidth = 1.2) +
geom_area(data = df_shade, fill = "#2E86AB", alpha = 0.5) +
geom_vline(xintercept = c(-1, 1), linetype = "dashed", color = "gray50") +
annotate("text", x = 0, y = 0.15,
label = sprintf("P(-1 < X < 1) = %.3f", pnorm(1) - pnorm(-1)),
size = 5, fontface = "bold") +
labs(
title = "單重積分範例",
subtitle = expression(integral(f(x)*dx, -1, 1)),
x = "x", y = "f(x)"
) +
theme_minimal(base_size = 14)
```
### 雙重積分:體積
在多變量情況,**雙重積分**代表**曲面下體積**:
$$\int_a^b \int_c^d f(x, y) \, dy \, dx = \text{體積}$$
```{r}
#| label: fig-double-integral-concept
#| fig-cap: "雙重積分:曲面下體積"
library(plotly)
# 建立雙變量常態 PDF
library(mvtnorm)
x <- seq(-3, 3, length.out = 50)
y <- seq(-3, 3, length.out = 50)
z <- outer(x, y, function(x, y) {
dmvnorm(cbind(x, y), mean = c(0, 0), sigma = diag(2))
})
plot_ly(
x = x, y = y, z = z,
type = "surface",
colorscale = list(c(0, "#2E86AB"), c(1, "#E94F37"))
) %>%
layout(
title = "雙重積分 = 曲面下體積",
scene = list(
xaxis = list(title = "X"),
yaxis = list(title = "Y"),
zaxis = list(title = "f(X, Y)")
)
)
```
**關鍵理解** [@thomas2018calculus]:
- **單重積分**:$\int f(x) dx$ = 1D 曲線下的 **2D 面積**
- **雙重積分**:$\iint f(x,y) dx dy$ = 2D 曲面下的 **3D 體積**
- **三重積分**:$\iiint f(x,y,z) dx dy dz$ = 3D 函數的 **4D 超體積**(無法視覺化,但數學上成立)
## 雙重積分的計算
### 逐次積分 (Iterated Integrals)
雙重積分可以拆成**兩次單重積分**:
$$\int_a^b \int_c^d f(x, y) \, dy \, dx = \int_a^b \left[ \int_c^d f(x, y) \, dy \right] dx$$
**步驟**:
1. **內層積分**:先對 $y$ 積分(把 $x$ 當常數),積分範圍 $[c, d]$
2. **外層積分**:再對 $x$ 積分,積分範圍 $[a, b]$
### 範例 1:矩形區域
$$\int_0^2 \int_0^3 (x + y) \, dy \, dx$$
**計算過程**:
**步驟 1**:內層積分(對 $y$,固定 $x$)
$$\int_0^3 (x + y) \, dy = \left[ xy + \frac{y^2}{2} \right]_0^3 = 3x + \frac{9}{2}$$
**步驟 2**:外層積分(對 $x$)
$$\int_0^2 \left(3x + \frac{9}{2}\right) dx = \left[\frac{3x^2}{2} + \frac{9x}{2}\right]_0^2 = 6 + 9 = 15$$
```{r}
#| label: fig-rectangular-region
#| fig-cap: "矩形區域的雙重積分"
# 函數 f(x, y) = x + y
f <- function(x, y) x + y
x <- seq(0, 2, length.out = 50)
y <- seq(0, 3, length.out = 50)
z <- outer(x, y, f)
plot_ly(x = x, y = y, z = z, type = "surface",
colorscale = list(c(0, "#2E86AB"), c(1, "#E94F37"))) %>%
layout(
title = "f(x, y) = x + y 在 [0,2] × [0,3]",
scene = list(
xaxis = list(title = "x", range = c(0, 2)),
yaxis = list(title = "y", range = c(0, 3)),
zaxis = list(title = "f(x,y)")
)
)
cat("體積(用 R 數值積分驗證):\n")
library(pracma)
result <- integral2(f, 0, 2, 0, 3)
cat("數值積分結果 =", result$Q, "\n")
cat("解析解 = 15\n")
```
### 積分順序可交換嗎?
**Fubini's Theorem** [@casella2002statistical]:如果函數在矩形區域上連續,則積分順序可交換:
$$\int_a^b \int_c^d f(x, y) \, dy \, dx = \int_c^d \int_a^b f(x, y) \, dx \, dy$$
```{r}
#| label: fig-order-exchange
#| fig-cap: "積分順序交換驗證"
# 方法 1:先 y 後 x
method1 <- function() {
integrate(function(x) {
sapply(x, function(xi) {
integrate(function(y) xi + y, 0, 3)$value
})
}, 0, 2)$value
}
# 方法 2:先 x 後 y
method2 <- function() {
integrate(function(y) {
sapply(y, function(yi) {
integrate(function(x) x + yi, 0, 2)$value
})
}, 0, 3)$value
}
cat("先對 y 積分,再對 x 積分:", method1(), "\n")
cat("先對 x 積分,再對 y 積分:", method2(), "\n")
cat("結果相同!\n")
```
## 統計應用 1:聯合機率分布
### 聯合機率密度函數 (Joint PDF)
兩個連續隨機變數 $X$ 和 $Y$ 的**聯合 PDF** $f(x, y)$ 滿足 [@casella2002statistical]:
$$\int_{-\infty}^{\infty} \int_{-\infty}^{\infty} f(x, y) \, dx \, dy = 1$$
這是**雙重積分的第一個統計應用**:總機率 = 1。
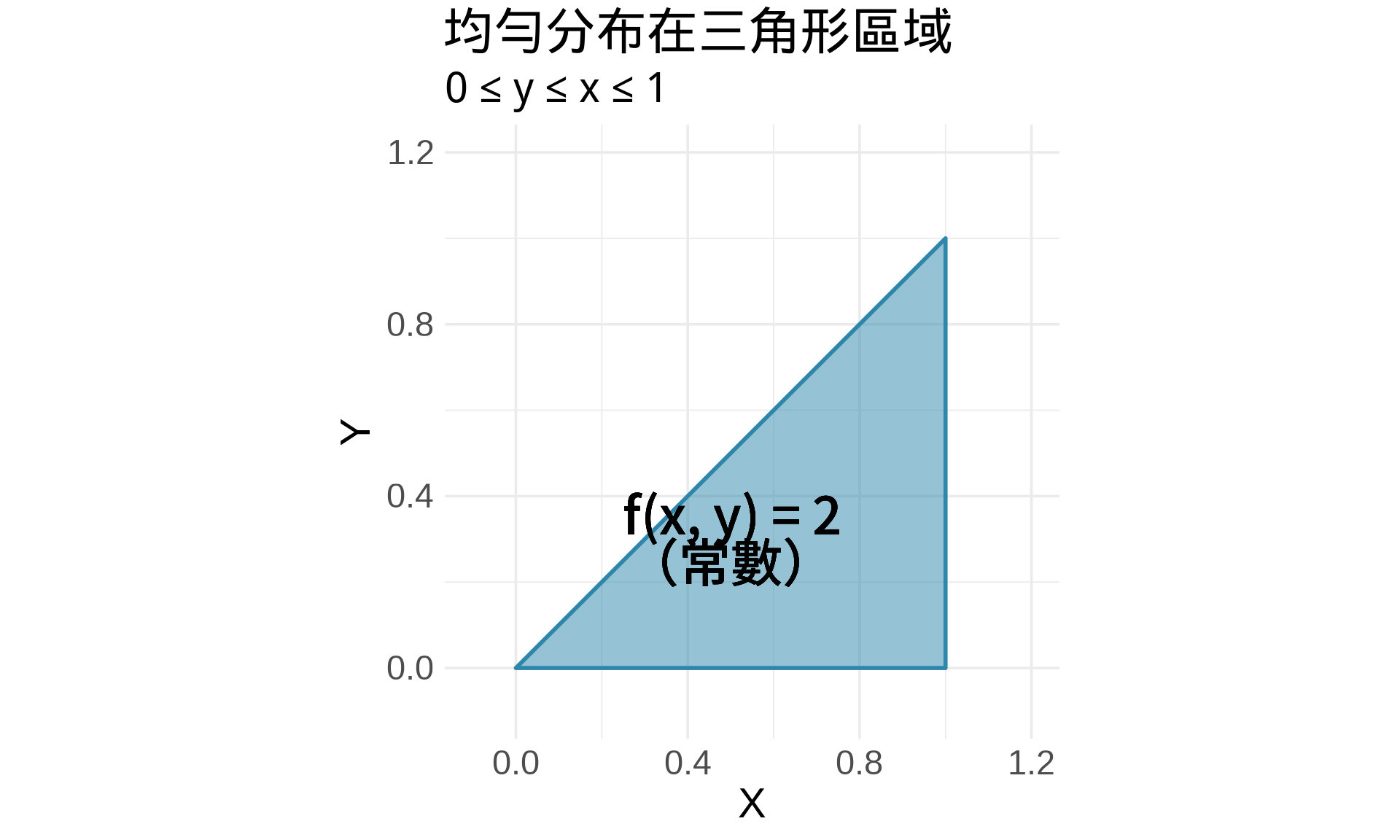
### 範例:均勻分布在三角形區域
假設 $(X, Y)$ 均勻分布在三角形區域:$0 \le y \le x \le 1$
```{r}
#| label: fig-triangular-region
#| fig-cap: "三角形區域上的均勻分布"
# 三角形頂點
triangle <- data.frame(
x = c(0, 1, 1, 0),
y = c(0, 0, 1, 0)
)
ggplot(triangle, aes(x, y)) +
geom_polygon(fill = "#2E86AB", alpha = 0.5, color = "#2E86AB", linewidth = 1) +
geom_text(aes(x = 0.5, y = 0.3),
label = "f(x, y) = 2\n(常數)",
size = 6, fontface = "bold") +
coord_equal(xlim = c(-0.1, 1.2), ylim = c(-0.1, 1.2)) +
labs(
title = "均勻分布在三角形區域",
subtitle = "0 ≤ y ≤ x ≤ 1",
x = "X", y = "Y"
) +
theme_minimal(base_size = 14)
```
**問題**:$f(x, y)$ 是多少才能讓總機率 = 1?
**解答**:
三角形面積 = $\frac{1}{2}$,所以 $f(x, y) = \frac{1}{1/2} = 2$(常數)。
**驗證**:
$$\int_0^1 \int_0^x 2 \, dy \, dx = \int_0^1 2x \, dx = \left[x^2\right]_0^1 = 1 \quad \checkmark$$
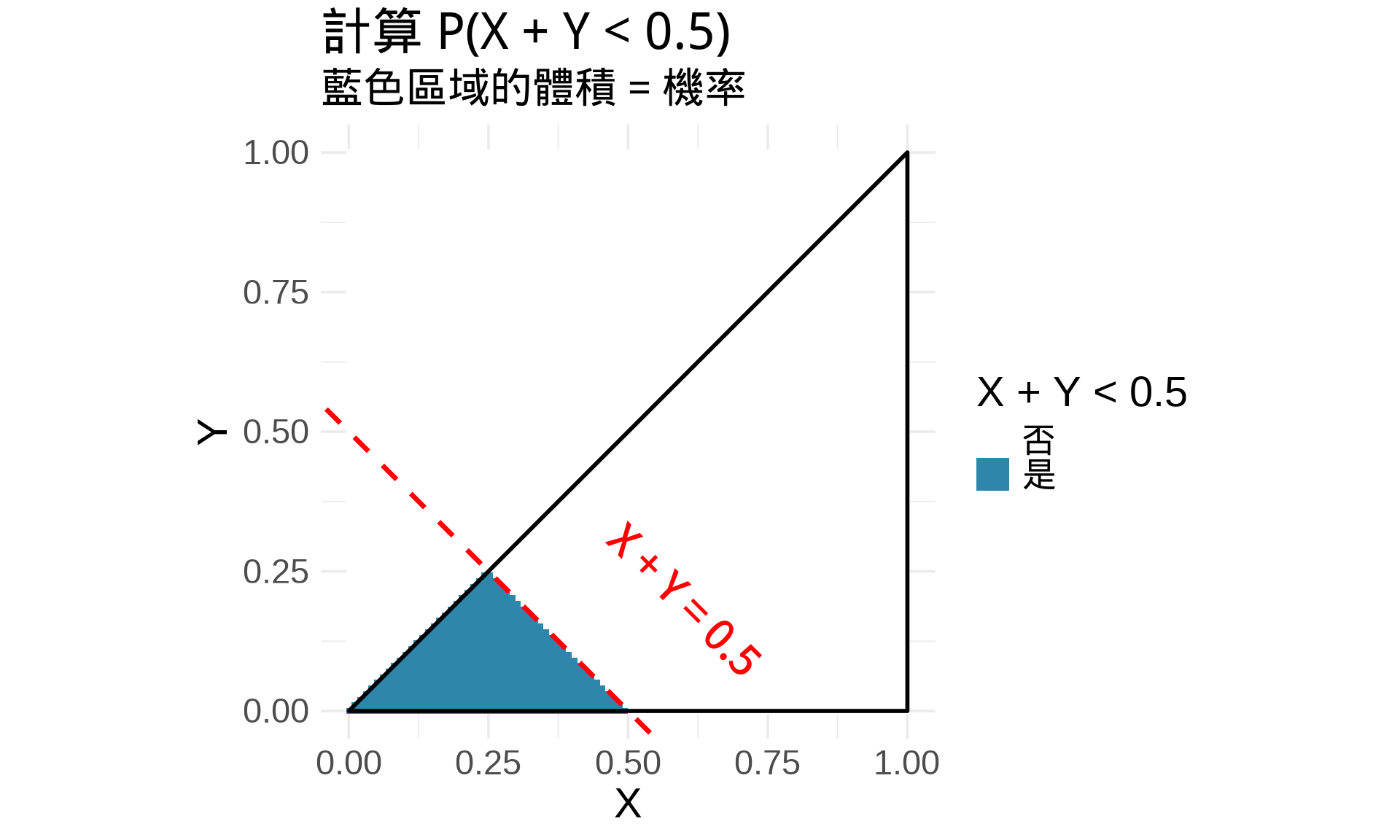
### 計算機率
$$P(X + Y < 0.5) = \int \int_{x+y<0.5} f(x, y) \, dy \, dx$$
```{r}
#| label: fig-probability-region
#| fig-cap: "計算 P(X + Y < 0.5)"
# 視覺化滿足條件的區域
grid <- expand.grid(
x = seq(0, 1, length.out = 100),
y = seq(0, 1, length.out = 100)
)
grid$in_triangle <- (grid$y <= grid$x) & (grid$y >= 0)
grid$satisfy_condition <- grid$in_triangle & (grid$x + grid$y < 0.5)
ggplot(grid, aes(x, y, fill = satisfy_condition)) +
geom_tile() +
geom_polygon(data = triangle, fill = NA, color = "black", linewidth = 1) +
geom_abline(intercept = 0.5, slope = -1, color = "red",
linewidth = 1.2, linetype = "dashed") +
scale_fill_manual(values = c("white", "#2E86AB"),
labels = c("否", "是"),
name = "X + Y < 0.5") +
annotate("text", x = 0.6, y = 0.2,
label = "X + Y = 0.5", color = "red", angle = -45) +
coord_equal(xlim = c(0, 1), ylim = c(0, 1)) +
labs(
title = "計算 P(X + Y < 0.5)",
subtitle = "藍色區域的體積 = 機率",
x = "X", y = "Y"
) +
theme_minimal(base_size = 14)
# 數值計算(使用簡化方法)
# 對於 x ∈ [0, 0.25],y 的上限是 x
# 對於 x ∈ [0.25, 0.5],y 的上限是 0.5 - x
prob1 <- integrate(function(x) 2 * x, 0, 0.25)$value
prob2 <- integrate(function(x) 2 * (0.5 - x), 0.25, 0.5)$value
prob <- prob1 + prob2
cat("P(X + Y < 0.5) =", round(prob, 4), "\n")
```
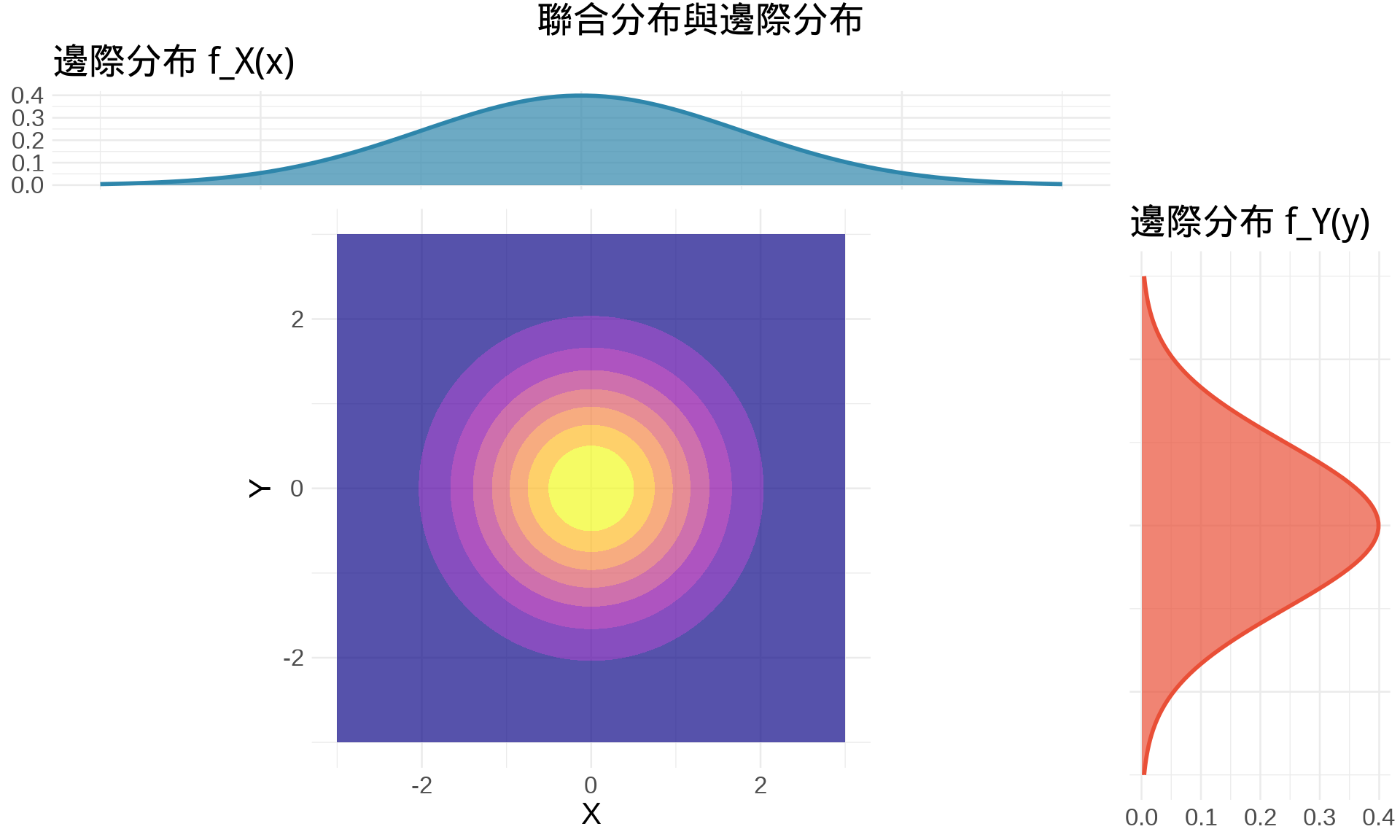
## 統計應用 2:邊際分布
### 邊際分布的定義
給定聯合 PDF $f(x, y)$,**邊際分布**是「積分掉」另一個變數 [@bishop2006pattern]:
$$f_X(x) = \int_{-\infty}^{\infty} f(x, y) \, dy$$
$$f_Y(y) = \int_{-\infty}^{\infty} f(x, y) \, dx$$
**直觀理解**:邊際分布 = 不考慮另一個變數時的機率分布。
### 範例:雙變量常態分布
標準雙變量常態($\rho = 0$,獨立情況) [@murphy2012machine]:
$$f(x, y) = \frac{1}{2\pi} e^{-\frac{x^2 + y^2}{2}}$$
**邊際分布**(對 $y$ 積分):
$$f_X(x) = \int_{-\infty}^{\infty} \frac{1}{2\pi} e^{-\frac{x^2 + y^2}{2}} \, dy$$
**技巧**:分離變數
$$f_X(x) = \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}} \cdot \underbrace{\int_{-\infty}^{\infty} \frac{1}{\sqrt{2\pi}} e^{-\frac{y^2}{2}} \, dy}_{=1}$$
$$f_X(x) = \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}}$$
這是**標準常態分布** $N(0, 1)$!
```{r}
#| label: fig-marginal-distribution
#| fig-cap: "從聯合分布到邊際分布"
library(mvtnorm)
# 聯合分布(3D)
x <- seq(-3, 3, length.out = 100)
y <- seq(-3, 3, length.out = 100)
z <- outer(x, y, function(x, y) {
dmvnorm(cbind(x, y), mean = c(0, 0), sigma = diag(2))
})
# 邊際分布
marginal_x <- dnorm(x)
marginal_y <- dnorm(y)
# 等高線圖 + 邊際分布
grid <- expand.grid(x = x, y = y)
grid$density <- dmvnorm(as.matrix(grid), mean = c(0, 0), sigma = diag(2))
p_main <- ggplot(grid, aes(x, y, z = density)) +
geom_contour_filled(alpha = 0.7) +
scale_fill_viridis_d(option = "plasma") +
coord_equal() +
labs(x = "X", y = "Y") +
theme_minimal(base_size = 10) +
theme(legend.position = "none")
p_top <- ggplot(data.frame(x, density = marginal_x), aes(x, density)) +
geom_area(fill = "#2E86AB", alpha = 0.7) +
geom_line(color = "#2E86AB", linewidth = 1) +
labs(title = "邊際分布 f_X(x)", y = NULL) +
theme_minimal(base_size = 10) +
theme(axis.text.x = element_blank(), axis.title.x = element_blank())
p_right <- ggplot(data.frame(y, density = marginal_y), aes(y, density)) +
geom_area(fill = "#E94F37", alpha = 0.7) +
geom_line(color = "#E94F37", linewidth = 1) +
coord_flip() +
labs(title = "邊際分布 f_Y(y)", y = NULL) +
theme_minimal(base_size = 10) +
theme(axis.text.y = element_blank(), axis.title.y = element_blank())
# 組合圖
library(gridExtra)
grid.arrange(
p_top, ggplot() + theme_void(),
p_main, p_right,
ncol = 2, nrow = 2,
widths = c(4, 1),
heights = c(1, 4),
top = "聯合分布與邊際分布"
)
```
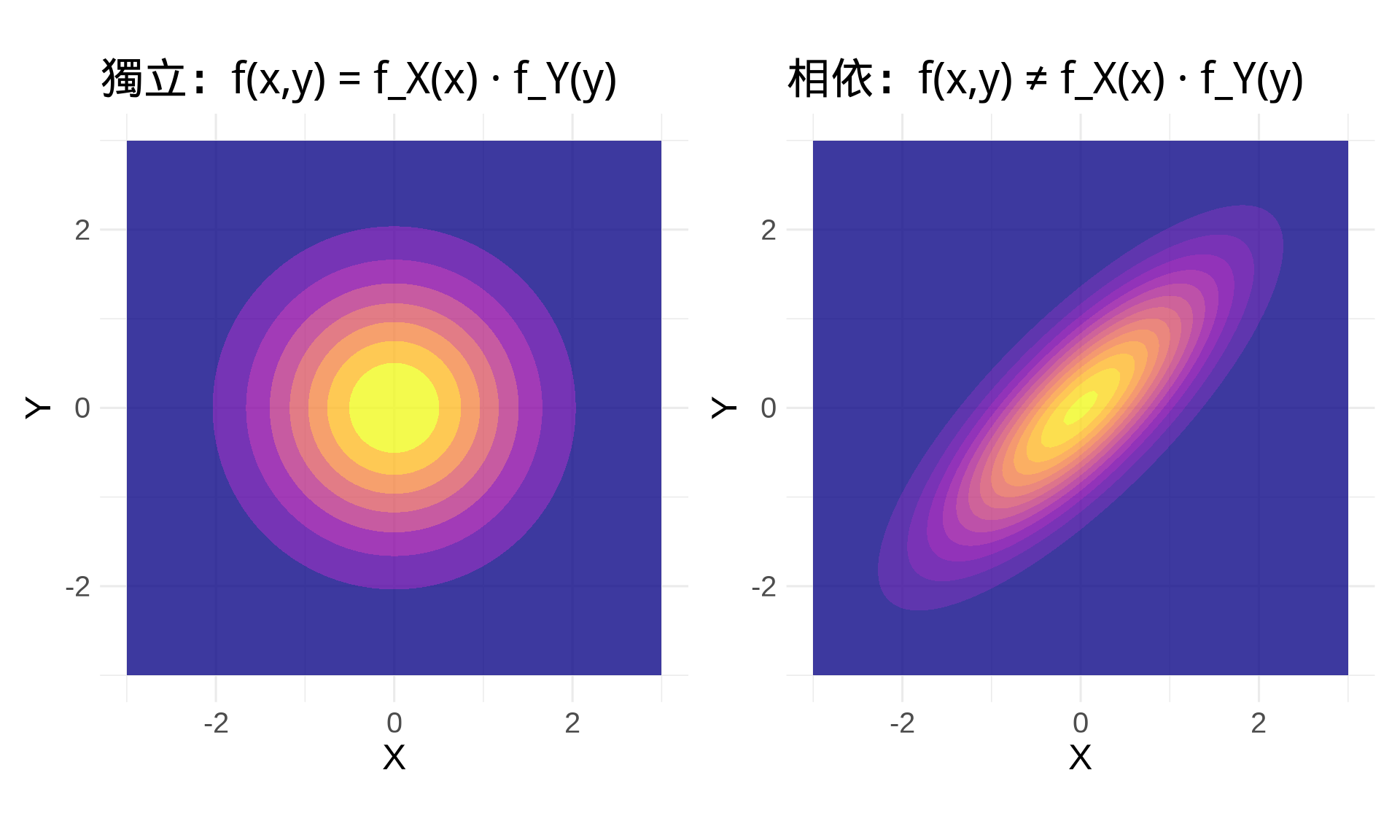
### 獨立性的判定
如果 $X$ 和 $Y$ 獨立,則:
$$f(x, y) = f_X(x) \cdot f_Y(y)$$
**反過來說**:如果 $f(x, y) \ne f_X(x) \cdot f_Y(y)$,則 $X$ 和 $Y$ 相依。
```{r}
#| label: fig-independence-check
#| fig-cap: "獨立 vs 相依的視覺對比"
# 獨立情況:ρ = 0
Sigma_indep <- diag(2)
# 相依情況:ρ = 0.8
Sigma_dep <- matrix(c(1, 0.8, 0.8, 1), 2, 2)
plot_distribution <- function(Sigma, title) {
grid <- expand.grid(
x = seq(-3, 3, length.out = 100),
y = seq(-3, 3, length.out = 100)
)
grid$density <- dmvnorm(as.matrix(grid), mean = c(0, 0), sigma = Sigma)
ggplot(grid, aes(x, y, z = density)) +
geom_contour_filled(alpha = 0.8) +
scale_fill_viridis_d(option = "plasma") +
coord_equal() +
labs(title = title, x = "X", y = "Y") +
theme_minimal(base_size = 12) +
theme(legend.position = "none")
}
p1 <- plot_distribution(Sigma_indep, "獨立:f(x,y) = f_X(x) · f_Y(y)")
p2 <- plot_distribution(Sigma_dep, "相依:f(x,y) ≠ f_X(x) · f_Y(y)")
p1 + p2
```
## 統計應用 3:期望值與變異數
### 多變量的期望值
$$E[g(X, Y)] = \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} g(x, y) \cdot f(x, y) \, dx \, dy$$
[@casella2002statistical]
**特殊情況**:
- $E[X] = \int \int x \cdot f(x, y) \, dx \, dy$
- $E[Y] = \int \int y \cdot f(x, y) \, dx \, dy$
- $E[XY] = \int \int xy \cdot f(x, y) \, dx \, dy$
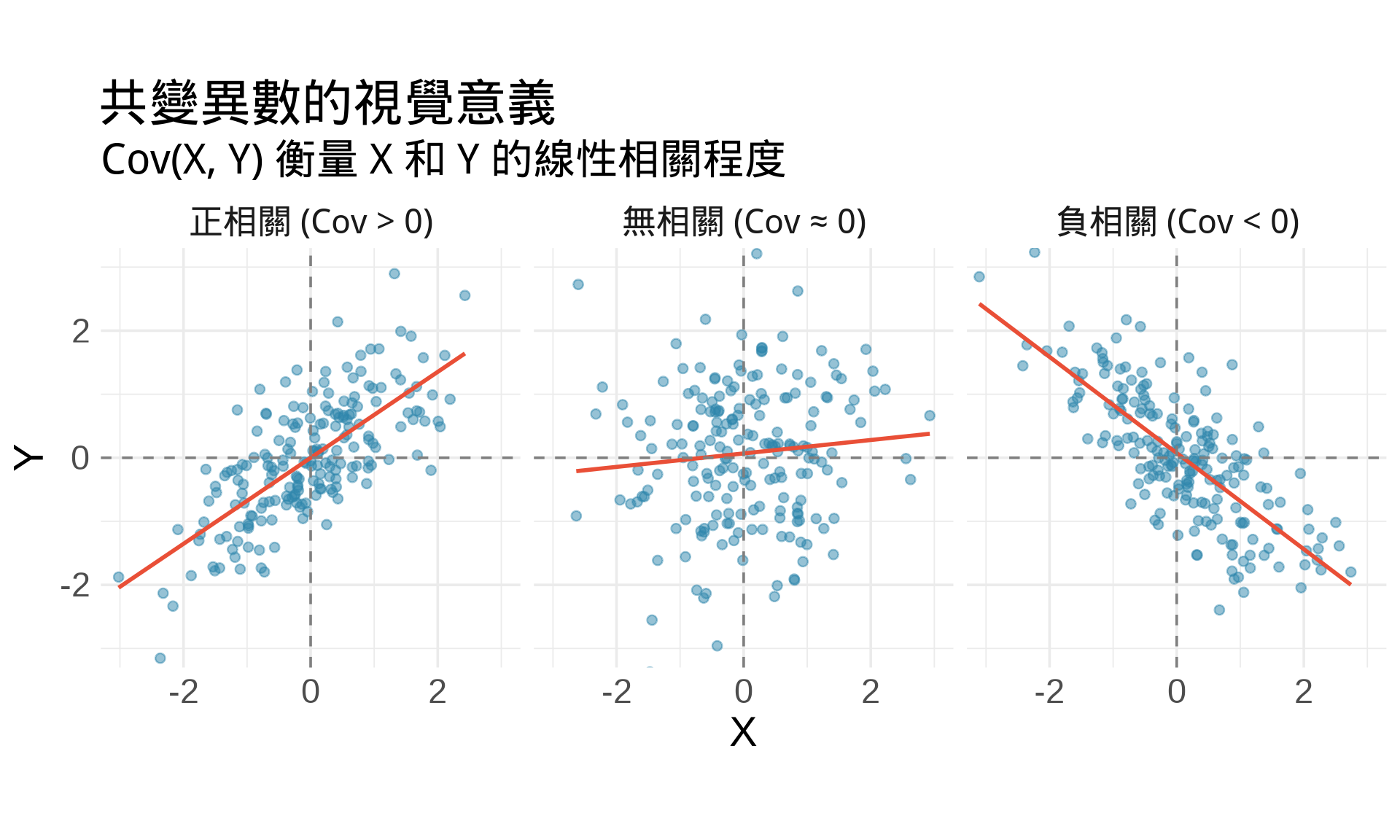
### 共變異數 (Covariance)
$$\text{Cov}(X, Y) = E[(X - E[X])(Y - E[Y])] = E[XY] - E[X]E[Y]$$
**計算方式**:
$$\text{Cov}(X, Y) = \int \int xy \cdot f(x, y) \, dx \, dy - \mu_X \mu_Y$$
```{r}
#| label: fig-covariance-calculation
#| fig-cap: "共變異數的幾何意義"
library(MASS)
# 模擬雙變量常態
set.seed(42)
n <- 200
# 正相關
data_pos <- data.frame(mvrnorm(n, mu = c(0, 0),
Sigma = matrix(c(1, 0.7, 0.7, 1), 2, 2)))
colnames(data_pos) <- c("X", "Y")
data_pos$type <- "正相關 (Cov > 0)"
# 負相關
data_neg <- data.frame(mvrnorm(n, mu = c(0, 0),
Sigma = matrix(c(1, -0.7, -0.7, 1), 2, 2)))
colnames(data_neg) <- c("X", "Y")
data_neg$type <- "負相關 (Cov < 0)"
# 無相關
data_zero <- data.frame(mvrnorm(n, mu = c(0, 0), Sigma = diag(2)))
colnames(data_zero) <- c("X", "Y")
data_zero$type <- "無相關 (Cov ≈ 0)"
data_all <- rbind(data_pos, data_neg, data_zero)
ggplot(data_all, aes(X, Y)) +
geom_point(alpha = 0.5, color = "#2E86AB") +
geom_smooth(method = "lm", se = FALSE, color = "#E94F37", linewidth = 1) +
geom_hline(yintercept = 0, linetype = "dashed", color = "gray50") +
geom_vline(xintercept = 0, linetype = "dashed", color = "gray50") +
facet_wrap(~ type, nrow = 1) +
coord_equal(xlim = c(-3, 3), ylim = c(-3, 3)) +
labs(
title = "共變異數的視覺意義",
subtitle = "Cov(X, Y) 衡量 X 和 Y 的線性相關程度"
) +
theme_minimal(base_size = 14)
```
## 統計應用 4:條件分布
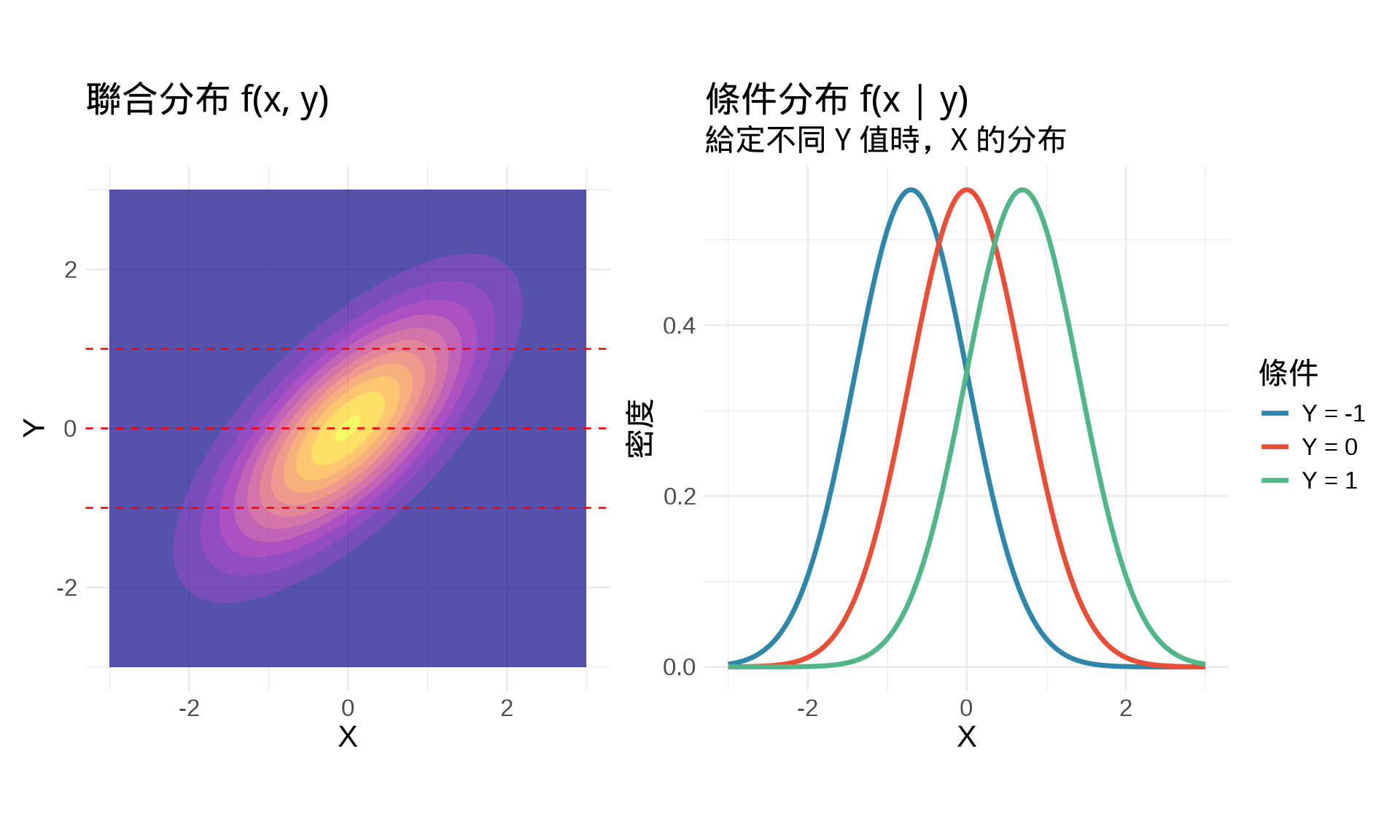
### 條件機率密度函數
給定 $Y = y$,$X$ 的**條件分布** [@casella2002statistical]:
$$f_{X|Y}(x|y) = \frac{f(x, y)}{f_Y(y)}$$
這需要兩個積分:
1. 計算邊際分布:$f_Y(y) = \int f(x, y) \, dx$
2. 代入條件分布公式
### 範例:雙變量常態的條件分布
對於雙變量常態 $(X, Y) \sim N(\mu, \Sigma)$,給定 $Y = y$,則 [@bishop2006pattern]:
$$X | Y = y \sim N\left(\mu_X + \rho \frac{\sigma_X}{\sigma_Y}(y - \mu_Y), \sigma_X^2(1 - \rho^2)\right)$$
這是**線性迴歸的理論基礎**!
```{r}
#| label: fig-conditional-distribution
#| fig-cap: "條件分布:給定 Y = y,X 的分布"
library(mvtnorm)
# 參數設定
rho <- 0.7
Sigma <- matrix(c(1, rho, rho, 1), 2, 2)
# 聯合分布
grid <- expand.grid(
x = seq(-3, 3, length.out = 200),
y = seq(-3, 3, length.out = 200)
)
grid$density <- dmvnorm(as.matrix(grid), mean = c(0, 0), sigma = Sigma)
# 等高線圖
p1 <- ggplot(grid, aes(x, y, z = density)) +
geom_contour_filled(alpha = 0.7) +
geom_hline(yintercept = c(-1, 0, 1), color = "red", linetype = "dashed") +
scale_fill_viridis_d(option = "plasma") +
coord_equal() +
labs(title = "聯合分布 f(x, y)", x = "X", y = "Y") +
theme_minimal(base_size = 10) +
theme(legend.position = "none")
# 條件分布(給定不同的 y 值)
y_values <- c(-1, 0, 1)
x_seq <- seq(-3, 3, length.out = 200)
cond_data <- do.call(rbind, lapply(y_values, function(y_val) {
# 條件期望值和標準差
cond_mean <- rho * y_val
cond_sd <- sqrt(1 - rho^2)
data.frame(
x = x_seq,
density = dnorm(x_seq, mean = cond_mean, sd = cond_sd),
y_given = paste0("Y = ", y_val)
)
}))
p2 <- ggplot(cond_data, aes(x, density, color = y_given)) +
geom_line(linewidth = 1.2) +
scale_color_manual(values = c("#2E86AB", "#E94F37", "#52B788"),
name = "條件") +
labs(
title = "條件分布 f(x | y)",
subtitle = "給定不同 Y 值時,X 的分布",
x = "X", y = "密度"
) +
theme_minimal(base_size = 10)
p1 + p2
```
## 統計應用 5:貝氏統計
### 後驗分布的計算
貝氏定理的連續版本 [@gelman2013bayesian]:
$$p(\theta | \text{data}) = \frac{p(\text{data} | \theta) \cdot p(\theta)}{p(\text{data})}$$
其中分母是**邊際概似** (marginal likelihood):
$$p(\text{data}) = \int p(\text{data} | \theta) \cdot p(\theta) \, d\theta$$
這是一個**積分**!
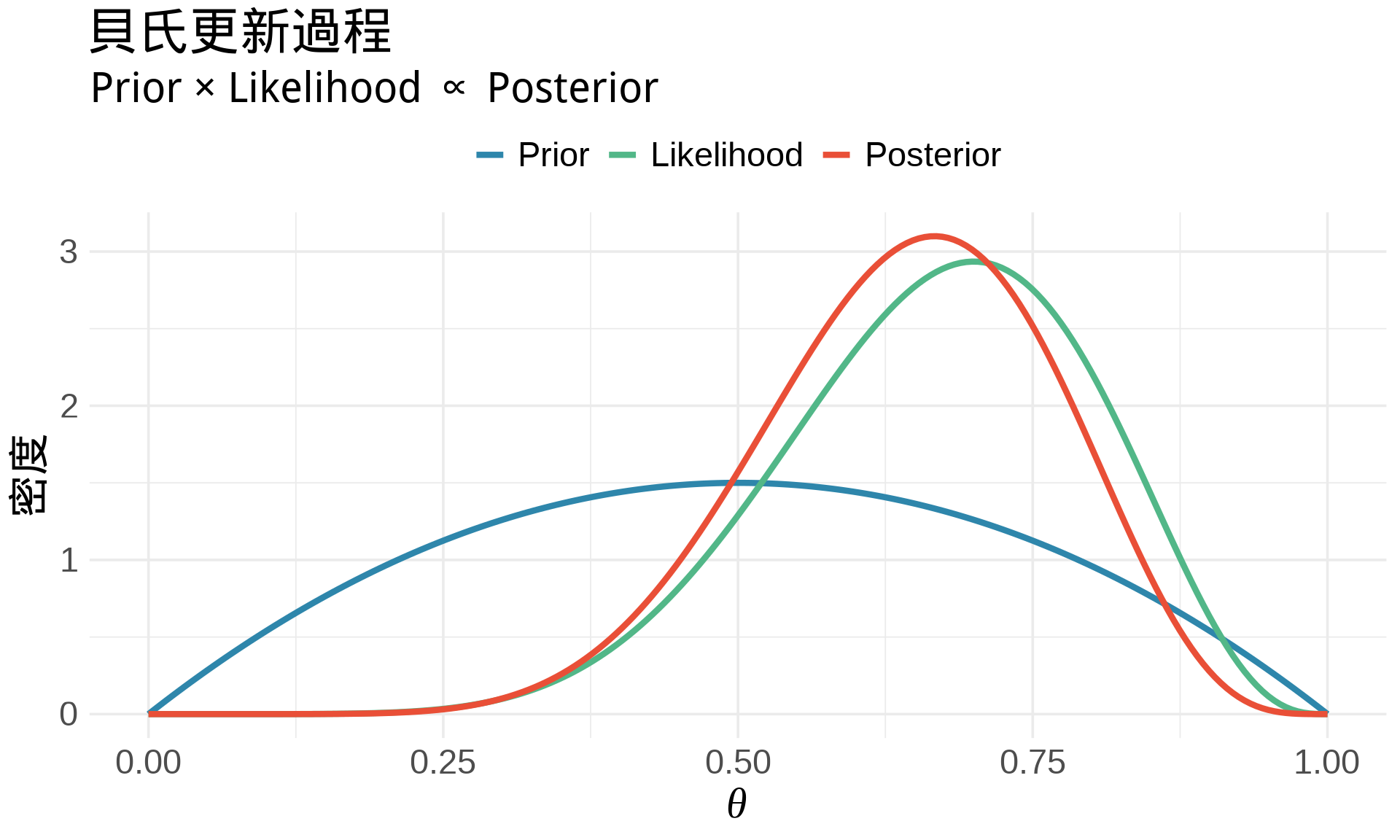
### 範例:Beta-Binomial 模型
**設定** [@mcelreath2020statistical]:
- Prior: $\theta \sim \text{Beta}(\alpha, \beta)$
- Likelihood: $X | \theta \sim \text{Binomial}(n, \theta)$
- Posterior: $\theta | X \sim \text{Beta}(\alpha + X, \beta + n - X)$
```{r}
#| label: fig-bayesian-updating
#| fig-cap: "貝氏更新:Prior → Posterior"
# 參數設定
alpha_prior <- 2
beta_prior <- 2
n <- 10
x <- 7 # 觀察到 10 次中成功 7 次
# Prior
theta <- seq(0, 1, length.out = 200)
prior <- dbeta(theta, alpha_prior, beta_prior)
# Likelihood(標準化)
likelihood <- dbeta(theta, x + 1, n - x + 1)
# Posterior
alpha_post <- alpha_prior + x
beta_post <- beta_prior + n - x
posterior <- dbeta(theta, alpha_post, beta_post)
# 合併資料
data <- data.frame(
theta = rep(theta, 3),
density = c(prior, likelihood, posterior),
type = rep(c("Prior", "Likelihood", "Posterior"), each = 200)
)
data$type <- factor(data$type, levels = c("Prior", "Likelihood", "Posterior"))
ggplot(data, aes(theta, density, color = type)) +
geom_line(linewidth = 1.5) +
scale_color_manual(values = c("#2E86AB", "#52B788", "#E94F37"),
name = NULL) +
labs(
title = "貝氏更新過程",
subtitle = "Prior × Likelihood ∝ Posterior",
x = expression(theta),
y = "密度"
) +
theme_minimal(base_size = 14) +
theme(legend.position = "top")
cat("Prior: Beta(", alpha_prior, ",", beta_prior, ")\n")
cat("觀察到: 10 次中成功 7 次\n")
cat("Posterior: Beta(", alpha_post, ",", beta_post, ")\n\n")
cat("後驗期望值 =", alpha_post / (alpha_post + beta_post), "\n")
cat("後驗眾數 =", (alpha_post - 1) / (alpha_post + beta_post - 2), "\n")
```
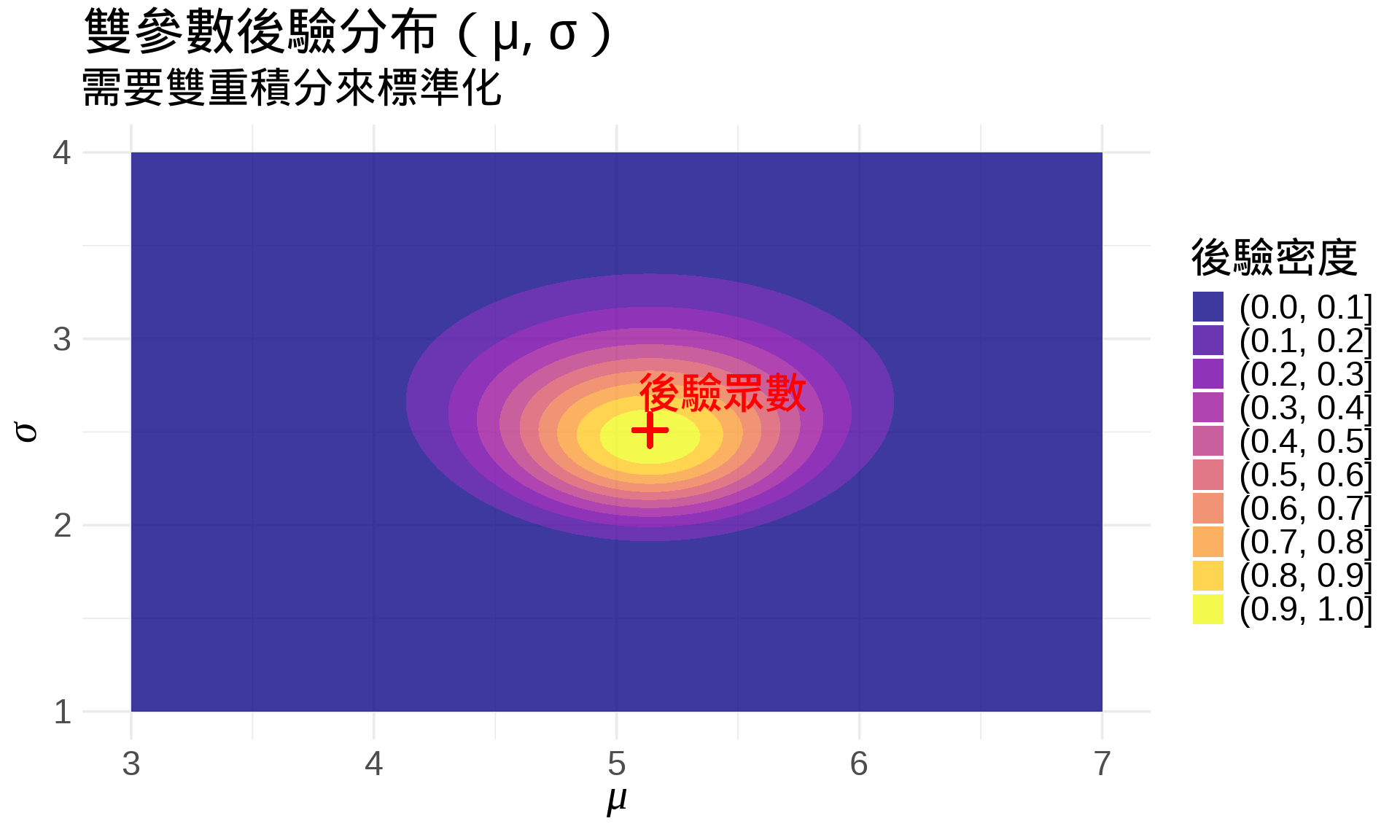
### 多參數貝氏推論
當有多個參數時,需要**多重積分**:
$$p(\theta_1, \theta_2 | \text{data}) = \frac{p(\text{data} | \theta_1, \theta_2) \cdot p(\theta_1, \theta_2)}{\iint p(\text{data} | \theta_1, \theta_2) \cdot p(\theta_1, \theta_2) \, d\theta_1 \, d\theta_2}$$
```{r}
#| label: fig-bivariate-posterior
#| fig-cap: "雙參數的後驗分布"
# 模擬常態分布的後驗(已知精確解)
set.seed(42)
data_sim <- rnorm(30, mean = 5, sd = 2)
# 後驗(簡化版,假設 known prior)
n <- length(data_sim)
xbar <- mean(data_sim)
s2 <- var(data_sim)
# 網格
mu_seq <- seq(3, 7, length.out = 100)
sigma_seq <- seq(1, 4, length.out = 100)
grid <- expand.grid(mu = mu_seq, sigma = sigma_seq)
# 計算對數後驗(正比於 log-likelihood,忽略常數項)
grid$log_post <- sapply(1:nrow(grid), function(i) {
mu <- grid$mu[i]
sigma <- grid$sigma[i]
sum(dnorm(data_sim, mean = mu, sd = sigma, log = TRUE))
})
# 轉換到機率尺度(標準化)
grid$post <- exp(grid$log_post - max(grid$log_post))
ggplot(grid, aes(mu, sigma, z = post)) +
geom_contour_filled(alpha = 0.8) +
geom_point(aes(x = xbar, y = sqrt(s2)),
color = "red", size = 4, shape = 3, stroke = 2) +
annotate("text", x = xbar + 0.3, y = sqrt(s2) + 0.2,
label = "後驗眾數", color = "red", fontface = "bold") +
scale_fill_viridis_d(option = "plasma", name = "後驗密度") +
labs(
title = "雙參數後驗分布(μ, σ)",
subtitle = "需要雙重積分來標準化",
x = expression(mu),
y = expression(sigma)
) +
theme_minimal(base_size = 14)
```
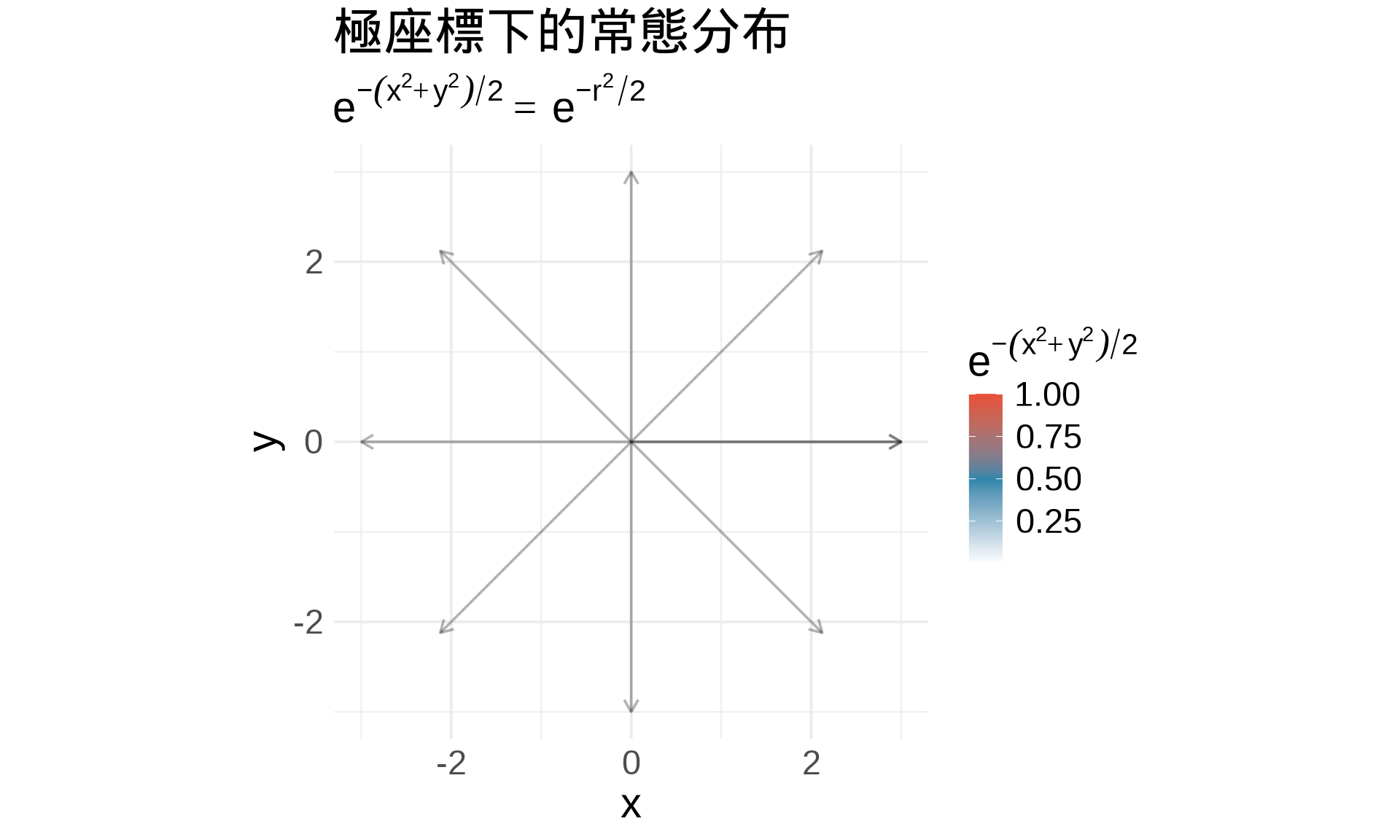
## 積分技巧:極座標轉換
### 為什麼需要極座標?
有些積分在**直角座標**很難算,但在**極座標**很簡單。
**極座標轉換**:
$$x = r\cos\theta, \quad y = r\sin\theta$$
$$dx \, dy = r \, dr \, d\theta$$
### 範例:證明常態分布積分 = 1
標準常態 PDF:
$$f(x) = \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}}$$
我們要證明:
$$\int_{-\infty}^{\infty} \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}} \, dx = 1$$
**技巧**:用雙重積分 + 極座標
$$I = \int_{-\infty}^{\infty} e^{-\frac{x^2}{2}} \, dx$$
$$I^2 = \left(\int_{-\infty}^{\infty} e^{-\frac{x^2}{2}} \, dx\right) \left(\int_{-\infty}^{\infty} e^{-\frac{y^2}{2}} \, dy\right)$$
$$I^2 = \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} e^{-\frac{x^2 + y^2}{2}} \, dx \, dy$$
**轉極座標**($x^2 + y^2 = r^2$):
$$I^2 = \int_0^{2\pi} \int_0^{\infty} e^{-\frac{r^2}{2}} \cdot r \, dr \, d\theta$$
$$= 2\pi \int_0^{\infty} r e^{-\frac{r^2}{2}} \, dr = 2\pi \left[-e^{-\frac{r^2}{2}}\right]_0^{\infty} = 2\pi$$
所以 $I = \sqrt{2\pi}$,因此:
$$\int_{-\infty}^{\infty} \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}} \, dx = 1 \quad \checkmark$$
```{r}
#| label: fig-polar-coordinates
#| fig-cap: "極座標轉換的視覺化"
# 建立極座標網格
r <- seq(0, 3, length.out = 50)
theta <- seq(0, 2*pi, length.out = 100)
grid <- expand.grid(r = r, theta = theta)
grid$x <- grid$r * cos(grid$theta)
grid$y <- grid$r * sin(grid$theta)
grid$density <- exp(-(grid$x^2 + grid$y^2) / 2)
ggplot(grid, aes(x, y, fill = density)) +
geom_tile() +
scale_fill_gradient2(low = "white", mid = "#2E86AB", high = "#E94F37",
midpoint = 0.5, name = expression(e^{-(x^2+y^2)/2})) +
coord_equal() +
geom_spoke(data = data.frame(theta = seq(0, 2*pi, by = pi/4)),
aes(x = 0, y = 0, angle = theta, radius = 3),
inherit.aes = FALSE,
color = "black", alpha = 0.3, arrow = arrow(length = unit(0.1, "inches"))) +
labs(
title = "極座標下的常態分布",
subtitle = expression(e^{-(x^2+y^2)/2} == e^{-r^2/2}),
x = "x", y = "y"
) +
theme_minimal(base_size = 14)
```
## 練習題
### 觀念題
1. 用自己的話解釋:雙重積分代表什麼?跟單重積分有什麼不同?
::: {.callout-tip collapse="true" title="參考答案"}
單重積分代表「曲線下的面積」(2D),而雙重積分代表「曲面下的體積」(3D)。單重積分對一個變數積分,雙重積分對兩個變數分別積分。在統計上,單重積分用於計算單一隨機變數的機率,雙重積分則用於計算兩個隨機變數的聯合機率。
:::
2. 什麼情況下積分順序可以交換?為什麼這很重要?
::: {.callout-tip collapse="true" title="參考答案"}
根據 Fubini's Theorem,當函數在矩形區域上連續時,積分順序可以交換。這很重要因為有些積分在某個順序下很難計算,但換個順序可能變得簡單許多。在統計應用中,這讓我們可以靈活選擇計算邊際分布或期望值的方式。
:::
3. 邊際分布與聯合分布的關係是什麼?用積分表示。
::: {.callout-tip collapse="true" title="參考答案"}
邊際分布是將聯合分布「積分掉」另一個變數得到的。數學上:$f_X(x) = \int_{-\infty}^{\infty} f(x, y) \, dy$ 和 $f_Y(y) = \int_{-\infty}^{\infty} f(x, y) \, dx$。這代表當我們不關心另一個變數的值時,對所有可能值積分後得到的單一變數分布。
:::
4. 為什麼貝氏統計需要用到積分?
::: {.callout-tip collapse="true" title="參考答案"}
貝氏統計需要計算邊際概似 (marginal likelihood) 來標準化後驗分布:$p(\text{data}) = \int p(\text{data} | \theta) \cdot p(\theta) \, d\theta$。這個積分確保後驗分布的總機率為 1。在多參數情況下,還需要多重積分來處理參數的聯合分布。
:::
### 計算題
5. 計算以下雙重積分:
a. $\int_0^1 \int_0^2 (3x + 2y) \, dy \, dx$
b. $\int_0^{\pi} \int_0^{\pi} \sin(x) \cos(y) \, dx \, dy$
::: {.callout-tip collapse="true" title="參考答案"}
a. 先對 $y$ 積分:$\int_0^2 (3x + 2y) dy = [3xy + y^2]_0^2 = 6x + 4$。再對 $x$ 積分:$\int_0^1 (6x + 4) dx = [3x^2 + 4x]_0^1 = 7$。
b. 利用 $\sin(x)\cos(y)$ 可分離:$\int_0^{\pi} \sin(x) dx \cdot \int_0^{\pi} \cos(y) dy = [-\cos(x)]_0^{\pi} \cdot [\sin(y)]_0^{\pi} = 2 \cdot 0 = 0$。
:::
6. 給定聯合 PDF:
$$f(x, y) = \begin{cases} 2 & 0 \le x \le 1, 0 \le y \le x \\ 0 & \text{otherwise} \end{cases}$$
a. 驗證這是合法的 PDF(積分 = 1)
b. 計算 $P(X + Y < 1)$
c. 求邊際分布 $f_X(x)$ 和 $f_Y(y)$
::: {.callout-tip collapse="true" title="參考答案"}
a. $\int_0^1 \int_0^x 2 \, dy \, dx = \int_0^1 2x \, dx = [x^2]_0^1 = 1$ ✓
b. 在三角形區域內,$x + y < 1$ 的部分需要分段:當 $0 \le x \le 0.5$ 時 $y$ 範圍是 $[0, x]$;當 $0.5 < x \le 1$ 時 $y$ 範圍是 $[0, 1-x]$。計算得 $P(X + Y < 1) = 0.125$(如本章範例)。
c. $f_X(x) = \int_0^x 2 \, dy = 2x$ (for $0 \le x \le 1$);$f_Y(y) = \int_y^1 2 \, dx = 2(1-y)$ (for $0 \le y \le 1$)。
:::
### R 操作題
7. 用 R 的數值積分驗證標準常態分布的積分 = 1:
```r
library(stats)
# 計算 ∫ φ(x) dx from -∞ to ∞
result <- integrate(dnorm, -Inf, Inf)
result$value # 應該 ≈ 1
```
::: {.callout-tip collapse="true" title="參考答案"}
執行上述程式碼會得到 `result$value` 非常接近 1(通常是 1.000000,誤差在數值積分的容許範圍內)。`integrate()` 函數使用自適應數值積分方法,在 `-Inf` 到 `Inf` 的範圍內準確計算定積分。這驗證了標準常態 PDF 滿足機率密度函數的基本性質。
:::
8. 繪製雙變量常態分布($\rho = 0.6$)的 3D 圖和邊際分布。
::: {.callout-tip collapse="true" title="參考答案"}
可參考本章「邊際分布」章節的程式碼範例,將相關係數改為 0.6:`Sigma <- matrix(c(1, 0.6, 0.6, 1), 2, 2)`。使用 `plotly` 繪製 3D 曲面圖,或使用 `ggplot2` 的 `geom_contour_filled()` 繪製等高線圖。邊際分布可透過 `dmvnorm()` 配合 `gridExtra` 套件組合顯示。
:::
### 統計連結題
9. 解釋為什麼「計算期望值」在多變量情況下需要用到雙重積分。
::: {.callout-tip collapse="true" title="參考答案"}
期望值是「加權平均」的概念,權重是機率密度。在多變量情況下,函數 $g(X, Y)$ 的期望值需要對所有可能的 $(x, y)$ 組合計算:$E[g(X, Y)] = \iint g(x, y) \cdot f(x, y) \, dx \, dy$。這是二維空間的加權平均,因此需要雙重積分來涵蓋整個定義域。
:::
10. 在貝氏統計中,為什麼計算 $p(\text{data})$ 需要積分?這個積分在實務上好算嗎?
::: {.callout-tip collapse="true" title="參考答案"}
邊際概似 $p(\text{data})$ 是「對所有可能的參數值積分」:$p(\text{data}) = \int p(\text{data} | \theta) p(\theta) \, d\theta$。這確保後驗分布是合法的機率分布(總和為 1)。實務上,這個積分通常很難計算,尤其在高維參數空間。因此常用共軛先驗(有解析解)或 MCMC 等數值方法來避免直接計算這個積分。
:::
## 本章重點整理 {.unnumbered}
✅ **雙重積分**:$\iint f(x, y) \, dx \, dy$ 代表曲面下的體積
✅ **逐次積分**:雙重積分可拆成兩次單重積分,先內層再外層
✅ **積分順序**:在矩形區域上,連續函數的積分順序可交換(Fubini's Theorem)
✅ **聯合機率**:$\iint f(x, y) \, dx \, dy = 1$(總機率)
✅ **邊際分布**:$f_X(x) = \int f(x, y) \, dy$(積分掉另一個變數)
✅ **期望值計算**:$E[g(X, Y)] = \iint g(x, y) \cdot f(x, y) \, dx \, dy$
✅ **貝氏統計**:後驗分布的標準化需要積分 $p(\text{data}) = \int p(\text{data} | \theta) p(\theta) \, d\theta$
✅ **極座標技巧**:某些積分(如證明常態分布積分 = 1)在極座標下更簡單
✅ **核心思想**:多重積分是統計學處理多變量問題的數學基礎,從聯合分布到貝氏推論都需要它